Archive
C++ deprecates some operations on volatile objects
Programming do-gooders sometimes fall into the trap of thinking that banning the use of a problematic language construct removes the possibility of the problems associated with that construct’s usage construct from occurring. The do-gooders overlook the fact that developers use language constructs because they solve a coding need, and that banning usage does not make the coding need go away. If a particular usage is banned, then developers have to come up with an alternative to handle their coding need. The alternative selected may have just as many, or more, problems associated with its use as the original usage.
The C++ committee has fallen into this do-gooder trap by deprecating the use of some unary operators (i.e., ++ and --) and compound assignment operators (e.g., += and &=) on objects declared with the volatile type-specifier. The new wording appears in the 2020 version of the C++ Standard; see sections 7.6.1.5, 7.6.2.2, 7.6.19, and 9.6.
Listing a construct as being deprecated gives notice that it might be removed in a future revision of the standard (languages committees tend to accumulate deprecated constructs and rarely actually remove a construct; breaking existing code is very unpopular).
What might be problematic about objects declared with the volatile type-specifier?
By declaring an object with the volatile type-specifier a developer is giving notice that its value can change through unknown mechanisms at any time. For instance, an array may be mapped to the memory location where the incoming bytes from a communications port are stored, or the members of a struct may represent the various status and data information relating to some connected hardware device.
The presence of volatile in an object’s declaration requires that the compiler not optimise away assignments or accesses to said object (because such assignments or accesses can have effects unknown to the compiler).
volatile int k = 0; int i = k, // value of k not guaranteed to be 0 j = k; // value of k may have changed from that assigned to i if (i != j) printf("The value of k changed from %d to %d\n", i, j); |
volatile int k = 0; int i = k, // value of k not guaranteed to be 0 j = k; // value of k may have changed from that assigned to i if (i != j) printf("The value of k changed from %d to %d\n", i, j);
If, at some point in the future, developers cannot rely on code such as k+=3; being supported by the compiler, what are they to do?
Both the C and C++ Standards state:
“The behavior of an expression of the form E1 op = E2 is equivalent to E1 = E1 op E2 except that E1 is evaluated only once.”
So the code k=k+3; cannot be relied upon to have the same effect as k+=3;.
One solution, which does not make use of any deprecated language constructs, is:
volatile int k; int temp; /* ... */ temp=k; temp+=3; k=temp; |
volatile int k; int temp; /* ... */ temp=k; temp+=3; k=temp;
In what world is the above code less problematic than writing k+=3;?
I understand that in the C++ world there are templates, operator overloading, and various other constructs that can make it difficult to predict how many times an object might be accessed. The solution is to specify the appropriate behavior for volatile objects in these situations. Simply deprecating them for some operators is all cost for no benefit.
We can all agree that the use of volatile has costs and benefits. What is WG21’s (the ISO C++ Committee) cost/benefit analysis for deprecating this usage?
The WG21 proposal P1152, “Deprecating volatile”, claims that it “… preserves the useful parts of volatile, and removes the dubious / already broken ones.”
The proposal is essentially a hatchet job, with initial sections written in the style of the heroic fantasy novel The Name of the Wind, where “…kinds of magic are taught in the university as academic disciplines and have daily-life applications…”; cut-and-pasting of text from WG14 (ISO C committee) documents and C++17 adds bulk. Various issues unrelated to the deprecated constructs are discussed, and it looks like more thought is needed in some of these areas.
Section 3.3, “When is volatile useful?”, sets the tone. The first four paragraphs enumerate what volatile is not useful, before the fifth paragraph admits that “volatile is nonetheless a useful concept to have …” (without listing any reasons for this claim).
How did this deprecation get accepted into the 2020 C++ Standard?
The proposal appeared in October 2018, rather late in the development timeline of a standard published in 2020; were committee members punch drunk by this stage, and willing to wave through what appears to be a minor issue? The document contains 1,662 pages of close text, and deprecation is only giving notice of something that might happen in the future.
Soon after the 2020 Standard was published, the pushback started. Proposal P2327, “De-deprecating volatile compound operations”, noted: “deprecation was not received too well in the embedded community as volatile is commonly used”. However, the authors don’t think that ditching the entire proposal is the solution, instead they propose to just de-deprecate the bitwise compound assignments (i.e., |=, &=, and ^=).
The P2327 proposal contains some construct usage numbers, obtained by grep’ing the headers of three embedded SDKs. Unsurprisingly, there were lots of bitwise compound assignments (all in macros setting various flags).
I used Coccinelle to detect actual operations on volatile objects in the Silabs Gecko SDK C source (one of the SDKs measured in the proposal; semgrep handles C and C++, but does not yet fully handle volatile). The following table shows the number of occurrences of each kind of language construct on a volatile object (code and data):
Construct Occurrences
V++ 83
V-- 5
++V 9
--V 2
bit assign 174
arith assign 27 |
Construct Occurrences V++ 83 V-- 5 ++V 9 --V 2 bit assign 174 arith assign 27
Will the deprecated volatile usage appear in C++23? Probably, purely because the deadline for change has passed. Given WG21’s stated objective of a 3-year iteration, the debate will have to wait for work on to start on C++26.
The increment and decrement deprecation remains. In response to National Body comments on balloting of the draft C++23 document, it was “resolved to un-deprecate all volatile compound assignments.” Thanks to Jonathan Wakely for the correction.
A signature for the “embeddedness” of source code and developers?
Patterns in the use of source code can tell us a lot about the people who wrote the code, the characteristics of the hardware it runs on and what the application is all about.
Often the pattern of usage needs a lot of work to understand and many remain completely baffling, but every now and again the forces driving a pattern leap off the page. One such pattern is visible in the plot below; data courtesy of Jacob Engblom and the cbook data is from my C book (assuming you know something about the nitty gritty of embedded software development). It shows the percentage of functions defined to have a given number of parameters:
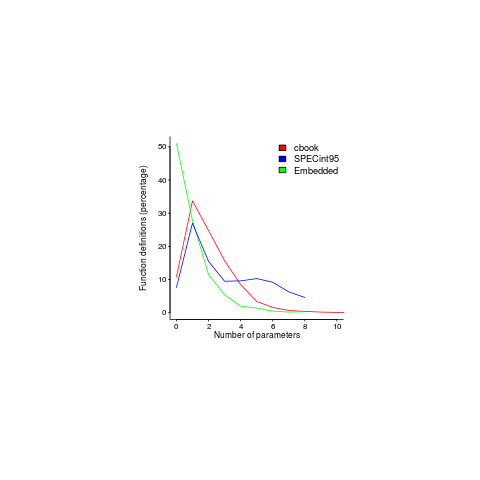
Embedded software has to run in very constrained environments. The hardware is often mass produced and saving a penny per device can add up to big savings, so the cheapest processor is chosen and populated with the smallest possible memory; developers have to work with what they are given. Power consumption may be down below one watt, so clock speeds are closer to 1 MHz than 1 GHz.
Parameter passing is a relatively expensive operation and there are major savings, relatively speaking, to be had by using global variables. Experienced embedded developers know this and this plot is telling us that they are acting on this knowledge.
The following are two ways of interpreting the embedded data (I cannot think of any others that make sense):
- the time/resource critical functions use globals rather than parameters and all the other functions are written more or less the same as in a non-embedded environment. In statistical terms this behavior is described by a zero-inflated model,
- there is pressure on the developer to reduce the number of parameters in all function definitions.
This data contains counts, so a Poisson distribution is the obvious candidate for our model.
My attempts to fit a zero-inflated model failed miserably (code+data). A basic Poisson distribution fitted everything reasonably well (let’s ignore that tiresome bump in the blue line); plus signs are the predictions made from each fitted model.
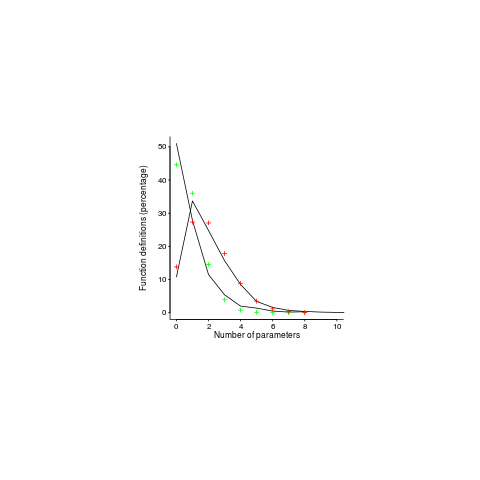
For desktop developers, the distribution of function definitions having a given number of parameters follows a Poisson distribution with a λ of 2, while for embedded developers λ is 0.8.
What about values of λ between 0.8 and 2; perhaps the λ of a project’s, or developer’s, code parameter count can be used as an indicator of ’embeddedness’?
What is needed to parameter count data from a range of 4-bit, 8-bit and 16-bit systems and measurements of developers who have been working in the field for, say, 4, 8, 16 years. Please let me know.
The data is from a Masters thesis written in 1999, is it still relevant today? Have modern companies become kinder to developers and stopped making their life so hard by saving pennies when building mass produced products; are modern low-power devices being used so values can be passed via parameters rather than via globals, or are they being used for applications where even less power is available?
One difference from 20 years ago is that embedded devices are more mainstream, easier to get hold of and sales opportunities abound. This availability creates an environment where developers with a desktop development mentality (which developers new to embedded always seem to have had) don’t get to learn about the overheads of parameter passing.
Have compilers gotten better at reducing the function parameter overhead? The most obvious optimization is inlining a function at the point of call. If the function is only called once, this works fine, with multiple calls the generated code can get larger (one of the things we are trying to avoid). I don’t have any reliable data on modern compiler performance int his area, but then I have not looked hard. Pointers to benchmarks welcome.
Does embedded software have any other signatures that differentiate it from desktop software (other than the obvious one of specifying address in definitions of global variables)? Suggestions welcome.
Type compatibility the hard way
When writing in assembly language it is possible to operate on a sequence of bits as if it were an unsigned integer one moment and a floating-point number the next; it is the developer’s responsibility to ensure that a given sequence of bits is operated on in a consistent manner. The concept of type was initially introduced into computer languages to provide information to compilers, enabling them to generate the appropriate instructions for values having the specified type and where necessary to convert values from the representation used by one type to the representation used by a different type. At this early stage language designers tended to keep things simple and to think in terms of what made sense at the machine representation level when deciding which type conversions to permit (PL/1 was a notable exception and the convolutions that occurred to perform some type conversions are legendary).
It took around 10 years for high level languages to evolve to the point where developers had the ability to create their own named types; Pascal being an early, very well known and stand out example. Once developers could create their own types it became necessary to come up with general rules specifying when a compiler must treat two different types as compatible (i.e., be required to generate code to support some set of operations between variables having these two different types).
Most language designers chose the simple option; a type is compatible with another type if it has the same name (scoping/namespace/lookup rules effectively meant that “same name” was effectively the same as “same definition”). This simple option generally included various exceptions for the arithmetic types; developers did not like having to insert explicit casts for what they considered to be obvious conversions (languages such as Ada/CHILL provided a mechanism for developers to specify that a newly defined arithmetic type really was a completely new type that was not compatible with any other arithmetic type, an explicit cast could change this).
One of the few languages which took a non-simple approach to type compatibility was CHILL, a language for which I once spent over a year writing the semantics phase of a compiler. CHILL uses what is known as structural compatibility, i.e., essentially two types are compatible if they have the same layout in memory (the language definition actually uses the terms similar and equivalent rather than compatible and uses mode rather than type, here I will follow modern general terminology). This has obvious advantages when there is a need to overlay types used in different parts of a program onto the same location in storage (note, no requirements on the fields being the same). CHILL definitions look like a mixture of C and Pascal, unless you know PL/1 they can look odd to the uninitiated (I think I’ve got them right, my CHILL is very rusty), T_1 and T_2 are compatible:
T_1 = struct ( T_2 = struct ( f1 :int; f3 :int; f2 :int; f4 :int; ); ); |
T_1 = struct ( T_2 = struct ( f1 :int; f3 :int; f2 :int; f4 :int; ); );
Structural compatibility enables the creation some rather unusual compatible types, such as the following three types all being pair-wise compatible (the keyword ref is use to specify pointer types):
T_3 = struct ( T_4 = struct ( T_5 = struct ( f1 :int; f4 :int; f7 :int; f2 :ref T_3; f5 :ref T_4; f8 :ref T_5; f3 :ref T_4; f6 :ref T_3; f9 :ref T_5; ); ); ); |
T_3 = struct ( T_4 = struct ( T_5 = struct ( f1 :int; f4 :int; f7 :int; f2 :ref T_3; f5 :ref T_4; f8 :ref T_5; f3 :ref T_4; f6 :ref T_3; f9 :ref T_5; ); ); );
Because types can be recursive it is possible for the compatibility checking code in the compiler to end up having to type check the type it is currently checking. The solution adopted by many CHILL compilers (not that there were ever many) was to associate an is_currently_being_checked flag with every type’s symbol table entry, if during compatibility checking this flag has value TRUE for both types then they are both compatible otherwise the flag is set to TRUE for both types and checking continues (all flags are set to FALSE at the end of compatibility checking).
To check T_3 and T_4 In the above code set the is_currently_being_checked flag to TRUE and iterate over the fields in each record. The first field pair have the same type, the second field pair are pointers to types we are already checking and therefore compatible, as are the third field pair, so the types are compatible. Checking T_3 and T_5 requires a second iteration through T_5 because of the pointer to T_4 which does not yet have its is_currently_being_checked flag set.
Yours truely discovered that one flag was not sufficient to do fully correct compatibility checking. It is necessary to maintain a stack of locations (e.g., the structure field or procedure parameter where compatibility checking has to recurse to check a user defined type) in the two types being compared in order to detect that some types were not compatible. In the following example (involving pointer to procedure types; which is longer than I remember the actual instance I first discovered being, but I had to create it again from vague memories and my CHILL expertise has faded; suggestions welcome) types A and B would be considered compatible using the is_currently_being_checked flag approach because by the time the last parameter is checked both symbol table flags have been set. You can see by inspection that types X and Y are not compatible (they have a different number of parameters to start with). Looking at the stack of previous compatibility checks for A/B would show that no X/Y compatibility check had yet been made and one would be needed for the third parameter (which would fail):
A = proc(X, Y, X); B = proc(C, proc(A, int), Y); C = proc(E); D = proc(A); E = proc(proc(X, proc(A, int), X)); X = proc(D); Y = proc(A, int); |
A = proc(X, Y, X); B = proc(C, proc(A, int), Y); C = proc(E); D = proc(A); E = proc(proc(X, proc(A, int), X)); X = proc(D); Y = proc(A, int);
The potential for complexity created by the use of structural compatibility is one reason why its use is rare. While it is possible to rationalize that CHILL was targeted at embedded telecommunication systems containing lots of code where memory costs can be significant, I suspect that those involved had a hardware mentality and a poor grasp of practical software engineering issues.
Incidentally, the design of the llvm type checking system relies on using an equality test to check for type equality. While this decision will increase the difficulty of integrating languages that use structural type compatibility into llvm, these languages are probably sufficiently rare that it is much more cost effective to make it simple to implement the more common languages.
Where did type compatibility go next? Well, over the last 20 years the juggernaut of object oriented design has pretty much excluded sophisticated non-OO type systems from mainstream languages (e.g., C++ and Java), but that is a topic for another article.
Compiler writing in the next decade
What will be the big issues in compiler writing in the next decade? Compilers sit between languages and hardware, with the hardware side usually providing the economic incentive.
Before we set off to follow the money, what about the side that developers prefer to talk about. The last decade has not seen any convergence to a very small number of commonly used languages, if anything there seems to have been a divergence with more languages in widespread use. I will not attempt to predict whether there will be a new (in the sense of previously limited to a few research projects) concept that is widely integrated and used in many languages (i.e., the integrating of object-oriented features into languages in the 90s).
Where is hardware going?
- Moore’s law stops being followed. Moore’s law is an economic one that has a number of technical consequences (e.g., less power consumed and until recently increasing clock rates). Will the x86 architecture evolution dramatically slow down once processor manufacturers are no longer able to cram more transistors onto the same amount of chip real estate? Perhaps processor designers will start looking to compiler writers to suggest functionality that could be made use of by compilers to generate more optimal code. To date, my experience of processor designers is that they look to Moore’s law to get a ‘free’ performance boost.
There are a number of things a compiler code tell the processor, such as when a read or write to a cache line is the last one that will occur for a long time (enabling that line to be moved to the top of the reuse list).
- Not plugged into the mains. When I made a living writing optimizers, the only two optimizations choices were code size and performance. There are a surprising number of functional areas in which a compiler, given processor support, can potentially generate code that consumes less power. More on this issue in a later post.
- More than one processor. Figuring out how to distribute a program across multiple, loosely coupled, processors remains a difficult research topic. If anybody ever comes up with a solution to this problem, it might make more commercial sense for them to keep it secret, selling a compiling service rather than selling compilers.
- Application Specific Instruction-set Processors. Most processors in embedded systems only ever run a single program. The idea of each program being executed on a processor optimized to its requirements sounds seductive. At the moment the economics are such that it is cheaper to take an existing, very low cost, processor and shoe-horn the application onto it. If the economics change, the compiler used for each processor is likely to be automatically generated.
Enough of the hardware, this site is supposed to be about code:
- New implementation techniques. These include GLR parsing and genetic algorithms to improve the generated code quality. The general availability of development machines containing more than 4G of memory will make it worthwhile for compiler writers to implement more whole program optimizations (which are currently being hemmed in by storage limits)
- gcc will continue its rise to world domination. The main force at work here is not the quality of gcc, but the disappearance of the competition. Compiler writing is not a big bucks business, and compiler companies are regularly bought up by much larger hardware outfits looking to gain some edge. A few years go by, plans change, the compiler group are not making enough profit to warrant the time being spent on them by upper management, and they are closed down. One less compiler vendor and a bunch of developers are forced to migrate to another compiler, which may or may not be gcc.
- Figuring out what the developer meant to write based on what they actually wrote, and some mental model of software developers, is my own research interest. This is somewhat leading edge stuff, in other words, nothing major has been achieved so far. Knowledge of developer intent looks like it will open the door to whole classes of new optimization techniques.
volatile handling sometimes overly volatile
The contents of some storage locations, used by a program, might be modified outside of the control of that program, e.g., a real-time clock or the input port of a communications device. In some cases writing to particular storage locations has an external effect, e.g., a sequence of bits is sent down a communications channel. This kind of behavior commonly occurs in embedded systems
C and C++ support the existence of variables that have been mapped to such storage locations through the use of the volatile type qualifier.
volatile long flag; volatile time_t timer; struct { int f1 : 2; volatile int f2 : 2; int f3 : 3; } x; |
volatile long flag; volatile time_t timer; struct { int f1 : 2; volatile int f2 : 2; int f3 : 3; } x;
When a variable is declared using volatile compilers must assume that its value can change in ways unknown to the compiler and that storing values into such a variable can have external effects. Consequently almost all optimizations involving such variables are off limits. Idioms such as timer = timer; are used to reset or refresh timers and are not dead code.
Volatile is a bit of an inconvenience for writers of code optimizers, requiring them to add checks to make sure the expression or statement they want to attempt to optimize does not contain a volatile qualified variable. In many environments the semantics of volatile are not applicable, which means that bugs in optimizers have a much smaller chance of being detected than faults in other language constructs.
There have been a number of research projects investigating the use of the const qualifier, but as far as I know only one that has investigated volatile. The ‘volatile’ project found that all of the compilers tested generated incorrect code for some of the tests. License agreements prevented the researchers giving details for some compilers. One interesting observation for gcc was that the number of volatile related faults increased with successive compiler releases; it looks like additional optimizations were being implemented and these were not checking for variables being volatile qualified.
One practical output from the project was a compiler stress tester targeting volatile qualified variables. The code generated by stress testers often causes compilers to crash and hang and the researchers reported the same experience with this tool.
There is one sentence in the C Standard whose overly broad wording is sometimes a source of uncertainty: What constitutes an access to an object that has volatile-qualified type is implementation-defined. This sentence applies in two cases: datatypes containing lots of bytes and bit-fields.
To save space/money/time/power some processors access storage a byte, or half-word, at a time. This means that, for instance, an access to a 32-bit storage location may occur as two separate 16-bit operations; from the volatile perspective does that constitute two accesses?
Most processors do not contain instructions capable of loading/storing a specified sequence of bits from a byte. This means that accesses to bit-fields involve one or more bytes being loaded and the appropriate bits extracted. In the definition of x above an access to field f1 is likely to result in field f2 (and f3) being accessed; from the volatile perspective does that constitute two accesses?
Unfortunately it is very difficult to obtain large quantities of source code for programs aimed at the embedded systems market. This means that it is not possible to obtain reliable information on common usage patterns of volatile variables. If anybody knows of any such code base please let me know.
Recent Posts
Tags
Archives
- June 2026
- May 2026
- April 2026
- March 2026
- February 2026
- January 2026
- December 2025
- November 2025
- October 2025
- September 2025
- August 2025
- July 2025
- June 2025
- May 2025
- April 2025
- March 2025
- February 2025
- January 2025
- December 2024
- November 2024
- October 2024
- September 2024
- August 2024
- July 2024
- June 2024
- May 2024
- April 2024
- March 2024
- February 2024
- January 2024
- December 2023
- November 2023
- October 2023
- September 2023
- August 2023
- July 2023
- June 2023
- May 2023
- April 2023
- March 2023
- February 2023
- January 2023
- December 2022
- November 2022
- October 2022
- September 2022
- August 2022
- July 2022
- June 2022
- May 2022
- April 2022
- March 2022
- February 2022
- January 2022
- December 2021
- November 2021
- October 2021
- September 2021
- August 2021
- July 2021
- June 2021
- May 2021
- April 2021
- March 2021
- February 2021
- January 2021
- December 2020
- November 2020
- October 2020
- September 2020
- August 2020
- July 2020
- June 2020
- May 2020
- April 2020
- March 2020
- February 2020
- January 2020
- December 2019
- November 2019
- October 2019
- September 2019
- August 2019
- July 2019
- June 2019
- May 2019
- April 2019
- March 2019
- February 2019
- January 2019
- December 2018
- November 2018
- October 2018
- September 2018
- August 2018
- July 2018
- June 2018
- May 2018
- April 2018
- March 2018
- February 2018
- January 2018
- December 2017
- November 2017
- October 2017
- September 2017
- August 2017
- July 2017
- June 2017
- May 2017
- April 2017
- March 2017
- February 2017
- January 2017
- December 2016
- November 2016
- October 2016
- September 2016
- August 2016
- July 2016
- June 2016
- May 2016
- April 2016
- March 2016
- February 2016
- January 2016
- December 2015
- November 2015
- October 2015
- September 2015
- August 2015
- July 2015
- June 2015
- May 2015
- April 2015
- March 2015
- February 2015
- January 2015
- December 2014
- November 2014
- October 2014
- September 2014
- August 2014
- July 2014
- June 2014
- May 2014
- April 2014
- March 2014
- February 2014
- January 2014
- December 2013
- November 2013
- October 2013
- September 2013
- August 2013
- July 2013
- June 2013
- May 2013
- April 2013
- March 2013
- February 2013
- January 2013
- December 2012
- November 2012
- October 2012
- September 2012
- August 2012
- July 2012
- June 2012
- May 2012
- April 2012
- March 2012
- February 2012
- January 2012
- December 2011
- November 2011
- October 2011
- September 2011
- August 2011
- July 2011
- June 2011
- May 2011
- April 2011
- March 2011
- February 2011
- January 2011
- December 2010
- November 2010
- October 2010
- September 2010
- August 2010
- July 2010
- June 2010
- May 2010
- April 2010
- March 2010
- February 2010
- January 2010
- December 2009
- November 2009
- October 2009
- September 2009
- August 2009
- July 2009
- June 2009
- May 2009
- April 2009
- March 2009
- February 2009
- January 2009
- December 2008
Recent Comments