Archive
Ecology as a model for the software world
Changing two words in the Wikipedia description of Ecology gives “… the study of the relationships between software systems, including humans, and their physical environment”; where physical environment might be taken to include the hardware on which software runs and the hardware whose behavior it controls.
What do ecologists study? Wikipedia lists the following main areas; everything after the first sentence, in each bullet point, is my wording:
- Life processes, antifragility, interactions, and adaptations.
Software system life processes include its initial creation, devops, end-user training, and the sales and marketing process.
While antifragility is much talked about, it is something of a niche research topic. Those involved in the implementations of safety-critical systems seem to be the only people willing to invest the money needed to attempt to build antifragile software. Is N-version programming the poster child for antifragile system software?
Interaction with a widely used software system will have an influence on the path taken by cultures within associated microdomains. Users adapt their behavior to the affordance offered by a software system.
A successful software system (and even unsuccessful ones) will exist in multiple forms, i.e., there will be a product line. Software variability and product lines is an active research area.
- The movement of materials and energy through living communities.
Is money the primary unit of energy in software ecosystems? Developer time is needed to create software, which may be paid for or donated for free. Supporting a software system, or rather supporting the needs of the users of the software is often motivated by a salary, although a few do provide limited free support.
What is the energy that users of software provide? Money sits at the root; user attention sells product.
- The successional development of ecosystems (“… succession is the process of change in the species structure of an ecological community over time.”)
Before the Internet, monthly computing magazines used to run features on the changing landscape of the computer world. These days, we have blogs/podcasts telling us about the latest product release/update. The Ecosystems chapter of my software engineering book has sections on evolution and lifespan, but the material is sparse.
Over the longer term, this issue is the subject studied by historians of computing.
Moore’s law is probably the most famous computing example of succession.
- Cooperation, competition, and predation within and between species.
These issues are primarily discussed by those interested in the business side of software. Developers like to brag about how their language/editor/operating system/etc is better than the rest, but there is no substance to the discussion.
Governments have an interest in encouraging effective competition, and have enacted various antitrust laws.
- The abundance, biomass, and distribution of organisms in the context of the environment.
These are the issues where marketing departments invest in trying to shift the distribution in their company’s favour, and venture capitalists spend their time trying to spot an opportunity (and there is the clickbait of language popularity articles).
The abundance of tools/products, in an ecosystem, does not appear to deter people creating new variants (suggesting that perhaps ambition or dreams are the unit of energy for software ecosystems).
- Patterns of biodiversity and its effect on ecosystem processes.
Various kinds of diversity are important for biological systems, e.g., the mutual dependencies between different species in a food chain, and genetic diversity as a resource that provides a mechanism for species to adapt to changes in their environment.
It’s currently fashionable to be in favour of diversity. Diversity is so popular in ecology that a 2003 review listed 24 metrics for calculating it. I’m sure there are more now.
Diversity is not necessarily desired in software systems, e.g., the runtime behavior of source code should not depend on the compiler used (there are invariably edge cases where it does), and users want different editor command to be consistently similar.
Open source has helped to reduce diversity for some applications (by reducing the sales volume of a myriad of commercial offerings). However, the availability of source code significantly reduces the cost/time needed to create close variants. The 5,000+ different cryptocurrencies suggest that the associated software is diverse, but the rapid evolution of this ecosystem has driven developers to base their code on the source used to implement earlier currencies.
Governments encourage competitive commercial ecosystems because competition discourages companies charging high prices for their products, just because they can. Being competitive requires having products that differ from other vendors in a desirable way, which generates diversity.
Estimating the number of distinct faults in a program
In an earlier post I gave two reasons why most fault prediction research is a waste of time: 1) it ignores the usage (e.g., more heavily used software is likely to have more reported faults than rarely used software), and 2) the data in public bug repositories contains lots of noise (i.e., lots of cleaning needs to be done before any reliable analysis can done).
Around a year ago I found out about a third reason why most estimates of number of faults remaining are nonsense; not enough signal in the data. Date/time of first discovery of a distinct fault does not contain enough information to distinguish between possible exponential order models (technical details; practically all models are derived from the exponential family of probability distributions); controlling for usage and cleaning the data is not enough. Having spent a lot of time, over the years, collecting exactly this kind of information, I was very annoyed.
The information required, to have any chance of making a reliable prediction about the likely total number of distinct faults, is a count of all fault experiences, i.e., multiple instances of the same fault need to be recorded.
The correct techniques to use are based on work that dates back to Turing’s work breaking the Enigma codes; people have probably heard of Good-Turing smoothing, but the slightly later work of Good and Toulmin is applicable here. The person whose name appears on nearly all the major (and many minor) papers on population estimation theory (in ecology) is Anne Chao.
The Chao1 model (as it is generally known) is based on a count of the number of distinct faults that occur once and twice (the Chao2 model applies when presence/absence information is available from independent sites, e.g., individuals reporting problems during a code review). The estimated lower bound on the number of distinct items in a closed population is:

and its standard deviation is:
![S_{sd-est}={f_1}/{f_2}k sqrt{f_2(0.5/{k}+{f_1}/{f_2} [1+0.25 {f_1}/{f_2}])}](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_971.5_e69346120e72f31d04a47c9fcf64c4dd.png "S_{sd-est}={f_1}/{f_2}k sqrt{f_2(0.5/{k}+{f_1}/{f_2} [1+0.25 {f_1}/{f_2}])}")
where:  is the estimated number of distinct faults,
is the estimated number of distinct faults,  the observed number of distinct faults,
the observed number of distinct faults,  the total number of faults,
the total number of faults,  the number of distinct faults that occurred once,
the number of distinct faults that occurred once,  the number of distinct faults that occurred twice,
the number of distinct faults that occurred twice,  .
.
A later improved model, known as iChoa1, includes counts of distinct faults occurring three and four times.
Where can clean fault experience data, where the number of inputs have been controlled, be obtained? Fuzzing has become very popular during the last few years and many of the people doing this work have kept detailed data that is sometimes available for download (other times an email is required).
Kaminsky, Cecchetti and Eddington ran a very interesting fuzzing study, where they fuzzed three versions of Microsoft Office (plus various Open Source tools) and made their data available.
The faults of interest in this study were those that caused the program to crash. The plot below (code+data) shows the expected growth in the number of previously unseen faults in Microsoft Office 2003, 2007 and 2010, along with 95% confidence intervals; the x-axis is the number of faults experienced, the y-axis the number of distinct faults.
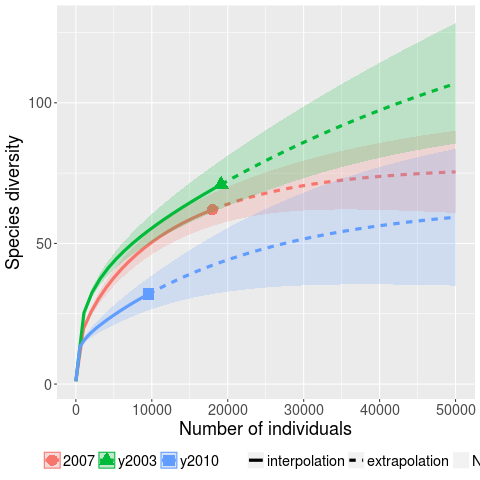
The take-away point: if you are analyzing reported faults, the information needed to build models is contained in the number of times each distinct fault occurred.
Recent Comments