Archive
Join a crowdsourced search for software engineering data
Software engineering data, that can be made publicly available, is very rare; most people don’t attempt to collect data, and when data is collected, people rarely make any attempt to hang onto the data they do collect.
Having just one person actively searching for software engineering data (i.e., me) restricts potential sources of data to be English speaking and to a subset of development ecosystems.
This post is my attempt to start a crowdsourced campaign to search for software engineering data.
Finding data is about finding the people who have the data and have the authority to make it available (no hacking into websites).
Who might have software engineering data?
In the past, I have emailed chief technology officers at companies with less than 100 employees (larger companies have lawyers who introduce serious amounts of friction into releasing company data), and this last week I have been targeting Agile coaches. For my evidence-based software engineering book I mostly emailed the authors of data driven papers.
A lot of software is developed in India, China, South America, Russia, and Europe; unless these developers are active in the English-speaking world, I don’t see them.
If you work in one of these regions, you can help locate data by finding people who might have software engineering data.
If you want to be actively involved, you can email possible sources directly, alternatively I can email them.
If you want to be actively involved in the data analysis, you can work on the analysis yourself, or we can do it together, or I am happy to do it.
In the English-speaking development ecosystems, my connection to the various embedded ecosystems is limited. The embedded ecosystems are huge, there must be software data waiting to be found. If you are active within an embedded ecosystem, you can help locate data by finding people who might have software engineering data.
The email template I use for emailing people is below. The introduction is intended to create a connection with their interests, followed by a brief summary of my interest, examples of previous analysis, and the link to my book to show the depth of my interest.
By all means cut and paste this template, or create one that you feel is likely to work better in your environment. If you have a blog or Twitter feed, then tell them about it and why you think that evidence-based software engineering is important.
Be responsible and only email people who appear to have an interest in applying data analysis to software engineering. Don’t spam entire development groups, but pick the person most likely to be in a position to give a positive response.
This is a search for gold nuggets, and the response rate will be very low; a 10% rate of reply, saying sorry not data, would be better than what I get. I don’t have enough data to be able to calculate a percentage, but a ballpark figure is that 1% of emails might result in data.
My experience is that people are very unsure that anything useful will be found in their data. My response has been that I am always willing to have a look.
I always promise to anonymize their data, and not release it until they have agreed; but working on the assumption that the intent is to make a public release.
I treat the search as a background task, taking months to locate and email, say, 100-people considered worth sending a targeted email. My experience is that I come up with a search idea or encounter a blog post that suggests a line of enquiry, that may result in sending half-a-dozen emails. The following week, if I’m lucky, the same thing might happen again (perhaps with fewer emails). It’s a slow process.
If people want to keep a record of ideas tried, the evidence-based software engineering Slack channel could do with some activity.
Hello, A personalized introduction, such as: I have been reading your blog posts on XXX, your tweets about YYY, your youtube video on ZZZ. My interest is in trying to figure out the human issues driving the software process. Here are two detailed analysis of Agile estimation data: https://arxiv.org/abs/1901.01621 and https://arxiv.org/abs/2106.03679 My book Evidence-based Software Engineering discusses what is currently known about software engineering, based on an analysis of all the publicly available data. pdf+code+all data freely available here: http://knosof.co.uk/ESEUR/ and I'm always on the lookout for more software data. This email is a fishing request for software engineering data. I offer a free analysis of software data, provided an anonymised version of the data can be made public.
Fishing for software data
During 2021 I sent around 100 emails whose first line started something like: “I have been reading your interesting blog post…”, followed by some background information, and then a request for software engineering data. Sometimes the request for data was specific (e.g., the data associated with the blog post), and sometimes it was a general request for any data they might have.
So far, these 100 email requests have produced one two datasets. Around 80% failed to elicit a reply, compared to a 32% no reply for authors of published papers. Perhaps they don’t have any data, and don’t think a reply is worth the trouble. Perhaps they have some data, but it would be a hassle to get into a shippable state (I like this idea because it means that at least some people have data). Or perhaps they don’t understand why anybody would be interested in data and must be an odd-ball, and not somebody they want to engage with (I may well be odd, but I don’t bite :-).
Some of those who reply, that they don’t have any data, tell me that they don’t understand why I might be interested in data. Over my entire professional career, in many other contexts, I have often encountered surprise that data driven problem-solving increases the likelihood of reaching a workable solution. The seat of the pants approach to problem-solving is endemic within software engineering.
Others ask what kind of data I am interested in. My reply is that I am interested in human software engineering data, pointing out that lots of Open source is readily available, but that data relating to the human factors underpinning software development is much harder to find. I point them at my evidence-based book for examples of human centric software data.
In business, my experience is that people sometimes get in touch years after hearing me speak, or reading something I wrote, to talk about possible work. I am optimistic that the same will happen through my requests for data, i.e., somebody I emailed will encounter some data and think of me 🙂
What is different about 2021 is that I have been more willing to fail, and not just asking for data when I encounter somebody who obviously has data. That is to say, my expectation threshold for asking is lower than previous years, i.e., I am more willing to spend a few minutes crafting a targeted email on what appear to be tenuous cases (based on past experience).
In 2022 I plan to be even more active, in particular, by giving talks and attending lots of meetups (London based). If your company is looking for somebody to give an in-person lunchtime talk, feel free to contact me about possible topics (I’m always after feedback on my analysis of existing data, and will take a 10-second appeal for more data).
Software data is not commonly available because most people don’t collect data, and when data is collected, no thought is given to hanging onto it. At the moment, I don’t think it is possible to incentivize people to collect data (i.e., no saleable benefit to offset the cost of collecting it), but once collected the cost of hanging onto data is peanuts. So as well as asking for data, I also plan to sell the idea of hanging onto any data that is collected.
Fishing tips for software data welcome.
Learning useful stuff from the Reliability chapter of my book
What useful, practical things might professional software developers learn from my evidence-based software engineering book?
Once the book is officially released I need to have good answers to this question (saying: “Well, I decided to collect all the publicly available software engineering data and say something about it”, is not going to motivate people to read the book).
This week I checked the reliability chapter; what useful things did I learn (combined with everything I learned during all the other weeks spent working on this chapter)?
A casual reader skimming the chapter would conclude that little was known about software reliability, and they would be right (I already knew this, but I learned that we know even less than I thought was known), and many researchers continue to dig in unproductive holes.
A reader with some familiarity with reliability research would be surprised to see that some ‘major’ topics are not discussed.
The train wreck that is machine learning has been avoided (not forgetting that the data used is mostly worthless), mutation testing gets mentioned because of some interesting data (the underlying problem is that mutation testing assumes that coding mistakes are local to one line, but in practice coding mistakes often involve multiple lines), and the theory discussions don’t mention non-homogeneous Poisson process as the basis for software fault models (because this process is not capable of solving the questions asked).
What did I learn? My highlights include:
- Anne Choa‘s work on population estimation. The takeaway from this work is that if people want to estimate the number of remaining fault experiences, based on previous experienced faults, then every occurrence (i.e., not just the first) of a fault needs to be counted,
- Phyllis Nagel and Janet Dunham’s top read work on software testing,
- the variability in the numeric percentage that people assign to probability terms (e.g., almost all, likely, unlikely) is much wider than I would have thought,
- the impact of the distribution of input values on fault experiences may be detectable,
- really a lowlight, but there is a lot less publicly available data than I had expected (for the other chapters there was more data than I had expected).
The last decade has seen fuzzing grow to dominate the headlines around software reliability and testing, and provide data for people who write evidence-based books. I don’t have much of a feel for how widely used it is in industry, but it is a very useful tool for reliability researchers.
Readers might have a completely different learning experience from reading the reliability chapter. What useful things did you learn from the reliability chapter?
The dark-age of software engineering research: some evidence
Looking back, the 1970s appear to be a golden age of software engineering research, with the following decades being the dark ages (i.e., vanity research promoted by ego and bluster), from which we are slowly emerging (a rough timeline).
Lots of evidence-based software engineering research was done in the 1970s, relative to the number of papers published, and I have previously written about the quantity of research done at Rome and the rise of ego and bluster after its fall (Air Force officers studying for a Master’s degree publish as much software engineering data as software engineering academics combined during the 1970s and the next two decades).
What is the evidence for a software engineering research dark ages, starting in the 1980s?
One indicator is the extent to which ancient books are still venerated, and the wisdom of the ancients is still regularly cited.
I claim that my evidence-based software engineering book contains all the useful publicly available software engineering data. The plot below shows the number of papers cited (green) and data available (red), per year; with fitted exponential regression models, and a piecewise regression fit to the data (blue) (code+data).
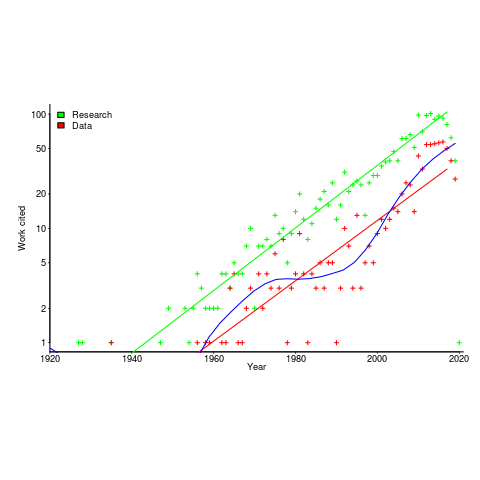
The citations+date include works that are not written by people involved in software engineering research, e.g., psychology, economics and ecology. For the time being I’m assuming that these non-software engineering researchers contribute a fixed percentage per year (the BibTeX file is available if anybody wants to do the break-down)
The two straight line fits are roughly parallel, and show an exponential growth over the years.
The piecewise regression (blue, loess was used) shows that the rate of growth in research data leveled-off in the late 1970s and only started to pick up again in the 1990s.
The dip in counts during the last few years is likely to be the result of me not having yet located all the recent empirical research.
Increase your citation count, send me your data!
I regularly email people asking for a copy of the data used in a paper they wrote. In around 32% of cases I don’t get any reply, around 12% promise to send the data when they are less busy (a few say they are just too busy) and every now and again people ask why I want the data.
After 6-12 months, I email again saying that I am still interested in their data; a few have replied with apologies and the data.
I need a new strategy to motivate people to spend some time tracking down their data and sending it to me; there are now over 200 data-sets possibly lost forever!
I think those motivated by the greater good will have already responded. It is time to appeal to baser instincts, e.g., self-interest. The currency of academic life is paper citations, which translate into status in the community, which translate into greater likelihood of grant proposals being accepted (i.e., money to do what they want to do).
Sending data gets researchers one citation in my book (I am ruthless about not citing a paper if I don’t get any data).
My current argument is that once their data is publicly available (and advertised in my book) lots of other researchers will use it and more citation to their work will follow; they also get an exclusive, I only use one data-set for each topic (actually data is hard to get hold of, so the exclusivity offer is spin).
To back up my advertising claims I point out that influential people are writing about my book and it’s all over social media. If you want me to add you to the list of influential people, send me a link to what you have written (I have no shame).
If you write about my book, please talk about the data and that researchers who make their data public are the only ones who deserve funding and may citations rain down on them.
That is the carrot approach, how can I apply some stick to motivate people?
I could point out that if they don’t send me their data their work is doomed to obscurity, because I will use somebody else’s (skipping over the minor detail of data being hard to find). Research has found that people are less willing to share their data if the strength of the evidence is weak; calling out somebody like that is do-or-die.
If you write about my book, please talk about the data and point out that researchers who don’t make their data public have something to hide and should not be funded.
Since the start of 2017, researchers in the UK receiving government research grants are required to archive their data and make it available. This is good for future researchers, but not a lot of use for me now.
What do readers think? Ideas and suggestions welcome.
DACS: Software Life Cycle Empirical/Experience Database
Economic data relating to software development is very very hard to find. Companies just don’t want to reveal how much they spent/charged to writing a software system. This kind of data is invariably confidential.
I’m currently working on the Economics chapter of my book on Empirical Software Engineering and the data is somewhat thin.
I’m hoping one of my readers can help out with a copy of the “DACS data”.
DACS (The Data & Analysis Center for Software), a US DOC information analysis center, used to sell copies of their Software Life Cycle Empirical/Experience Database for $50. The most interesting data set was the DACS Productivity Dataset containing effort and schedule data on over 500 software projects.
DACS was merged into CSIAC (Cyber Security & information systems Information Analysis Center; not sure if I capitalized the appropriate information) and the data availability is no more.
If you have a copy of this data, or know somebody who does, please send me a copy.
The person who put the data together, Richard Nelson, no longer works for the government, has a consulting firm registered in Orlando, and is an officer of the NASA Alumni League Florida Chapter. All the obvious searches for an email address fail, and I suspect that a retirement is being enjoyed.
Of course I am always happy to hear about any software engineering data that you think I don’t have.
Success: Software engineering data is starting to become very dull
A few years ago it was unusual for the author(s) of a paper in software engineering to make their data public (and on top of that it was rare to encounter a paper that actually made use of empirical data). The situation now is that I am having trouble keeping up with all the papers that include a link to downloadable data. Part of the problem is that I will pay a lot more attention to papers that come with data, having lived through a long famine I have not yet adjusted to the greater abundance. I’m sure that journal editors and referees are in the same boat and are being lured by accompanying data to accept paper for publication that they would otherwise have rejected.
This growing quantity of empirical software engineering data means we can now start thinking about what data is useful to have and what data is not so useful. Data is useful if it highlights a pattern of behavior that can be used to help reduce the resources needed to create/maintain software.
To get a handle on estimating data usefulness we need a model of research in software engineering. While many have used Physics as the model for software engineering research (i.e., a few simple universal laws that apply everywhere), I think Biology is a much better fit.
Software is written in different habitats environments (e.g., small teams, large teams) and targets different habitats environments (e.g., embedded, desktop, mobile, supercomputer) using different techniques and driven by different predators/prey market forces (e.g., release first/quickly, be reliable). Yes there are common drivers, just as the living things studied by biologists share a common need to eat, sleep and reproduce.
Like biology, the bulk of software engineering research is about the study of niche topics, with some small percentage of researchers trying to build theories that tie everything together at one level or another to create bigger pictures.
This model of software engineering research means estimating the usefulness of data probably requires some knowledge of the niche to which it applies. It also means that a particular data set might not be useful yet because it needs to be combined with other data, that does not yet exist (perhaps it was collected first because it was easier to do).
So in a space of a few years most software engineering data has gone from being very interesting (because it is rare) to being very dull (because it is harder to stand out in a crowd).
Ways of obtaining empirical data in software engineering
For as long as I can remember I have been a collector of empirical data. Writing a book that involves analysis of empirical lots of data has added some focus to my previous scatter gun approach. I have been using three methods to obtain data relating to a recently read paper+one other approach:
- Download from researchers website,
- Emailing the author requesting a copy of the data,
- Reverse engineering numbers from the original paper (using tools like WebPlotDigitizer).
- Roll my sleeves up and do the experiment, write the extraction tool or convince a company to make its data available.
A sea change in attitudes to making data available seems to be underway. Until recently it was rare to find a researcher who provided a link for downloading data; in the last 12 months there has been a noticeable increase in the number of researchers making data, associated with a paper, available for download. I hope this increase continues and making data freely available becomes the accepted norm.
I regularly (once or twice a week) email the authors of a paper asking if I can have a copy of their data, typical responses include:
- Yes, here it is,
- Yes, but you cannot share it with anybody else (i.e., everybody has to get it from the original author). I have said “Thanks, but no thanks” in these cases since I make all the data I use freely available for download,
- I no longer have a copy of the data (changed jobs, lost in a computer crash, etc). In one case an established repository at a university lost funding and has gone dark.
- Data is confidential,
- Plan to write more papers based on the data, will release it when done (obtaining good data can be very time consuming and I can appreciate researchers wanting to maximize their return on investment),
- No response.
I have run a few experiments and have been luck enough to obtain data from one company.
When analysing data the most common ‘mistake’ I encounter is researchers failing to get the most out of the data they have. An example of this is two researchers who made some structural changes to the way a Java library worked and then ran a thorough before/after benchmark to investigate the impact; their statistical analysis consisted of reducing the extensive data down to mean+variance and comparing these across before/after (I built a regression model that makes a much stronger case for their claims).
Of course the usual incorrect use of statistical techniques does occur, but I have not spotted anything major. However, one study found: Willingness to Share Research Data Is Related to the Strength of the Evidence and the Quality of Reporting of Statistical Results, based on 49 papers published in two major psychology journals. Since I am concentrating on papers where the data is available I am probably painting an overly rosy picture of not getting things wrong.
As always, if anybody knows of ways of obtaining data that I have not mentioned (e.g., a twitter account to follow) do please let me know.
Recent Comments