Archive
Two failed software development projects in the High Court
When submitting a bid, to be awarded the contract to develop a software system, companies have to provide information on costs and delivery dates. If the costs are significantly underestimated, and/or the delivery dates woefully optimistic, one or more of the companies involved may resort to legal action.
Searching the British and Irish Legal Information Institute‘s Technology and Construction Court Decisions throws up two interesting cases (when searching on “source code”; I have not been able to figure out the patterns in the results that were not returned by their search engine {when I expected some cases to be returned}).
The estimation and implementation activities described in the judgements for these two cases could apply to many software projects, both successful and unsuccessful. Claiming that the system will be ready by the go-live date specified by the customer is an essential component of winning a bid, the huge uncertainties in the likely effort required comes as standard in the software industry environment, and discovering lots of unforeseen work after signing the contract (because the minimum was spent on the bid estimate) is not software specific.
The first case is huge (BSkyB/Sky won the case and EDS had to pay £200+ million): (1) BSkyB Limited (2) Sky Subscribers Services Limited: Claimants – and (1) HP Enterprise Services UK Limited (formerly Electronic Data Systems Limited) (2) Electronic Data systems LLC (Formerly Electronic Data Systems Corporation: Defendants. The amount bid was a lot less than £200 million (paragraph 729 “The total EDS “Sell Price” was £54,195,013 which represented an overall margin of 27% over the EDS Price of £39.4 million.” see paragraph 90 for a breakdown).
What can be learned from the judgement for this case (the letter of Intent was subsequently signed on 9 August 2000, and the High Court decision was handed down on 26 January 2010)?
- If you have not been involved in putting together a bid for a large project, paragraphs 58-92 provides a good description of the kinds of activities involved. Paragraphs 697-755 discuss costing details, and paragraphs 773-804 manpower and timing details,
- if you have never seen a software development contract, paragraphs 93-105 illustrate some of the ways in which delivery/payments milestones are broken down and connected. Paragraph 803 will sound familiar to developers who have worked on large projects: “… I conclude that much of Joe Galloway’s evidence in relation to planning at the bid stage was false and was created to cover up the inadequacies of this aspect of the bidding process in which he took the central role.” The difference here is that the money involved was large enough to make it worthwhile investing in a court case, and Sky obviously believed that they could only be blamed for minor implementation problems,
- don’t have the manager in charge of the project give perjured evidence (paragraph 195 “… Joe Galloway’s credibility was completely destroyed by his perjured evidence over a prolonged period.”). Bringing the law of deceit and negligent misrepresentation into a case can substantially increase/decrease the size of the final bill,
- successfully completing an implementation plan requires people with the necessary skills to do the work, and good people are a scarce resource. Projects fail if they cannot attract and keep the right people; see paragraphs 1262-1267.
A consequence of the judge’s finding of misrepresentation by EDS is a requirement to consider the financial consequences. One item of particular interest is the need to calculate the likely effort and time needed by alternative suppliers to implement the CRM System.
The only way to estimate, with any degree of confidence, the likely cost of implementing the required CRM system is to use a conventional estimation process, i.e., a group of people with the relevant domain knowledge work together for some months to figure out an implementation plan, and then cost it. This approach costs a lot of money, and ties up scarce expertise for long periods of time; is there a cheaper method?
Management at the claimant/defence companies will have appreciated that the original cost estimate is likely to be as good as any, apart from being tainted by the perjury of the lead manager. So they all signed up to using Tasseography, e.g., they get their respective experts to estimate the amount of code that needs to be produce to implement the system, calculate how long it would take to write this code and multiply by the hourly rate for a developer. I would loved to have been a fly on the wall when the respective IT experts, all experienced in provided expert testimony, were briefed. Surely the experts all knew that the ballpark figure was that of the original EDS estimate, and that their job was to come up with a lower/high figure?
What other interpretation could there be for such a bone headed approach to cost estimation?
The EDS expert based his calculation on the debunked COCOMO model (ok, my debunking occurred over six years later, but others have done it much earlier).
The Sky expert based his calculation on the use of function points, i.e., estimation function points rather than lines of code, and then multiply by average cost per function point.
The legal teams point out the flaws in the opposing team’s approach, and the judge does a good job of understanding the issues and reaching a compromise.
There may be interesting points tucked away in the many paragraphs covering various legal issues. I barely skimmed these.
The second case is not as large (the judgement contains a third the number of paragraphs, and the judgement handed down on 19 February 2021 required IBM to pay £13+ million): SCIS GENERAL INSURANCE LIMITED: Claimant – and – IBM UNITED KINGDOM LIMITED: Defendant.
Again there is lots to learn about how projects are planned, estimated and payments/deliveries structured. There are staffing issues; paragraph 104 highlights how the client’s subject matter experts are stuck in their ways, e.g., configuring the new system for how things used to work and not attending workshops to learn about the new way of doing things.
Every IT case needs claimant/defendant experts and their collection of magic spells. The IBM expert calculated that the software contained technical debt to the tune of 4,000 man hours of work (paragraph 154).
If you find any other legal software development cases with the text of the judgement publicly available, please let me know (two other interesting cases with decisions on the British and Irish Legal Information Institute).
Source code discovery, skipping over the legal complications
The 2020 US elections introduced the issue of source code discovery, in legal cases, to a wider audience. People wanted to (and still do) check that the software used to register and count votes works as intended, but the companies who wrote the software wouldn’t make it available and the courts did not compel them to do so.
I was surprised to see that there is even a section on “Transfer of or access to source code” in the EU-UK trade and cooperation agreement, agreed on Christmas Eve.
I have many years of experience in discovering problems in the source code of programs I did not write. This experience derives from my time as a compiler implementer (e.g., a big customer is being held up by a serious issue in their application, and the compiler is being blamed), and as a static analysis tool vendor (e.g., managers want to know about what serious mistakes may exist in the code of their products). In all cases those involved wanted me there, I could talk to some of those involved in developing the code, and there were known problems with the code. In court cases, the defence does not want the prosecution looking at the code, and I assume that all conversations with the people who wrote the code goes via the lawyers. I have intentionally stayed away from this kind of work, so my practical experience of working on legal discovery is zero.
The most common reason companies give for not wanting to make their source code available is that it contains trade-secrets (they can hardly say that it’s because they don’t want any mistakes in the code to be discovered).
What kind of trade-secrets might source code contain? Most code is very dull, and for some programs the only trade-secret is that if you put in the implementation effort, the obvious way of doing things works, i.e., the secret sauce promoted by the marketing department is all smoke and mirrors (I have had senior management, who have probably never seen the code, tell me about the wondrous properties of their code, which I had seen and knew that nothing special was present).
Comments may detail embarrassing facts, aka trade-secrets. Sometimes the code interfaces to a proprietary interface format that the company wants to keep secret, or uses some formula that required a lot of R&D (management gets very upset when told that ‘secret’ formula can be reverse engineered from the executable code).
Why does a legal team want access to source code?
If the purpose is to check specific functionality, then reading the source code is probably the fastest technique. For instance, checking whether a particular set of input values can cause a specific behavior to occur, or tracing through the logic to understand the circumstances under which a particular behavior occurs, or in software patent litigation checking what algorithms or formula are being used (this is where trade-secret claims appear to be valid).
If the purpose is a fishing expedition looking for possible incorrect behaviors, having the source code is probably not that useful. The quantity of source contained in modern applications can be huge, e.g., tens to hundreds of thousands of lines.
In ancient times (i.e., the 1970s and 1980s) programs were short (because most computers had tiny amounts of memory, compared to post-2000), and it was practical to read the source to understand a program. Customer demand for more features, and the fact that greater storage capacity removed the need to spend time reducing code size, means that source code ballooned. The following plot shows the lines of code contained in the collected algorithms of the Transactions on Mathematical Software, the red line is a fitted regression model of the form:  (code+data):
(code+data):
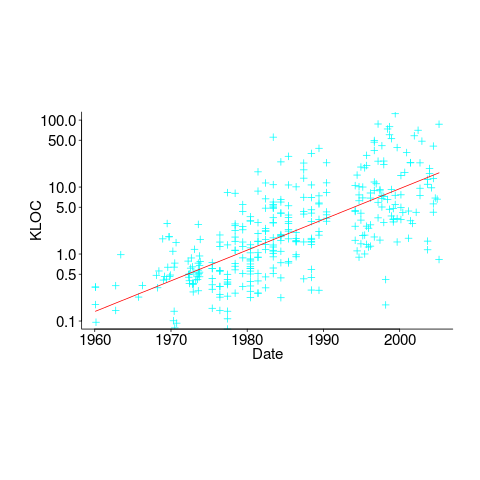
How, by reading the source code, does anybody find mistakes in a 10+ thousand line program? If the program only occasionally misbehaves, finding a coding mistake by reading the source is likely to be very very time-consuming, i.e, months. Work it out yourself: 10K lines of code is around 200 pages. How long would it take you to remember all the details and their interdependencies of a detailed 200-page technical discussion well enough to spot an inconsistency likely to cause a fault experience? And, yes, the source may very well be provided as a printout, or as a pdf on a protected memory stick.
From my limited reading of accounts of software discovery, the time available to study the code may be just days or maybe a week or two.
Reading large quantities of code, to discover possible coding mistakes, are an inefficient use of human time resources. Some form of analysis tool might help. Static analysis tools are one option; these cost money and might not be available for the language or dialect in which the source is written (there are some good tools for C because it has been around so long and is widely used).
Character assassination, or guilt by innuendo is another approach; the code just cannot be trusted to behave in a reasonable manner (this approach is regularly used in the software business). Software metrics are deployed to give the impression that it is likely that mistakes exist, without specifying specific mistakes in the code, e.g., this metric is much higher than is considered reasonable. Where did these reasonable values come from? Someone, somewhere said something, the Moon aligned with Mars and these values became accepted ‘wisdom’ (no, reality is not allowed to intrude; the case is made by arguing from authority). McCabe’s complexity metric is a favorite, and I have written how use of this metric is essentially accounting fraud (I have had emails from several people who are very unhappy about me saying this). Halstead’s metrics are another favorite, and at least Halstead and others at the time did some empirical analysis (the results showed how ineffective the metrics were; the metrics don’t calculate the quantities claimed).
The software development process used to create software is another popular means of character assassination. People seem to take comfort in the idea that software was created using a defined process, and use of ad-hoc methods provides an easy target for ridicule. Some processes work because they include lots of testing, and doing lots of testing will of course improve reliability. I have seen development groups use a process and fail to produce reliable software, and I have seen ad-hoc methods produce reliable software.
From what I can tell, some expert witnesses are chosen for their ability to project an air of authority and having impressive sounding credentials, not for their hands-on ability to dissect code. In other words, just the kind of person needed for a legal strategy based on character assassination, or guilt by innuendo.
What is the most cost-effective way of finding reliability problems in software built from 10k+ lines of code? My money is on fuzz testing, a term that should send shivers down the spine of a defense team. Source code is not required, and the output is a list of real fault experiences. There are a few catches: 1) the software probably to be run in the cloud (perhaps the only cost/time effective way of running the many thousands of tests), and the defense is going to object over licensing issues (they don’t want the code fuzzed), 2) having lots of test harnesses interacting with a central database is likely to be problematic, 3) support for emulating embedded cpus, even commonly used ones like the Z80, is currently poor (this is a rapidly evolving area, so check current status).
Fuzzing can also be used to estimate the numbers of so-far undetected coding mistakes.
EU rules that computer languages cannot be copyrighted
The European Court of Justice has published its decision in SAS v WPL; the title of the press release says it all “The functionality of a computer program and the programming language cannot be protected by copyright”. To summarise the background, World Programming Ltd developed a system that was capable of emulating the input/output behavior of programs written in what the SAS Institute Inc were claiming to be their copyrighted scripting language, along with various file formats.
According to the Court of Justice, “the Court holds that neither the functionality of a computer program nor the programming language and the format of data files used in a computer program in order to exploit certain of its functions constitute a form of expression. Accordingly, they do not enjoy copyright protection.”
This EU ruling is not quiet what it seems. The SAS v WPL case is before the High Court in London and the EU Court of Justice has been asked for advice based on European Law. So the UK dispute has not yet been decided, but given that the UK is signed up to adhere by EU laws people who know about the legal stuff seem to think the High Court in London will follow the EU ruling. Assuming this, then…
This ruling is not just bad news for SAS, it is also bad news for their competitors. Competition is likely to lead to better/cheaper products for users of the SAS language, resulting in less incentive for them to move to an alternative (the R language included; incidentally what exactly are The R Foundation for Statistical Computing claiming copyright over in that notice that pops up when R is started?)
The Oracle vs. Google Java API lawsuit involves similar territory. There are plenty of details over at Groklaw and I’m not going to go there.
This ruling makes it much more likely that behave-alike implementations of more ‘corporate languages’ will be created, at least in Europe. Previously the threat of a lawsuit would have been enough to deter most people, irrespective of whether what they wanted to do was legal or not.
What languages might we see implemented any time soon? The one that immediately springs to mind for me is Mathematica, which is the leader in its field and a fork of Maxima that supported the Mathematica language would move it out of the ghetto. Octave and Matlab are already very close, so no change there.
I imagine there are corporate languages scattered over every conceivable application domain. A lot of these domains will be sufficiently specialized that there is a very low probability of somebody creating an open source implementation; if it looks like there is money to be made it has become more likely that an alternative commercial implementation will be created.
It looks like being a compiler writer is back as flavor of the month again 🙂
Using evolution to reduce competition
The Microsoft purchase of Skype got me thinking back to my time as an advisor to the Monitoring Trustee appointed by the European Commission in the EU/Microsoft competition court case. The Commission wanted to introduce competition into the Windows Work Group server market and it hoped that by requiring Microsoft to license all of the necessary communication protocols companies would produce products that were plug-compatible with Microsoft products. The major flaw in this plan turned out to be economics, we estimated it would cost around £100 million to implement the protocols and making a worthwhile profit on this investment looked decidedly problematic.
Microsoft’s approach to publishing protocol specifications went through three stages: 1) doing everything they could not to do it, 2) following the judgment handed down by the court, 3) actively documenting additional protocols and making all the documents publicly available. Yes, as the documentation process progressed Microsoft started to see the benefits of having English prose documentation (previously the documentation was the source code) but I suspect the switch from (2) to (3) was made possible by the economic analysis that implied there would not be any competition in the server market.
Skype have not made their client/server protocols public, will Microsoft do so? I suspect not because there is no benefit for them to do so. Also I’m sure that Microsoft will want to steer clear of antitrust authorities and will not be making Skype an integral part of Windows’ internal functionality.
What progress has been made in reverse engineering the Skype protocols? There is a community of people trying to figure them out but they have not made the progress that enabled Andrew Tridgell to quickly get something useful up and running that could then evolve into a full blown implementation of a Microsoft protocol.
What lesson can Skype product managers learn from the Microsoft experience of having to make their proprietary protocols available to third parties? I don’t think Microsoft intentionally did any the following:
- Don’t write any English prose documentation; ensure that the source code is the only specification of the protocols. This will make it easier for point 3) to occur,
- proprietary protocols are your friend, even designing ‘better’ alternatives to non-proprietary protocols,
- don’t put too much of a brake on evolution, i.e., allow developers to do what they always want to do which is to make quick fixes to the code and tweak it here and there resulting in a tangle that cannot be simplified. This will significantly drive up third-party costs as they will not be able to create a product handling a useful subset (i.e., they will have to implement everything) and the tangle make sit harder form them to sure that what they have done is correct.
What might be the short term costs of following this strategy? Very good developers are used to learning by reading code (lack of documentation is a fact of life for may of them). Experience has shown that allowing developers to make quick fixes and tweak code often results in difficult to maintain code (ok, so a small group of developers have to be paid above the market rate to ensure access to their code memory). If developers really do dig themselves into a very large hole it is always possible to completely redesign the protocols and provide a very major upgrade (Skype can always reinvent its own protocols, an option not available to third parties which have to follow slavishly behind; this option has always been open to Microsoft with its protocols, i.e., the courts did not place any restrictions on protocol changes).
Where did the £100 million figure come from? The problem of estimating development cost was approached from various angles. The one I used was to estimate the number of requirements at 50,000 (there are 38,158 MUSTs in the first public release of the documents) of which 1,651 occur in the SMB specification for which there is a 450KLOC implementation (i.e., samba source in 2006), giving an estimate of (50000/1651)*450K -> 13.6 MLOC in the final implementation. At £10 per line we get a bit more than £100 million.
Recent Comments