Archive
Early research on economies of scale for computer systems
Before microprocessor cost/performance wiped out (in the early 1990s) other cpu platforms (e.g., mainframes and minis), people argued that computer hardware benefited from economies of scale.
The claimed benefit was more bang for the buck, i.e., more compute for less money.
Checking this claim requires treating pre-microprocessor computer systems and the later microprocessor-based systems as two separate cases, because many of the factors driving costs and performance are very different.
Today’s large microprocessor-based computer systems achieve economies of scale through discounts from bulk purchases and spreading fixed costs across multiple systems. The data is available, and the economic analysis is straight forward.
A lack of reliable data on the costs of designing/building pre-microprocessor computer systems rules out an economic analysis of cost/performance from first principles. The data that was/is available is the cost of computer systems and some indicators of performance (such as instruction timings or benchmarks).
Now, the observed fact that the cost of compute was decreasing over time is unrelated to the claim that the cost of compute decreases as the size of the computer increases.
Assuming a power law relationship between computer cost,  , and size,
, and size,  , at a point in time, we have:
, at a point in time, we have:  , where
, where  is some constant. Economies of scale occur when:
is some constant. Economies of scale occur when: 
In his detailed cost/performance analysis of computers between 1944-1967, Kenneth Knight treated computers launched in the same year as effectively occurring at the same time. He also built a single model, with year included as an explanatory variable, which means the fitted rate of decrease is the same over all years (rather than varying between years).
The plot below uses Knight’s 1953-1961 data, and shows operations per second against seconds per dollar (a confusing combination, but what Knight used), with fitted regression lines for three years using Knight’s model (code and data)
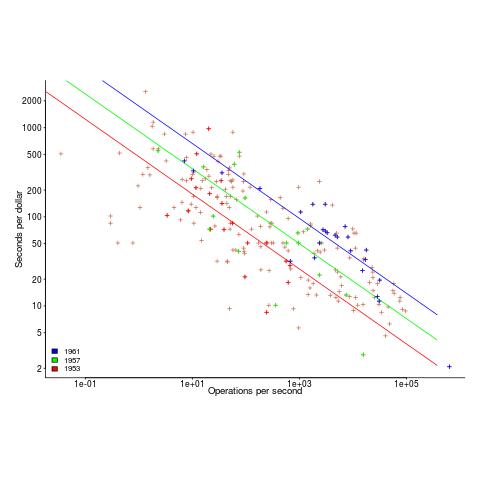
The fitted exponent for this form of x/y axis maps to a value which has , i.e., there are economies of scale.
It so happens that the value of the Knight’s fitted exponent is close to that proposed in a 1953 paper (“High speed arithmetic: The digital computer as a research tool”, no online copy):
It used to cost one cent to do a multiplication on a desk calculator; now it is more like four cents; but with these big machines we can do a million in an hour for $400, and that means twenty-five multiplications for a cent! I believe that there is a fundamental rule, which I modestly call Grosch's law, giving added economy only as the square root of the increase in speed-that is, to do a calculation ten times as cheaply you must do it one hundred times as fast. |
which did indeed become widely known as Grosch’s law.
Having been given a lucky kick-start by Knight (fitted individually, years are not close to Grosch’s law), checking for agreement with Grosch’s law became a focus for later studies. While various papers highlighted problems with the later data analysis (e.g., the regression techniques and sample noise producing mathematical artifacts), Grosch’s law ceased being a thing because mainframes/minicomputers ceased being a thing.
Did mainframe/mincomputers have economies of scale in the years after Knight’s data? It’s difficult to tell, the publicly available data is too sparse to support reliable analysis.
Analysis of when refactoring becomes cost-effective
In a cost/benefit analysis of deciding when to refactor code, which variables are needed to calculate a good enough result?
This analysis compares the excess time-code of future work against the time-cost of refactoring the code. Refactoring is cost-effective when the reduction in future work time is less than the time spent refactoring. The analysis finds a relationship between work/refactoring time-costs and number of future coding sessions.
Linear, or supra-linear case
Let’s assume that the time needed to write new code grows at a linear, or supra-linear rate, as the amount of code increases ( ):
):

where:  is the base time for writing new code on a freshly refactored code base,
is the base time for writing new code on a freshly refactored code base,  is the number of lines of code that have been written since the last refactoring, and
is the number of lines of code that have been written since the last refactoring, and  and
and  are constants to be decided.
are constants to be decided.
The total time spent writing code over  sessions is:
sessions is:
^x}")
If the same number of new lines is added in every coding session,  , and is an integer constant, then the sum has a known closed form, e.g.:
, and is an integer constant, then the sum has a known closed form, e.g.:
x=1, ^1}={n(n+1)}/2L_s") ; x=2,
; x=2, ^2}={n(n+1)(2n+1)}/6{L_s}^2")
Let’s assume that the time taken to refactor the code written after sessions is:
^y")
where:  and
and  are constants to be decided.
are constants to be decided.
The reason for refactoring is to reduce the time-cost of subsequent work; if there are no subsequent coding sessions, there is no economic reason to refactor the code. If we assume that after refactoring, the time taken to write new code is reduced to the base cost, , and that we believe that coding will continue at the same rate for at least another  sessions, then refactoring existing code after sessions is cost-effective when:
sessions, then refactoring existing code after sessions is cost-effective when:
^y < k_1sum{i=n+1}{n+f}{(iL_s)^x}")
assuming that is much smaller than , setting  , and rearranging we get:
, and rearranging we get:

after rearranging we obtain a lower limit on the number of future coding sessions, , that must be completed for refactoring to be cost-effective after session ::

It is expected that  ; the contribution of code size, at the end of every session, in the calculation of and
; the contribution of code size, at the end of every session, in the calculation of and  is equal (i.e.,
is equal (i.e., ^y") ), and the overhead of adding new code is very unlikely to be less than refactoring all the newly written code.
), and the overhead of adding new code is very unlikely to be less than refactoring all the newly written code.
With  ,
,  must be close to zero; otherwise, the likely relatively large value of (e.g., 100+) would produce surprisingly high values of .
must be close to zero; otherwise, the likely relatively large value of (e.g., 100+) would produce surprisingly high values of .
Sublinear case
What if the time overhead of writing new code grows at a sublinear rate, as the amount of code increases?
Various attributes have been found to strongly correlate with the  of lines of code. In this case, the expressions for and become:
of lines of code. In this case, the expressions for and become:

")
and the cost/benefit relationship becomes:
 < k_1sum{i=n+1}{n+f}{log(iL_s)}")
applying Stirling’s approximation and simplifying (see Exact equations for sums at end of post for details) we get:
 < k_1(f(log(n+f)-1)+f log{L_s})")
+log{L_s}-1} < f")
applying the series expansion (for  ):
):  , we get
, we get
 < f")
Discussion
What does this analysis of the cost/benefit relationship show that was not obvious (i.e., the relationship  is obviously true)?
is obviously true)?
What the analysis shows is that when real-world values are plugged into the full equations, all but two factors have a relatively small impact on the result.
A factor not included in the analysis is that source code has a half-life (i.e., code is deleted during development), and the amount of code existing after sessions is likely to be less than the  used in the analysis (see Agile analysis).
used in the analysis (see Agile analysis).
As a project nears completion, the likelihood of there being more coding sessions decreases; there is also the every present possibility that the project is shutdown.
The values of and encode information on the skill of the developer, the difficulty of writing code in the application domain, and other factors.
Exact equations for sums
The equations for the exact sums, for  , are:
, are:
")
+1)")
(2n(n+1)+2fn+f+f^2)")
-zeta(-0.5, f+n+1)") , where
, where  is the Hurwitz zeta function.
is the Hurwitz zeta function.
Sum of a log series: !}/{n!}}+f log{L_s}")
using Stirling’s approximation we get
!)}-log(n!) approx (n+f-0.5)log(n+f)-(n+f)-((n-0.5)log n-n)")
simplifying
!)}-log(n!) approx (n-0.5)log(1+f/n)+f log(n+f)-f")
and assuming that is much smaller than gives
!)}-log(n!) approx f(log(n+f)-1)")
Update
The analysis above assumes that the time contribution of the base rate, , is independent of the changes,  . The following analysis combines these two contributions into a single rate:
. The following analysis combines these two contributions into a single rate:
L)^b}")
where: ,  , , and are positive constants, with
, , and are positive constants, with  , and
, and  .
.
The following is a very good approximation to this sum (thanks to Grok 4.1 beta; chat script):
L})")
where: L")
Increase in defect fixing costs with distance from original mistake
During software development, when a mistake has been made it may be corrected soon after it is made, much later during development, by the customer in a shipped product, or never corrected.
If a mistake is corrected, the cost of correction increases as the ‘distance’ between its creation and detection increases. In a phased development model, the distance might be the number of phases between creation and detection; in a throw it at the wall and see if it sticks development model, the distance might be the number of dependencies on the ‘mistake’ code.
There are people who claim that detecting mistakes earlier will save money. This claim overlooks the cost of detecting mistakes, and in some cases earlier detection is likely to be more expensive (or the distribution of people across phases may rate limit what can be done in any phase). For instance, people might not be willing to read requirements documents, but be willing to try running software; some coding mistakes are only going to be encountered later during integration test, etc.
Folklore claims of orders of magnitude increases in fixing cost, as ‘distance’ increases, have been shown to be hand waving.
I know of two datasets on ‘distance’ between mistake creation and detection. A tiny dataset in Implementation of Fault Slip Through in Design Phase of the Project (containing only counts information; also see figure 6.41), and the CESAW dataset.
The plot below shows the time taken to fix 7,000 reported defects by distance between phases, for CESAW project 615 (code+data). The red lines are fitted regression models of the form  , for minimum fix times of 1, 5 and 10 minutes:
, for minimum fix times of 1, 5 and 10 minutes:
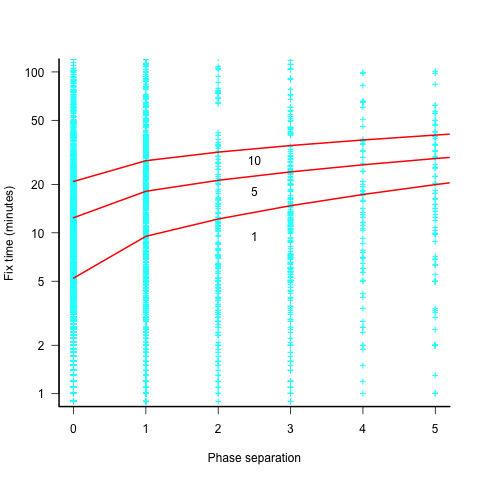
The above plot makes various simplifying assumptions, including: ‘sub-phases’ being associated with a ‘parent’ phase selected by your author, and the distance between all pairs of adjacent phase is the same (in terms of their impact on fix time).
A more sophisticated data model might change the functional form of the fitted regression model, but is unlikely to remove the general upward trend.
There are lots of fix times taking less than five minutes. Project 615 developed safety critical software, and so every detected mistake was recorded; on other projects, small mistakes would probably been fixed without an associated formal record.
I think that, if it were not for the, now discredited, folklore claiming outsized relative costs for fixing reported defects at greater ‘distances’ from the introduction of a mistake, this issue would be a niche topic.
Payback time-frame for research in software engineering
What are the major questions in software engineering that researchers should be trying to answer?
A high level question whose answer is likely to involve life, the universe, and everything is: What is the most cost-effective way to build software systems?
Viewing software engineering research as an attempt to find the answer to a big question mirrors physicists quest for a Grand Unified Theory of how the Universe works.
Physicists have the luxury of studying the Universe at their own convenience, the Universe does not need their input to do a better job.
Software engineering is not like physics. Once a software system has been built, the resources have been invested, and there is no reason to recreate it using a more cost-effective approach (the zero cost of software duplication means that manufacturing cost is the cost of the first version).
Designing and researching new ways of building software systems may be great fun, but the time and money needed to run the realistic experiments needed to evaluate their effectiveness is such that they are unlikely to be run. Searching for more cost-effective software development techniques by paying to run the realistic experiments needed to evaluate them, and waiting for the results to become available, is going to be expensive and time-consuming. A theory is proposed, experiments are run, results are analysed; rinse and repeat until a good-enough cost-effective technique is found. One iteration will take many years, and this iterative process is likely to take many decades.
Very many software systems are being built and maintained, and each of these is an experiment. Data from these ‘experiments’ provides a cost-effective approach to improving existing software engineering practices by studying the existing practices to figure out how they work (or don’t work).
Given the volume of ongoing software development, most of the payback from any research investment is likely to occur in the near future, not decades from now; the evidence shows that source code has a short and lonely existence. Investing for a payback that might occur 30-years from now makes no sense; researchers I talk to often use this time-frame when I ask them about the benefits of their research, i.e., just before they are about to retire. Investing in software engineering research only makes economic sense when it is focused on questions that are expected to start providing payback in, say, 3-5 years.
Who is going to base their research on existing industry practices?
Researching existing practices often involves dealing with people issues, and many researchers in computing departments are not that interested in the people side of software engineering, or rather they are more interested in the computer side.
Algorithm oriented is how I would describe researchers who claim to be studying software engineering. I am frequently told about the potential for huge benefits from the discovery of more efficient algorithms. For many applications, algorithms are now commodities, i.e., they are good enough. Those with a career commitment to studying algorithms have a blinkered view of the likely benefits of their work (most of those I have seen are doing studying incremental improvements, and are very unlikely to make a major break through).
The number of researchers studying what professional developers do, with an aim to improving it, is very small (I am excluding the growing number of fake researchers doing surveys). While I hope there will be a significant growth in numbers, I’m not holding my breadth (at least in the short term; as for the long term, Planck’s experience with quantum mechanics was: “Science advances one funeral at a time”).
The aims of software engineering research
Physics researchers aim to explain the workings of the universe (technically they build models whose behavior mimics that of the universe we can measure), biologists the workings of biological systems, and psychologists the working of the human mind.
What are researchers in software engineering aiming to do?
Talking to academics, the answer is that they aim to do research that can be published in a high impact journal.
What do those involved in commercial software development think software engineering researchers should be aiming to achieve?
Most of the commercial developers I have asked have never thought about the subject; hardly surprising, they have plenty of other issues to think about.
Those who pay for software, rather than create it, want it to be cheaper and delivered faster.
Vendors are under some pressure to reduce costs and deliver sooner. But since its inception, software has been a sellers market, which means the customer pressure does not have the impact it has in other industries.
The very large organizations who pay lots of money for software for their own use (e.g., the U.S. Department of Defence) recognise that research into software production may well save them lots of money, and at one time interesting things were being discovered, but then funding got rerouted to people with an aversion to actual software engineering, i.e., academics.
Cheaper and faster will always be of interest, and will start to become a hot topic in software engineering research once software starts to becoming a buyers market.
Maintaining existing systems continues its growth to dominating what nearly every software developer does. Dependencies on the rest of the software world (e.g., libraries and compilers) is starting to consume a large percentage of maintenance costs. Managers want to know which packages are likely to have a long and stable lifetime, and which are likely to be short-lived. An understanding of the evolution of software ecosystems is a pressing need. This is really cheaper and faster over the long term.
Cheaper and faster (short term for development, long term for maintenance) covers everything.
It’s tempting to list personnel selection, i.e., who is likely to make the best software developer. But why should the process of selecting software developers be any different from the processes used to select people to become doctors, lawyers and other professions? I’m sure that those involved in the various professions would like a magic wand that points to the appropriate people (for some definition of appropriate), this magic wand is no more likely to exist for software developers than any other profession.
What do you think the aims of software engineering research should be?
Self-driving cars, is it safer on the inside or the outside?
The UK Department for Transport: Seeks views on a regulatory framework for the safe testing of self-driving cars on UK roads.
I was driving home one Christmas and saw an obviously drunk man trying to work up the momentum to cross the road. I honked my horn and flashed my lights, he fell backwards into a large puddle on the muddy grass. It is unlikely that a self-driving car would have acted as I did, perhaps the drunk would have stepped out in front of the car when it was too close to brake to a stop before colliding with him.
What should the default behavior of self-driving cars be when somebody steps out in front of them, when breaking while driving in the same direction will result in a collision?
The simplest technical solution is to collide with the pedestrian.
If the road is clear, an improved solution is to include ‘change direction’ to the list of possible actions for the car to take. This could still result in an accident, but one that only damaged the car and not any people.
What if the road is not clear, perhaps there is a large lorry coming towards us and lots of large trees on my side of the road. In this case, I don’t want ‘change direction’ included in the list of possible actions.
What if a couple of school children step in front of my self-driving car and it is not safe for the car to change direction? Does the government require the car software to make a cost/benefit decision about who gets priority in the minimize pain and suffering calculation? I don’t fancy my chances against a couple of school children in that calculation. I can see the government delaying implementation of that feature until self-driving cars become established.
There is a positive benefit to having cars make cost/benefit decisions about life/death/serious injury, it will reduce traffic by encouraging people to share cars (sharing increases the human value of the car contents, making it less likely that they are the ones to suffer).
What about user options. Will I be able to show the car picture of family members and instruct it to give higher priority to them than non-family? The people in the car coming in the opposite direction that I collided with to avoid hitting a family member might be a bit put out that it only happened because I had changed the default collision priorities.
You have until 11:45pm on 19 September 2014 to send the Department for Transport your views.
The government are obviously keen on this idea; they are offering funding “… to towns or cities to develop testing grounds for driverless cars.” Plenty of opportunities for cutting youth unemployment here.
Cloning research needs a new mantra
The obvious answer to software engineering researchers who ask why their findings are not applied within industry is that their findings provide no benefits to industry. Anyone who digs into the published research finds that in fact there is lots of potentially useful stuff in there, the problem is that researchers often take too narrow a perspective.
A good example of a research area that is generally ignored by industry but has potential for widespread benefits is software cloning; that is chunks of source code that are duplicated within the same application (a chunk may be as little as five lines or may be more, and the definition of duplicate varies from exactly the same character sequence, through semantic equivalence to chilling out with a certain percentage of lines being the same {with various definitions for ‘same’}). (This is not about duplication of code in multiple versions of the same product, we all know how nasty that can be to maintain).
Researchers regard cloning as bad, while I suspect many developers are neutral on the subject or even in favor of creating and using duplicate code.
Clone research will be ignored by industry while researchers continue to push the mantra “clones are bad”. It just does not gel with industry’s view.
Developers are under pressure to deliver working software; if they can save time by (legally) making use of existing code then there is an immediate benefit to them and their employer. The researchers’ argument is that clones increase maintenance costs (a fault being fixed in one of the duplicates but not the other(s) is often cited as the killer case for all clones being bad). What developers know is that most code is never maintained (e.g., is is rewritten, or never used again or works fine and does not need to be changed).
Do company’s that own software care about it containing clones? They are generally more interested in meeting deadlines and being first to market. If a product is a success it will be worth paying its maintenance costs; why risk spending extra time/money on creating a beautifully written product when most products don’t well well enough to be worth maintaining? If the software is bespoke, for in-house use or by a client, then increased maintenance costs are good for those involved in writing the software (i.e., they get paid to maintain it).
The new clone research mantra should be that clones have benefits and costs, and the research results help increase benefits and decrease costs. How does this increase/decrease work? You’re the researchers, you tell me.
My own experience with clones is that they do sometimes multiply costs (i.e., work has to be done more than once) but overall their creation and use is very cost effective, as for ‘missed’ fault fixes clones are a small subset of this use case.
I have heard of projects where there has been rampant copying, plus minor modification, of code within the project. If such projects fail then the issue is one of project management and control, with cloning being one of the consequences.
The number of clones usually found in a large software system is surprisingly high; . If you want to check out the clones in your own code CCFinder is well worth a look. The most common use for such tools is plagiarism detection.
Break even ratios for development investment decisions
Developers are constantly being told that it is worth making the effort when writing code to make it maintainable (whatever that might be). Looking at this effort as an investment what kind of return has to be achieved to make it worthwhile?
Short answer: The percentage saving during maintenance has to be twice as great as the percentage investment during development to break even, higher ratio to do better.
The longer answer is below as another draft section from my book Empirical software engineering with R book. As always comments and pointers to more data welcome. R code and data here.
Break even ratios for development investment decisions
Upfront investments are often made during software development with the aim of achieving benefits later (e.g., reduced cost or time). Examples of such investments include spending time planning, designing or commenting the code. The following analysis calculates the benefit that must be achieved by an investment for that investment to break even.
While the analysis uses years as the unit of time it is not unit specific and with suitable scaling months, weeks, hours, etc can be used. Also the unit of development is taken to be a complete software system, but could equally well be a subsystem or even a function written by one person.
Let  be the original development cost and
be the original development cost and  the yearly maintenance costs, we start by keeping things simple and assume is the same for every year of maintenance; the total cost of the system over years is:
the yearly maintenance costs, we start by keeping things simple and assume is the same for every year of maintenance; the total cost of the system over years is:

If we make an investment of  % in reducing future maintenance costs with the expectations of achieving a benefit of %, the total cost becomes:
% in reducing future maintenance costs with the expectations of achieving a benefit of %, the total cost becomes:
 + y*m*(1+i)*(1-b)")
and for the investment to break even the following inequality must hold:
 + y*m*(1+i)*(1-b) < d + y*m")
expanding and simplifying we get:

or:

If the inequality is true the ratio  is the primary contributor to the right-hand-side and must be greater than 1.
is the primary contributor to the right-hand-side and must be greater than 1.
A significant problem with the above analysis is that it does not take into account a major cost factor; many systems are replaced after a surprisingly short period of time. What relationship does the ratio need to have when system survival rate is taken into account?
Let  be the percentage of systems that survive each year, total system cost is now:
be the percentage of systems that survive each year, total system cost is now:

where *(1-b)")
Summing the power series for the maximum of years that any system in a company’s software portfolio survives gives:
}/{1 - s}")
and the break even inequality becomes:
} < {b}/{i} + b")
The development/maintenance ratio is now based on the yearly cost multiplied by a factor that depends on the system survival rate, not the total maintenance cost
If we take >= 5 and a survival rate of less than 60% the inequality simplifies to very close to:

telling us that if the yearly maintenance cost is equal to the development cost (a situation more akin to continuous development than maintenance and seen in 5% of systems in the IBM dataset below) then savings need to be at least twice as great as the investment for that investment to break even. Taking the mean of the IBM dataset and assuming maintenance costs spread equally over the 5 years, a break even investment requires savings to be six times greater than the investment (for a 60% survival rate).
The plot below gives the minimum required saving/investment ratio that must be achieved for various system survival rates (black 0.9, red 0.8, blue 0.7 and green 0.6) and development/yearly maintenance cost ratios; the line bundles are for system lifetimes of 5.5, 6, 6.5, 7 and 7.5 years (ordered top to bottom)
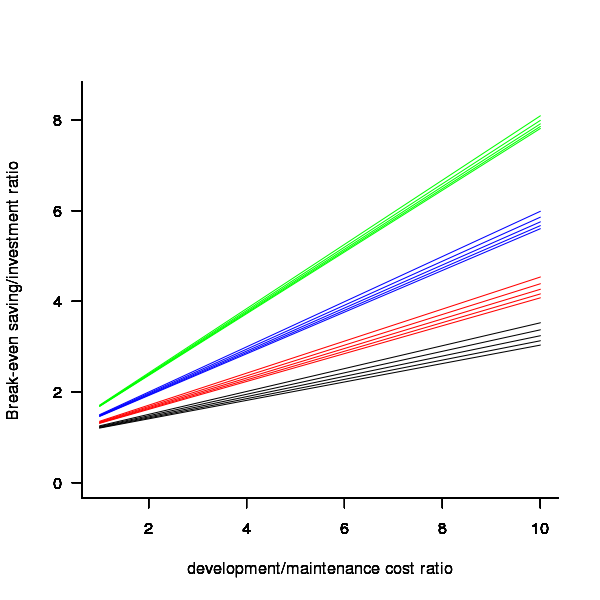
Figure 1. Break even saving/investment ratio for various system survival rates (black 0.9, red 0.8, blue 0.7 and green 0.6) and development/maintenance ratios; system lifetimes are 5.5, 6, 6.5, 7 and 7.5 years (ordered top to bottom)
Development and maintenance costs
Dunn’s PhD thesis <book Dunn_11> lists development and total maintenance costs (for the first five years) of 158 software systems from IBM. The systems varied in size from 34 to 44,070 man hours of development effort and from 21 to 78,121 man hours of maintenance.
The plot below shows the ratio of development to five year maintenance costs for the 158 software systems. The mean value is around one and if we assume equal spending during the maintenance period then  .
.
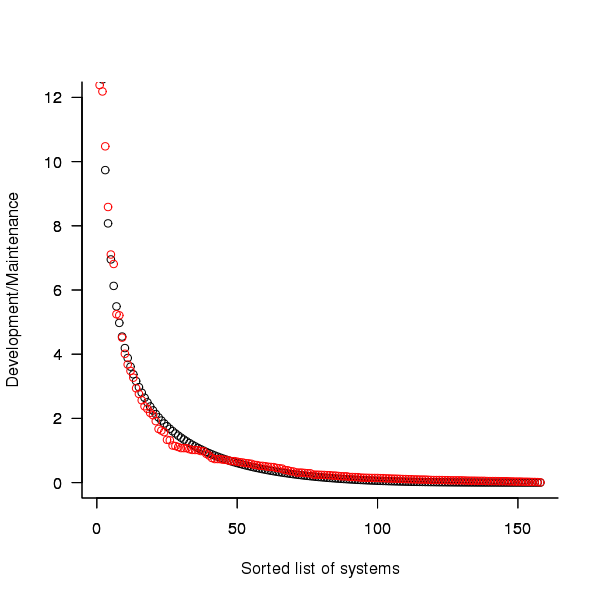
Figure 2. Ratio of development to five year maintenance costs for 158 IBM software systems sorted in size order. Data from Dunn <book Dunn_11>.
The best fitting common distribution for the maintenance/development ratio is the <Beta distribution>, a distribution often encountered in project planning.
Is there a correlation between development man hours and the maintenance/development ratio (e.g., do smaller systems tend to have a lower/higher ratio)? A Spearman rank correlation test between the maintenance/development ratio and development man hours gives:
|
showing very little connection between the two values.
Is the data believable?
While a single company dataset might be thought to be internally consistent in its measurement process, IBM is a very large company and it is possible that the measurement processes used were different.
The maintenance data applies to software systems that have not yet reached the end of their lifespan and is not broken down by year. Any estimate of total or yearly maintenance can only be based on assumptions or lifespan data from other studies.
System lifetime
A study by Tamai and Torimitsu <book Tamai_92> obtained data on the lifespan of 95 software systems. The plot below shows the number of systems surviving for at least a given number of years and a fit of an <Exponential distribution> to the data.
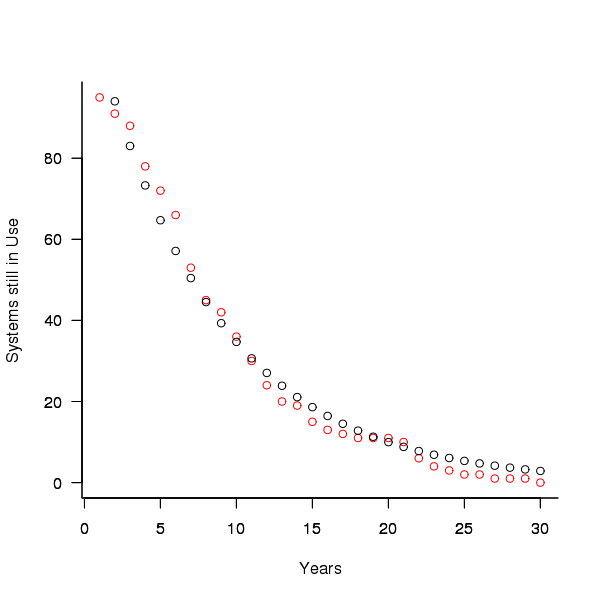
Figure 3. Number of software systems surviving to a given number of years (red) and an exponential fit (black, data from Tamai <book Tamai_92>).
The nls function gives  as the best fit, giving a half-life of 5.4 years (time for the number of systems to reduce by 50%), while rounding to
as the best fit, giving a half-life of 5.4 years (time for the number of systems to reduce by 50%), while rounding to  gives a half-life of 6.6 years and reducing to
gives a half-life of 6.6 years and reducing to  a half life of 4.6 years.
a half life of 4.6 years.
It is worrying that such a small change to the estimated fit can have such a dramatic impact on estimated half-life, especially given the uncertainty in the applicability of the 20 year old data to today’s environment. However, the saving/investment ratio plot above shows that the final calculated value is not overly sensitive to number of years.
Is the data believable?
The data came from a questionnaire sent to the information systems division of corporations using mainframes in Japan during 1991.
It could be argued that things have stabilised over the last 20 years ago and complete software replacements are rare with most being updated over longer periods, or that growing customer demands is driving more frequent complete system replacement.
It could be argued that large companies have larger budgets than smaller companies and so have the ability to change more quickly, or that larger companies are intrinsically slower to change than smaller companies.
Given the age of the data and the application environment it came from a reasonably wide margin of uncertainty must be assigned to any usage patterns extracted.
Summary
Based on the available data an investment during development must recoup a benefit during maintenance that is at least twice as great in percentage terms to break even:
- systems with a yearly survival rate of less than 90% must have a benefit/investment rate greater than two if they are to break even,
- systems with a development/yearly maintenance rate of greater than 20% must have a benefit/investment rate greater than two if they are to break even.
The availanble software system replacement data is not reliable enough to suggest any more than that the estimated half-life might be between 4 and 8 years.
This analysis only considers systems that have been delivered and started to be used. Projects are cancelled before reaching this stage and including these in the analysis would increase the benefit/investment break even ratio.
Readability: we know nothing
Readability is one of those terms that developers use and expect other developers to understand while at the same time being unable to define what it is or how it might be measured. I think all developers would agree that their own code is very readable; if only different developers stopped writing code in different ways the issue would go away 🙂
Having written a book containing lots of material on cognitive psychology and how it might apply to programming, developers who have advanced beyond “Write code like me and it will be readable” sometimes ask for my perceived expert view on the subject. Unfortunately my expertise has only advanced to the stage of: 1) having a good idea of what research questions need to be addressed, 2) being able to point at experimental results showing that most claimed good readability tips are at best worthless or may even increase cognitive load during reading.
To a good approximation we know nothing about code readability. What questions need to answered to change this situation?
The first and most important readability question is: what is the purpose of looking at the code? Is the code being read to gain understanding (likely to involve ‘slow’ and deliberate behavior) or is the reader searching for some construct (likely to involve skimming; yes, slow and deliberate is more accurate but people make cost/benefit decisions when deciding which strategies to use. The factors involved in reader strategy selection is another important question)?
Next we need to ask what characteristics of developer performance are expected to change with different code organization/layouts. Are we interested in minimizing error, minimizing the time taken to achieve the readers purpose or something else?
What source code attributes play a significant role in readability? Possibilities include the order in which various constructs appear (e.g., should variable definitions appear at the start of a function or close to where they are first used), variable names and the position of tokens relative to each other when viewed by the reader.
Questions involving the relative position of tokens probably generates the greatest volume of discussion among developers. To what extent does visual organization of source code affect reader performance? Fluent reading requires a significant amount of practice, perhaps readable code is whatever developers have spent lots of time reading.
If there is some characteristic of the human visual system that generates a worthwhile benefit to splitting long lines so that a binary operator appears at the {end of the last}/{start of the next} line, will it apply the same way to all developers? We could end up developers having to configure their editor so it displays code in a form that matches the characteristics of their visual system.
How might these ‘visual’ questions be answered? I think that eye tracking will play a large role (“Eyetracking Web Usability” by Jakob Nielsen and Kara Pernice is a good read). At the moment there are technical/usability issues that make this kind of research very difficult. Eye trackers capable of continuously supporting enough resolution to know which character on the screen a developer is looking at (e.g., EyeLink 1000) require that the head be held in a fixed position, while those allowing completely free head movement (e.g., S2 Eye Tracker) don’t yet continuously support the required resolution.
Of course any theory derived from eye tracking experiments will still have to be validated by measuring developer performance on various code snippets.
The most worthwhile R coding guidelines I know
Since my post questioning whether native R usage exists (e.g., a common set of R coding patterns) several people have asked about coding/style guidelines for R. My approach to style/coding guidelines is economic, adhering to a guideline involves paying a cost now for some future benefit. Obviously to be worthwhile the benefit must be greater than the cost, there is also the issue of who pays the cost and who reaps the benefit (why would anybody pay the cost if somebody else reaps the benefit?). The following three topics are probably where the biggest benefits are to be had and only the third is specific to R (and given the state of my R knowledge may be wrong).
Comment your code. Investing 5-10 seconds per few lines of code now could save substantially more time at some future date. Effective commenting is a skill that has to be learned, start learning now. Think of commenting as sending a text message or tweet to the person you will be in 6 months time (i.e., the person who can hum the tune but has forgotten the details).
Consistently use variable names that mean something to you. This should be a sub 2-second decision that is probably going to save you no more than 5-10 seconds, but in many cases you reap the benefit soon after the investment, without having to wait many months. Names evoke associations in your mind, take advantage of this associative lookup to reduce the cognitive load of working with your code. Effective naming is a skill that has to be learned, start learning now. There are people who ignore the evidence that different people’s linguistic preferences and associations can be very different and insist that everybody adhere to one particular naming convention; ignore them.
Code organization and structure. Experience shows that there are ways of organizing and structuring +1,000 line programs that have a significant impact on the effort needed to actively work on the code, the more code there is the greater the impact. R programs tend to be short, say around 100 lines (I dare say much longer ones exist). Apart from recommending that code be broken up into separate functions, I cannot think of any organizational/structural issue that is worth recommending for 100 lines of code (if you don’t appreciate the advantage of using separate functions you need some hands on training, not words in a blog post).
Is that it, are there no other worthwhile recommendations? There might be, I just don’t have enough experience using R to know. Does anybody else have enough experience to know? I suspect not; where would they have gotten the information needed to do the cost/benefit analysis? Even in the rare case where a detailed analysis is made for a language the results are rather thin on the ground and somewhat inconclusive.
What is the reason behind those R style guides/coding guideline documents that have been written? The following are some possibilities:
and no, I don’t have any empirical data to backup my guidelines 🙁