Archive
21 Algol 60 compilers in 1962
The specification of ALGOL 60 was published in May 1960. Unlike today, where the creators of a new language release the source of a corresponding compiler, people were expected to write their own compiler. The June 1962 paper: The Replies to the AB14 Questionnaire lists implementation details on 21’ish compilers (it’s not clear whether some are dialects or languages very similar to Algol 60; 1963: list of 32 Algol compilers/versions).
Compiler writing was a hot leading edge research topic in the 1960s; at the start of this decade all the techniques we take for granted today had not yet been invented (Knuth invented LR parsing in 1965, and algorithms for optimal code generation started appearing in 1970). The 1960s was the period of the Cambrian explosion for programming languages.
Implementors not only had to deal with all the unknowns of writing a compiler, they also had to do the work using systems whose memory was measured in tens of kilobytes, computer interaction probably via punched card or punched tape, or if lucky, the luxury of teletype input/output. It’s no surprise that fourteen of the implementations considered themselves to be a “true subset” (which I take to mean that everything implemented was as per the specification). Compilers for earlier languages probably had the benefit of the language not supporting anything that was hard to implement.
Compiler implementation know-how received a major boost in 1964 with the publication of the book ALGOL 60 Implementation.
The plot below shows the number of compilers having a given reported implementation time (code+data):
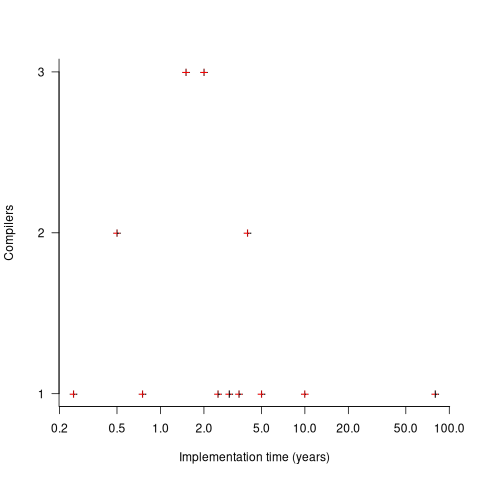
The median implementation effort is 2 man-years. Is this the result of a few good people working off the clock to create software, or management supporting the creation of a product that customers are not clamouring for?
The 0.25 man-year implementation looks like a port of an existing compiler to a different version of the same hardware. The 10 man-year implementation time was for what looks like a full implementation, plus extensions. The 80 man-year implementation time was reported by SDC (a large defence contractor) for a range of JOVIAL compilers (derived from Algol 58) targetting five different hardware platforms.
Were the implementors of Algol compilers different from the implementors of other languages? It’s not possible to say, although the language was created by a distinct group of people. The definition of Algol 60 was created by a committee composed of computing academics and like-minded people, while Fortran was dominated by the major computer company of the day, IBM (1963: list of 51 Fortran compilers; 1964: at least 43 Fortran compilers/versions), and COBOL was designed to be used by those strange business people (1963: list of 37 COBOL implementations/versions).
The best or most compiler writers born in February?
Some years ago, now, I ran a poll asking about readers’ month of birth and whether they had worked on a compiler. One hypothesis was that the best compiler writers are born in February, an alternative hypothesis is that most compiler writers are born in February.
I have finally gotten around to analyzing the data and below is the Rose diagram for the 82, out of 132 responses, compiler writers (the green arrow shows the direction and magnitude of the mean; code+data):
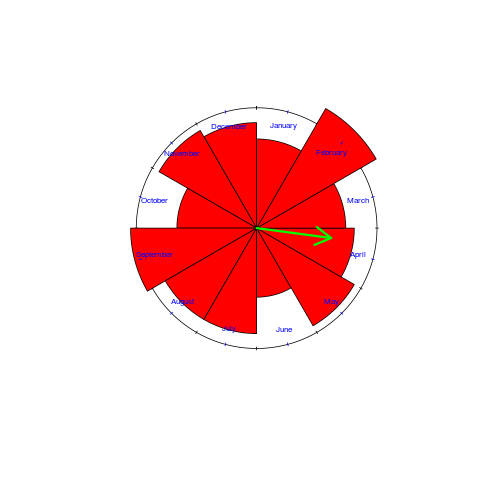
At 15% of responses, February is the most common month for compiler writer birthdays. The percentage increases to 16%, if weighted by the number of births in each month.
So there you have it, the hypothesis that most compiler writers are born in February is rejected, leaving the hypothesis that the best compiler writers are born in February. How could this not be true 🙂
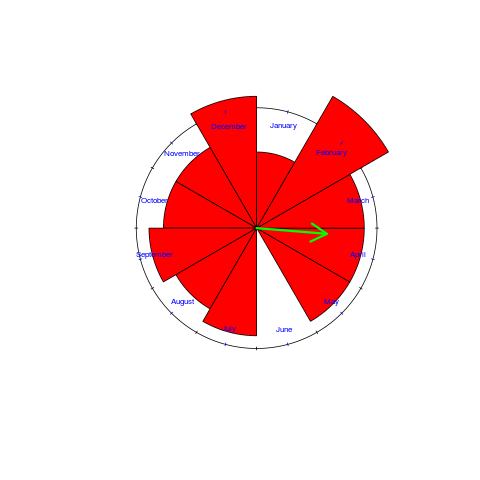
What about the birth month of readers who are not compiler writers? While the mean direction and length are more-or-less the same, for the two populations, the Rose diagram shows that the shape of the distributions are different:
undefined behavior: pay up or shut up
Academia recently discovered undefined behavior in C, twenty five years after industry tool vendors first started trying to help developers catch the problems it causes. Some of the tools that are now being written are doing stuff that we could only dream about back in the day.
The forces that morph occurrences of undefined behavior in source code to unwanted behavior during program execution have changed over the years.
- When developers paid for their compilers there was an incentive for compiler writers to try to be nice to developers by doing the right thing for undefined behaviors. Twenty five years ago there were lots of commercial compilers all having slightly different views about what the right thing might be; a lot of code was regularly ported to different compilers and got to encounter different compiler writer’s views.
- These days there is widespread use of open source compilers, which developers don’t pay for, removing the incentive for compilers writers to be nice to developers. Paying customers want support for new processors, enhancements to existing generated code quality and the sexy topic for PhDs is code optimization; what better climate for treating source containing undefined behavior as road kill. Now developers only need to upgrade to a later release of the compiler they are using to encounter an unexpected handling of undefined behavior.
A recent blog post, authored by some of the academics alluded to above, proposes adding a new option to gcc: -std=friendly-c. If developers feel that this kind of option needs to be supported then they should contribute to a crowdfunding campaign (none exists at the time of writing) to raise, say, $500,000 towards supporting the creation and ongoing support for the functionality behind this option. Of course one developer’s friendly is another developer’s unfriendly, so we could end up with multiple funds each promoting an option that supports a view of the world that is specific to one target environment.
At the moment, in response to user complaints, Open source compiler vendors lamely point out that the C standard permits them to handle source containing undefined behaviors the way they do; they stop short of telling people to quit complaining and that they are getting the compiler for free.
If this undefined behavior issue starts to gain substantial publicity, but insufficient funding, open source compiler vendors will need to start putting a positive spin on the decisions they make. Not being in marketing I might have a problem keeping a straight face when giving the following positive messages:
- We are helping to save the world: optimized programs use less power (ok, every now and again they can use more). Do you really want to stop us adding more optimizations just because you cannot find the time to fix a mistake in your code?
- We are helping your application gain market share. Applications that are not actively maintained are less and less likely to continue to work with every release of the compiler.
Compiler writing is for hedgehogs
It is said that a fox knows many thing, but the hedgehog knows one big thing. An insightful article by Venkatesh Rao (Venkat) showed how foxes and hedgehogs uniquely map to the two contrasting philosophical points of view of those having weak views that are strongly held (a fox) and those having strong views that are weakly held (a hedgehog).
Venkat observes that the many things the fox knows are acquired from multiple sources and that this disparate collection of knowledge is not connected together by any consistent set of core principles; the one big thing that a hedgehog knows consists of knowledge that is connected by a small set of consistent core principles.
An average developer’s knowledge of a language is very fox-like, i.e., it is culled from many particular instances with each snippet of knowledge being accompanied by the experience around which it was obtained. Back in the day, the ‘advanced’ courses I used to give to developers who had 2-3 years experience were really designed to show how the components of a language fitted together, i.e., to provide a structure to what they already knew about the language. Switching developers from an approach based on their experience of particular instances for each language feature to a rule based approach was often hard work, some developers seem to be naturally driven by itemized personal experiences.
Of necessity a compiler writer spends a lot of time studying one programming language (I’m excluding those who invent their own language as they write the compiler for it) and/or hardware cpu. This extended period of study, assuming the developer has sufficient cognitive capacity (the drop out rate is high), creates a heavily interconnected knowledge of the language in the compiler writer’s head, i.e., they understand one thing very deeply and have strong views created by the core rules they have created to organize this knowledge. These views are weakly held because experience shows that every now and again a major insight is achieved that changes the developer’s perspective completely.
This fox-like characteristic of developer language knowledge goes a long way towards explaining why religious language wars go on for so long and can be so ferocious. A fox is arguing from personal experience that is not based on a set of core principles; every point has to be argued because there is nothing connecting them, undermining one idea does not affect the status of the beliefs about anything else.
I am not arguing that being a fox is a good or a bad thing, and I am certainly not arguing that everybody should spend the huge amount of time needed to become a hedgehog (it is not a cost effective use of time). I am simply making an observation about a state of affairs, and one that is likely to continue because there are no incentives in trying to change things.
I think being a major contributor in the creation of any large and complex software system requires that somebody be or become a hedgehog.
I think that many software developers are foxes; of course to people looking in developers appear to be hedgehogs in the world of software.
Adverts during compilation; the future for gcc and llvm?
Many of the larger open source projects have most of their manpower supplied by commercial companies. Companies pay developers to work on open source projects because it is in their interest to do so. The current level of funding will not last forever and some open source projects will either have to significantly slim down their operations or find other revenue streams.
For the last few years (and probably the next few) Mozilla obtained most of its funding from Google through a licensing agreement (Google is the default search engine in the search box). No company wants to be dependent on a single source for a large chunk of its income and Mozilla is no exception. But where are the review streams for open source companies? Training and consulting are the obvious choices for technical products, but web browsers are supposed to user friendly, not technical. Another option is advertising and Mozilla has indicated an intent to go down this path.
How are open source compilers funded? A lot of the work on gcc used to be done by the folk at Code Sourcery, which is not owned by Mentor Graphics, and I was told their income primarily came from companies interested in ports to new processors and platforms. I have no idea how the gcc group is funded inside Mentor Graphics, but the long term prognosis does not look good; there is a long history of large tech companies buying compiler outfits and closing them down some years later (because the income they produce is not worth the hassle). The LLVM project, I’m told, gets most of its funding from Apple and one of my predictions for 2009 was that this funding would go away and LLVM would die; ok I was wrong about the year, but eventually Apple will stop funding this project.
Advertising is a possible revenue stream for compiler vendors; compilers could show adverts while compiling. Anybody who has used a commercial compiler will be familiar with the copyright notices that appear at the start of every compilation, so having a text message appear at the start of every compile is not new. Advertising could take the form of product placement “This version of gcc is brought to you by Wizzo Wash” or display material downloaded during compilation.
Adverts during compilation are not going to be popular with developers. One solution is to offer a subscription service for an ads free version of the compiler. It will certainly be necessary to make it much more difficult to build the compiler from source.
This form of revenue generation will have to be sold to developers; a group not known for its willingness to pay for tools (new tool vendors quickly learn to sell to management and ignore developers) combined with compiler writers not being known for having any selling ability.
2013 in the programming language standards’ world
Yesterday I was at the British Standards Institute for a meeting of IST/5, the committee responsible for programming languages. Things have been rather quiet since I last wrote about IST/5, 18 months ago. Of course lots of work has been going on (WG21 meetings, C++ Standard, are attracting 100+ people, twice a year, to spend a week trying to reach agreement on new neat features to add; I’m not sure how the ability to send email is faring these days ;-).
Taken as a whole programming languages standards work, at the ISO level, has been in decline over the last 10 years and will probably decline further. IST/5 used to meet for a day four times a year and now meets for half a day twice a year. Chairman of particular language committees, at international and national levels, are retiring and replacements are thin on the ground.
Why is work on programming language standards in decline when there are languages in widespread use that have not been standardised (e.g., Perl and PHP do not have a non-source code specification)?
The answer is low hardware/OS diversity and Open source. These two factors have significantly reduced the size of the programming language market (i.e., there are far fewer people making a living selling compilers and language related tools). In the good old-days any computer company worth its salt had its own cpu and OS, which of course needed its own compiler and the bigger vendors had third parties offering competing compilers; writing a compiler was such a big undertaking that designers of new languages rarely gave the source away under non-commercial terms, even when this happened the effort involved in a port was heroic. These days we have a couple of cpus in widespread use (and unlikely to be replaced anytime soon), a couple of OSs and people are queuing up to hand over the source of the compiler for their latest language. How can a compiler writer earn enough to buy a crust of bread let alone attend an ISO meeting?
Creating an ISO language standard, through the ISO process, requires a huge amount of work (an estimated 62-person years for C99; pdf page 20). In a small market, few companies have an incentive to pay for an employee to be involved in the development process. Those few languages that continue to be worked on at the ISO level have niche markets (Fortran has supercomputing and C had embedded systems) or broad support (C and now C++) or lots of consultants wanting to be involved (C++, not so much C these days).
The new ISO language standards are coming from national groups (e.g., Ruby from Japan and ECMAscript from the US) who band together to get the work done for local reasons. Unless there is a falling out between groups in different nations, and lots of money is involved, I don’t see any new language standards being developed within ISO.
Superoptimizers are back in vogue
There has always been the need for a few developers with in-depth knowledge of a particular cpu architecture to sit down and think very hard about how best to implement a snippet of code performing some operation in assembly language, e.g., library implementors wanting the tightest code for a critical inner loop or compiler writers who need to map from intermediate code to machine code.
In 1987 Massalin published his now famous paper that introduced the term Superoptimizer; a program that enumerates all possible combinations of instruction sequences until the shortest/fastest one producing the desired output from the given input is found (various heuristics were used to prune the search space e.g., only considering 15 or so opcodes, and the longest sequence it ever generated contained 12 instructions).
While the idea was widely talked about, it never caught on in practice (a special purpose branch eliminator was produced for GCC; Hacker’s Delight also includes a stand-alone system). Perhaps the guild of mindbogglingly-obtuse-but-fast-instruction-sequences black-balled it (apprentices have to spend several years doing nothing but writing assembly code for their chosen architecture, thinking about how to make it go faster and/or be shorter and only talk to other apprentices/members and communicate with non-converts exclusively about their latest neat sequence), or perhaps it was just a case of not invented here (writing machine code used to be something that even run-of-the-mill developers got to do every now and again), or perhaps it was not considered cost-effective to build a superoptimizer for a given project (I don’t know of anyone offering a generic tool that could be tailored for specific cases) or perhaps developers were happy to just ride the wave of continually faster processors.
It was not until 2008 with Bansal’s thesis that superoptimizer research started to take off (as in paper publication rate increased from once every five years to more than one a year). Bansal found a new market, binary translation i.e., translating the binary of a program built to run on one kind of cpu to run on a different kind of cpu, for instance the Mac 68K emulator.
Bansal and other researchers’ work was oriented towards relatively short instruction sequences. To be really useful, some way of handling longer sequences was needed.
A few days ago Stochastic Superoptimization arrived on the scene (or rather a paper describing it became available for download). Schkufza, Sharma and Aiken use Markov chain Monte Carlo methods to sample the possible instruction sequences rather than generating all of them. The paper gives a 116 instruction example from which the author’s tool removed 16 lines to produce code that went 1.6 times faster (only 30 ‘core’ instructions were given in paper); what is also very interesting is that the tool operates on compiler generated output (gcc/llvm), suggesting the usage build program, profile it and then stochastic superoptimize the hot spots.
Markov chains and Monte Carlo methods are trendy topics that researchers like to write about, so we will certainly see more papers in this area.
These days few developers have had hands-on experience with machine code, so the depth of expertise that was once easy to find is now rare, processors have many more weird and wonderful instructions often interacting with older instructions in obscure ways, and the cpu architecture landscape continues to change regularly. The time may have arrived for superoptimizers to be widely used by industry.
Of course, superoptimizers can work at any level of abstraction, including expression trees built directly from some complicated floating-point calculation that needs to be optimized for accuracy or speed.
Undefined behavior can travel back in time
The committee that produced the C Standard tried to keep things simple and sometimes made very short general statements that relied on compiler writers interpreting them in a ‘reasonable’ way. One example of this reliance on ‘reasonable’ behavior is the definition of undefined behavior; “… erroneous program construct or of erroneous data, for which this International Standard imposes no requirements”. The wording in the Standard permits a compiler to process the following program:
int main(int argc, char **argv) { // lots of code that prints out useful information 1 / 0; // divide by zero, undefined behavior } |
to produce an executable that prints out “yah boo sucks”. Such behavior would probably be surprising to the developer who expected the code printing the useful information to be executed before the divide by zero was encountered. The phrase quality of implementation is heard a lot in committee discussions of this kind of topic, but this phrase does not appear in any official document.
A modern compiler is essentially a sophisticated domain specific data miner that happens to produce machine code as output and compiler writers are constantly looking for ways to use the information extracted to minimise the code they generate (minimal number of instructions or minimal amount of runtime). The following code is from the Linux kernel and its authors were surprised to find that the “division by zero” messages did not appear when arg2 was 0, in fact the entire if-statement did not appear in the generated code; based on my earlier example you can probably guess what the compiler has done:
if (arg2 == 0) ereport(ERROR, (errcode(ERRCODE_DIVISION_BY_ZERO), errmsg("division by zero"))); /* No overflow is possible */ PG_RETURN_INT32((int32)arg1 / arg2); |
Yes, it figured out that when arg2 == 0 the divide in the call to PG_RETURN_INT32 results in undefined behavior and took the decision that the actual undefined behavior in this instance would not include making the call to ereport which in turn made the if-statement redundant (smaller+faster code, way to go!)
There is/was a bug in Linux because of this compiler behavior. The finger of blame could be pointed at:
- the developers for not specifying that the function
ereportdoes not return (this would enable the compiler to deduce that there is no undefined behavior because the divide is never execute whenarg2 == 0), - the C Standard committee for not specifying a timeline for undefined behavior, e.g., program behavior does not become undefined until the statement containing the offending construct is encountered during program execution,
- the compiler writers for not being ‘reasonable’.
In the coming years more and more developers are likely to encounter this kind of unexpected behavior in their programs as compilers do more and more data mining and are pushed to improve performance. Other examples of this kind of behavior are given in the paper Undefined Behavior: Who Moved My Code?
What might be done to reduce the economic cost of the fallout from this developer ignorance/standard wording/compiler behavior interaction? Possibilities include:
- developer education: few developers are aware that a statement containing undefined behavior can have an impact on the execution of code that occurs before that statement is executed,
- change the wording in the Standard: for many cases there is no reason why the undefined behavior be allowed to reach back in time to before when the statement executing it is executed; this does not mean that any program output is guaranteed to occur, e.g., the host OS might delete any pending output when a divide by zero exception occurs.
- paying gcc/llvm developers to do front end stuff: nearly all gcc funding is to do code generation work (I don’t know anything about llvm funding) and if the US Department of Homeland security are interested in software security they should fund related front end work in gcc and llvm (e.g., providing developers with information about suspicious usage in the code being compiled; the existing
-Wallis a start).
EU rules that computer languages cannot be copyrighted
The European Court of Justice has published its decision in SAS v WPL; the title of the press release says it all “The functionality of a computer program and the programming language cannot be protected by copyright”. To summarise the background, World Programming Ltd developed a system that was capable of emulating the input/output behavior of programs written in what the SAS Institute Inc were claiming to be their copyrighted scripting language, along with various file formats.
According to the Court of Justice, “the Court holds that neither the functionality of a computer program nor the programming language and the format of data files used in a computer program in order to exploit certain of its functions constitute a form of expression. Accordingly, they do not enjoy copyright protection.”
This EU ruling is not quiet what it seems. The SAS v WPL case is before the High Court in London and the EU Court of Justice has been asked for advice based on European Law. So the UK dispute has not yet been decided, but given that the UK is signed up to adhere by EU laws people who know about the legal stuff seem to think the High Court in London will follow the EU ruling. Assuming this, then…
This ruling is not just bad news for SAS, it is also bad news for their competitors. Competition is likely to lead to better/cheaper products for users of the SAS language, resulting in less incentive for them to move to an alternative (the R language included; incidentally what exactly are The R Foundation for Statistical Computing claiming copyright over in that notice that pops up when R is started?)
The Oracle vs. Google Java API lawsuit involves similar territory. There are plenty of details over at Groklaw and I’m not going to go there.
This ruling makes it much more likely that behave-alike implementations of more ‘corporate languages’ will be created, at least in Europe. Previously the threat of a lawsuit would have been enough to deter most people, irrespective of whether what they wanted to do was legal or not.
What languages might we see implemented any time soon? The one that immediately springs to mind for me is Mathematica, which is the leader in its field and a fork of Maxima that supported the Mathematica language would move it out of the ghetto. Octave and Matlab are already very close, so no change there.
I imagine there are corporate languages scattered over every conceivable application domain. A lot of these domains will be sufficiently specialized that there is a very low probability of somebody creating an open source implementation; if it looks like there is money to be made it has become more likely that an alternative commercial implementation will be created.
It looks like being a compiler writer is back as flavor of the month again 🙂
Birth month for compiler writers
Today is my birthday and an event from a long ago project springs to mind. All four of us from the UK arm of the team were born in February, one person on the same day as me (Happy Birthday Mick, where ever you are). This clustering of birth months led us to the obvious conclusion that the best compiler writers are born in February. Over the years I have retold this story to other compiler writers and found out their birth month. Now I will try and be a bit more scientific and have set up a survey (see below).
What counts as a compiler and what does somebody have to do to be considered a compiler writer (lets stay away from the issue of quality)? I would include software that performs computer language translation to another language (i.e., not just intermediate code or assembler) and static analysis of source provided it involved a lot of semantics (i.e., not working on the GUI that presents the data). I would exclude writing test cases, documentation, project management and maintenance (i.e., only fixing faults and dealing with customer queries).
I would classify a compiler writer as somebody who spent a substantial amount of their time working almost exclusively on writing a compiler. How substantial? Well, I think it ought o be possible to do something useful in about 4 months (I thought about saying 6 months, but decided to be generous.
Please take part, even if you do not consider yourself to be a compiler writer. A control group is always useful (perhaps readers of this blog have a preferred birth month)
I will make the numbers available and discuss them in a future article (probably in March).
[SURVEYS 1]
If anybody else is interested in running a survey, the surveys WordPress plugin allows more than one question to be specified and worked better than the other popular plugins for me (there is one bug that needs to be fixed: show_survey.php, line 51 should be:
$email_body = t("Hi,\nThere is a new result for the survey at %s...\n", $_SERVER['REQUEST_URI']); ).
Recent Comments