Archive
2023 in the programming language standards’ world
Two weeks ago I was on a virtual meeting of IST/5, the committee responsible for programming language standards in the UK. IST/5 has a new chairman, Guy Davidson, whose efficiency is very unstandard’s like.
It’s been 18 months since I last reported on the programming language standards’ world, what has been going on?
2023 is going to be a bumper year for the publication of revised Standards of long-established programming language: COBOL, Fortran, C, and C++ (a revised Standard for Ada was published last year).
Yes, COBOL; a new COBOL Standard was published in January. Reports of its death were premature, e.g., my 2014 post suggesting that the latest version would be the last version of the Standard, and the closing of PL22.4, the US Cobol group, in 2017. There has even been progress on the COBOL front end for gcc, which now supports COBOL 85.
The size of the COBOL Standard has leapt from 955 to 1,229 pages (around new 200 pages in the normative text, 100 in the annexes). Comparing the 2014/2023 documents, I could not see any major additions, just lots of small changes spread throughout the document.
Every Standard has a project editor, the person tasked with creating a document that reflects the wishes/votes of its committee; the project editor sends the agreed upon document to ISO to be published as the official ISO Standard. The ISO editors would invariably request that the project editor make tiresome organizational changes to the document, and then add a front page and ISO copyright notice; from time to time an ISO editor took it upon themselves to reformat a document, sometimes completely mangling its contents. The latest diktat from ISO requires that submitted documents use the Cambria font. Why Cambria? What else other than it is the font used by the Microsoft Word template promoted by ISO as the standard format for Standard’s documents.
All project editors have stories to tell about shepherding their document through the ISO editing process. With three Standards (COBOL lives in a disjoint ecosystem) up for publication this year, ISO editorial issues have become a widespread topic of discussion in the bubble that is language standards.
Traditionally, anybody wanting to be actively involved with a language standard in the UK had to find the contact details of the convenor of the corresponding language panel, and then ask to be added to the panel mailing list. My, and others, understanding was that provided the person was a UK citizen or worked for a UK domiciled company, their application could not be turned down (not that people were/are banging on the door to join). BSI have slowly been computerizing everything, and, as of a few years ago, people can apply to join a panel via a web page; panel members are emailed the CV of applicants and asked if “… applicant’s knowledge would be beneficial to the work programme and panel…”. In the US, people pay an annual fee for membership of a language committee ($1,340/$2,275). Nobody seems to have asked whether the criteria for being accepted as a panel member has changed. Given that BSI had recently rejected somebodies application to join the C++ panel, the C++ panel convenor accepted the action to find out if the rules have changed.
In December, BSI emailed language panel members asking them to confirm that they were actively participating. One outcome of this review of active panel membership was the disbanding of panels with ‘few’ active members (‘few’ might be one or two, IST/5 members were not sure). The panels that I know to have survived this cull are: Fortran, C, Ada, and C++. I did not receive any email relating to two panels that I thought I was a member of; one or more panel convenors may be appealing their panel being culled.
Some language panels have been moribund for years, being little more than bullet points on the IST/5 agenda (those involved having retired or otherwise moved on).
Survival rate of WG21 meeting attendance
WG21, the C++ Standards committee, has a very active membership, with lots of people attending the regular meetings; there are three or four meetings a year, with an average meeting attendance of 67 (between 2004 and 2016).
The minutes of WG21 meetings list those who attend, and a while ago I downloaded these for meetings between 2004 and 2016. Last night I scraped the data and cleaned it up (or at least the attendee names).
WG21 had its first meeting in 1992, and continues to have meetings (eleven physical meetings at the time or writing). This means the data is both left and right censored; known as interval censored. Some people will have attended many meetings before the scraped data starts, and some people listed in the data may not have attended another meeting since.
What can we say about the survival rate of a person being a WG21 attendee in the future, e.g., what is the probability they will attend another meeting?
Most regular attendees are likely to miss a meeting every now and again (six people attended all 30 meetings in the dataset, with 22 attending more than 25), and I assumed that anybody who attended a meeting after 1 January 2015 was still attending. Various techniques are available to estimate the likelihood that known attendees were attending meetings prior to those in the dataset (I’m going with what ever R’s survival package does). The default behavior of R’s Surv function is to handle right censoring, the common case. Extra arguments are needed to handle interval censored data, and I think I got these right (I had to cast a logical argument to numeric for some reason; see code+data).
The survival curves in days since 1 Jan 2004, and meetings based on the first meeting in 2004, with 95% confidence bounds, look like this:
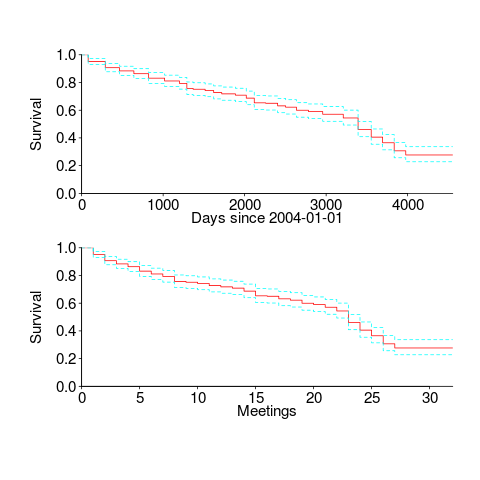
I was expecting a sharper initial reduction, and perhaps wider confidence bounds. Of the 374 people listed as attending a meeting, 177 (47%) only appear once and 36 (10%) appear twice; there is a long tail, with 1.6% appearing at every meeting. But what do I know, my experience of interval censored data is rather limited.
The half-life of attendance is 9 to 10 years, suspiciously close to the interval of the data. Perhaps a reader will scrape the minutes from earlier meetings 🙂
Within the time interval of the data, new revisions of the C++ standard occurred in 20072011 and 2014; there had also been a new release in 2003, and one was being worked on for 2017. I know some people stop attending meetings after a major milestone, such as a new standard being published. A fancier analysis would investigate the impact of standards being published on meeting attendance.
People also change jobs. Do WG21 attendees change jobs to ones that also require/allow them to attend WG21 meetings? The attendee’s company is often listed in the minutes (and is in the data). Something for intrepid readers to investigate.
C Standard meeting, April-May 2019
I was at the ISO C language committee meeting, WG14, in London this week (apart from the few hours on Friday morning, which was scheduled to be only slightly longer than my commute to the meeting would have been).
It has been three years since the committee last met in London (the meeting was planned for Germany, but there was a hosting issue, and Germany are hosting next year), and around 20 people attended, plus 2-5 people dialing in. Some regular attendees were not in the room because of schedule conflicts; nine of those present were in London three years ago, and I had met three of those present (this week) at WG14 meetings prior to the last London meeting. I had thought that Fred Tydeman was the longest serving member in the room, but talking to Fred I found out that I was involved a few years earlier than him (our convenor is also a long-time member); Fred has attended more meeting than me, since I stopped being a regular attender 10 years ago. Tom Plum, who dialed in, has been a member from the beginning, and Larry Jones, who dialed in, predates me. There are still original committee members active on the WG14 mailing list.
Having so many relatively new meeting attendees is a good thing, in that they are likely to be keen and willing to do things; it’s also a bad thing for exactly the same reason (i.e., if it not really broken, don’t fix it).
The bulk of committee time was spent discussing the proposals contains in papers that have been submitted (listed in the agenda). The C Standard is currently being revised, WG14 are working to produce C2X. If a person wants the next version of the C Standard to support particular functionality, then they have to submit a paper specifying the desired functionality; for any proposal to have any chance of success, the interested parties need to turn up at multiple meetings, and argue for it.
There were three common patterns in the proposals discussed (none of these patterns are unique to the London meeting):
- change existing wording, based on the idea that the change will stop compilers generating code that the person making the proposal considers to be undesirable behavior. Some proposals fitting this pattern were for niche uses, with alternative solutions available. If developers don’t have the funding needed to influence the behavior of open source compilers, submitting a proposal to WG14 offers a low cost route. Unless the proposal is a compelling use case, affecting lots of developers, WG14’s incentive is to not adopt the proposal (accepting too many proposals will only encourage trolls),
- change/add wording to be compatible with C++. There are cost advantages, for vendors who have to support C and C++ products, to having the two language be as mutually consistent as possible. Embedded systems are a major market for C, but this market is not nearly as large for C++ (because of the much larger overhead required to support C++). I pointed out that WG14 needs to be careful about alienating a significant user base, by slavishly following C++; the C language needs to maintain a separate identity, for long term survival,
- add a new function to the C library, based on its existence in another standard. Why add new functions to the C library? In the case of math functions, it’s to increase the likelihood that the implementation will be correct (maths functions often have dark corners that are difficult to get right), and for string functions it’s the hope that compilers will do magic to turn a function call directly into inline code. The alternative argument is not to add any new functions, because the common cases are already covered, and everything else is niche usage.
At the 2016 London meeting Peter Sewell gave a presentation on the Cerberus group’s work on a formal definition of C; this work has resulted in various papers questioning the interpretation of wording in the standard, i.e., possible ambiguities or inconsistencies. At this meeting the submitted papers focused on pointer provenance, and I was expecting to hear about the fancy optimizations this work would enable (which would be a major selling point of any proposal). No such luck, the aim of the work was stated as clearly specifying the behavior (a worthwhile aim), with no major new optimizations being claimed (formal methods researchers often oversell their claims, Peter is at the opposite end of the spectrum and could do with an injection of some positive advertising). Clarifying behavior is a worthwhile aim, but not at the cost of major changes to existing wording. I have had plenty of experience of asking WG14 for clarification of existing (what I thought to be ambiguous) wording, only to be told that the existing wording was clear and not ambiguous (to those reviewing my proposed defect). I wonder how many of the wording ambiguities that the Cerberus group claim to have found would be accepted by WG14 as a defect that required a wording change?
Winner of the best pub quiz question: Does the C Standard require an implementation to be able to exactly represent floating-point zero? No, but it is now required in C2X. Do any existing conforming implementations not support an exact representation for floating-point zero? There are processors that use a logarithmic representation for floating-point, but I don’t know if any conforming implementation exists for such systems; all implementations I know of support an exact representation for floating-point zero. Logarithmic representation could handle zero using a special bit pattern, with cpu instructions doing the right thing when operating on this bit pattern, e.g., 0.0+X == X, (I wonder how much code would break, if the compiler mapped the literal 0.0 to the representable value nearest to zero).
Winner of the best good intentions corrupted by the real world: intmax_t, an integer type capable of representing any value of any signed integer type (i.e., a largest representable integer type). The concept of a unique largest has issues in a world that embraces diversity.
Today’s C development environment is very different from 25 years ago, let alone 40 years ago. The number of compilers in active use has decreased by almost two orders of magnitude, the number of commonly encountered distinct processors has shrunk, the number of very distinct operating systems has shrunk. While it is not a monoculture, things appear to be heading in that direction.
The relevance of WG14 decreases, as the number of independent C compilers, in widespread use, decreases.
What is the purpose of a C Standard in today’s world? If it were not already a standard, I don’t think a committee would be set up to standardize the language today.
Is the role of WG14 now, the arbiter of useful common practice across widely used compilers? Documenting decisions in revisions of the C Standard.
Work on the Cobol Standard ran for almost 60-years; WG14 has to be active for another 20-years to equal this.
Reality in the world of programming language standards
I see a lot of steam being vented about the standards’ process as applied to programming languages and software related topics. Knowing something about how the process works might help people live calmer lives, at least once they have calmed down after reading this article. What I have to say applies to programming language standards because these are what I have been involved with, as a member and convener of various UK and international committtees, for 25+ years.
- ISO and your national standards’ body don’t care about the standard you are talking about.
These organizations are monopolies who are required to demonstrate that documented procedures are followed by all concerned. Can you think of any organizational structure that would create less incentives for those on the inside to listen to those on the outside?
Yes, these organizations do sell standards but the sales model is all about the long tail and no peak, to speak of, of best sellers. The real business model for running a standards’ organization is to either charge members a fee (your country pays membership dues for each Standards Committee it wants a say in; if your country has not paid to be a member of ISO JTC 1/SC22 you have no say in programming language standards. ANSI in the US charges people for the right to volunteer their time to attend meetings to work on a standard) and/or rely on government subsidy.
Not being cared about is actually a luxury that people who work in programming language standards should aspire to. The bureaucrats who work in standards hate us; here in the UK there has been at least one attempt to kill off work on programming language standards and I have heard of similar experiences in other countries. The problem is that the standards we produce don’t fit the mold that works for most other standards; programming language standards contain an order of magnitude more pages than the average standard (until recently there was a print run of new standards which then had to be stored until sold and the volume occupied by programming language standards was of note {so I’m reliably informed}), take longer to produce (i.e., more work for the bureaucrats) and all this cost is not justified by the sales figures (which are confidential and last time I saw them only just required me to take my shoes and socks off to count).
- Standards are created by the volunteers who regularly turn up at meetings.
It is only the enthusiasm of these volunteers that makes the process work. If you don’t turn up at meetings then what you think does not count (not quite true, something you write might influence the thinking of one of the worker bees who attends meetings resulting in wording in the standard).
If you really are interested in a standard then become an active member of the committee responsible for it, at least the national one and if you have the time the international one
- Committee documents can be made public.
There are no rules preventing a standards committee putting its documents on a website for Joe public to download. The issue is finding somebody willing to do the work of hosting the website (the programming language world is lucky to have Keld Simonsen) and a willingness of committee members to be open about all their documents.
Looking in from the outside it seems to me that many non-programming language committees want to maintain an aura of mystic and privileged access.
Recent Comments