Archive
Explaining the decline of German comments in LibreOffice
The LibreOffice suite of office programs traces it origins back to StarWriter, first launched in 1985 by a German company. Given its German parentage it’s no surprise that the source code contains comments written in German.
There has been a push by the LibreOffice folks to convert the German comments to English comments. The plot below shows the number of German comments in the source of LibreOffice over time (release version numbers at the top and red line is the least squares fit of an exponential; code and data).
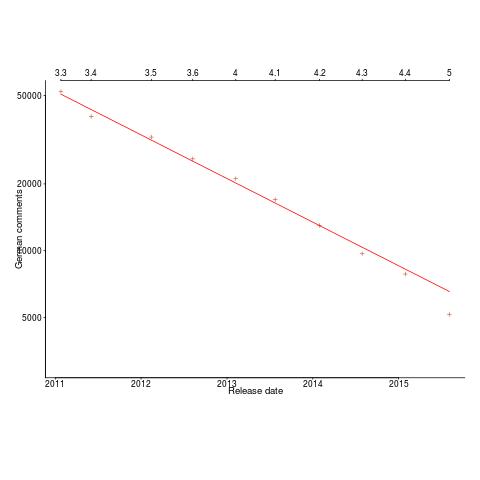
I am not only surprised to see such a regular decline in the number of German comments, but also that the decline is exponential.
The pattern of behavior may be driven by those doing the work:
- people may be motivated by the number of remaining German comments; as the number decreases, people may be less likely to think it is worthwhile converting what is left,
- perhaps those doing the conversion say to themselves: “I will do x% of the comments and then stop”. Having decided on this approach, there would have to be some form of signaling to other involved parties, otherwise the rate of decline would not be so smooth.
Perhaps the issue is the skill required to convert the comments:
- perhaps many comments are easy to convert, with the conversion process getting progressively harder, e.g., exponentially so with those doing the conversion have roughly the same conversion skill level,
- alternatively the skill required to convert the comments is roughly the same, but the number of people, of those doing the work, with a given skill level is an exponential.
I find it hard to believe any of these mechanisms. Suggestions for easier to believe mechanisms welcome.
The most worthwhile R coding guidelines I know
Since my post questioning whether native R usage exists (e.g., a common set of R coding patterns) several people have asked about coding/style guidelines for R. My approach to style/coding guidelines is economic, adhering to a guideline involves paying a cost now for some future benefit. Obviously to be worthwhile the benefit must be greater than the cost, there is also the issue of who pays the cost and who reaps the benefit (why would anybody pay the cost if somebody else reaps the benefit?). The following three topics are probably where the biggest benefits are to be had and only the third is specific to R (and given the state of my R knowledge may be wrong).
Comment your code. Investing 5-10 seconds per few lines of code now could save substantially more time at some future date. Effective commenting is a skill that has to be learned, start learning now. Think of commenting as sending a text message or tweet to the person you will be in 6 months time (i.e., the person who can hum the tune but has forgotten the details).
Consistently use variable names that mean something to you. This should be a sub 2-second decision that is probably going to save you no more than 5-10 seconds, but in many cases you reap the benefit soon after the investment, without having to wait many months. Names evoke associations in your mind, take advantage of this associative lookup to reduce the cognitive load of working with your code. Effective naming is a skill that has to be learned, start learning now. There are people who ignore the evidence that different people’s linguistic preferences and associations can be very different and insist that everybody adhere to one particular naming convention; ignore them.
Code organization and structure. Experience shows that there are ways of organizing and structuring +1,000 line programs that have a significant impact on the effort needed to actively work on the code, the more code there is the greater the impact. R programs tend to be short, say around 100 lines (I dare say much longer ones exist). Apart from recommending that code be broken up into separate functions, I cannot think of any organizational/structural issue that is worth recommending for 100 lines of code (if you don’t appreciate the advantage of using separate functions you need some hands on training, not words in a blog post).
Is that it, are there no other worthwhile recommendations? There might be, I just don’t have enough experience using R to know. Does anybody else have enough experience to know? I suspect not; where would they have gotten the information needed to do the cost/benefit analysis? Even in the rare case where a detailed analysis is made for a language the results are rather thin on the ground and somewhat inconclusive.
What is the reason behind those R style guides/coding guideline documents that have been written? The following are some possibilities:
- reducing maintenance costs (the official reason touted by purveyors of received wisdom): this is a very good reason that is let down by the complete lack of any empirical evidence that following any guidelines makes the slightest difference to maintenance costs. You R users are likely to have a lot more experience than me dealing with people claiming stuff for which no there is evidence and I will not presume to suggest how you might handle such claims (if somebody does show you some good data do please send me a copy),
- marketing (sometimes openly given as a reason): managers like to tell + customers like to hear about the existence of such a document and its role in ensuring delivery of a quality product. If you are being shown around a company and are told that they follow some style guideline its always interesting to see what happens when you ask to see a copy of this guideline document, e.g., not being able to find a copy is a surprisingly common occurrence.
- fashion (rarely admitted to): behaving like a herd and following trend setters is a common human trait, not only are there lots of ways of designing clothes but there are lots of ways in which code can be written. What kind of manager wants to have unfashionable developers working for them and who wouldn’t like to take a few days off to attend a boutique conference or chat to a friendly uncle (these guys can be messianic speakers and questioning them about lack of evidence can draw a negative response from the crowd).
and no, I don’t have any empirical data to backup my guidelines 🙁
Does the Climategate code produce reliable output?
The source of several rather important commercial programs have been made public recently, or to be more exact programs whose output is important (i.e., the Sequoia voting system and code and data from the Climate Research Unit at University of East Anglia the so called ‘Climategate’ leak). While many technical commentators have expressed amazement at how amateurish the programming appears to be, apparently written with little knowledge of good software engineering practices or knowledge of the programming language being used, those who work on commercial projects know that low levels of software engineering/programming competence is the norm.
The emails included in the Climategate leak provide another vivid example, if one were needed, of why scientific data should be made publicly available; scientists are human and are sometimes willing to hide data that does not fit their pet theory or even fails to validate their theory at all.
The Climategate source has only only recently become available and existing technical commentary has been derived from embarassing comments and the usual complaint about not using the right programming language (Fortran is actually a good choice of language for this problem, it is widely used by climatology researchers and a non-professional programmer is probably makes best of their time by using the one language they know tolerably well rather than attempting to use a new language that nobody else in the research group knows).
An important quality indicator of the leaked software was what was not there, test cases (at least I could not find any). How do we know that a program’s output is correct? One way to gain some confidence in a program’s correctness is to process data for which the correct output is known. This blindness to the importance of program level correctness testing is something that I often encounter in people who are subject area experts rather than professional programmers; they believe that if the output has the form they are expecting it must be correct and will sometimes add ‘faults’ to ‘fix’ output that deviates from what they are expecting.
A quick visual scan through the source showed a tale of two worlds, one of single letter identifier names and liberal use of goto, and the other of what looks like meaningful names, structured code and a non-trivial number of comments. The individuals who have contributed to the code base obviously have very different levels of coding ability. Not having written any Fortran in anger for over 15 years my ability to estimate the impact of more subtle coding practices has atrophied.
What kind of faults might a code review look for in these programs? Common coding errors such as using uninitialized variables and incorrect argument passing are obvious choices and their are tools available to check for these kinds of error. A much more insidious kind of error, which requires people with the mathematical expertise to spot, is created by the approximate nature of floating-point arithmetic.
The source is not huge, but not small either, consisting of around 64,000 lines of Fortran and 16,000 lines of IDL (a language designed for interactive data analysis which to my untrained eye looks a lot like MATLAB). There was no obvious support for building the source included within the leaked files (e.g., no makefiles) and my attempt to manually compile using the GNU Fortran compiler failed miserably. So I cannot say anything reliable about the compiler output warnings.
To me the complete lack of test cases implies that the Climategate code does not produce reliable output. Comments in the code such as ***** APPLIES A VERY ARTIFICIAL CORRECTION FOR DECLINE********* suggests that the authors were willing to patch the code to produce output that matched their expectations; this is the mentality of somebody for whom code correctness is not an important issue and if they don’t believe their code is correct then I don’t either.
Source code in itself is rarely that important, although it might have been expensive to create. The real important information in the leaked files is the climate data. Now that this is available others can apply their analysis skills to provide an interpretation to what, if anything statistically reliable, it is telling us.
Using third party measurement data
Until today, to the best of my knowledge, all the source code analysis papers I have read were written by researchers who had control of the code analysis tools they used and had some form of localised access to the source. By control of the code analysis tools I mean that the researchers specified the tool options and had the ability to check the behavior of the tool, in many cases the source of the tool was available to them and often even written by them, and the localised access may have involved downloading lots of code from the web.
I have just been reading about a broad brush analysis of comment usage based on data provided by a commercial code repository that offers API access to some basic code metrics.
At first, I was very frustrated by the lack of depth to the analysis provided in the paper, but then I realised that the authors’ intent was to investigate a few broad ideas about comment usage in a large number of projects (around 10,000). The authors complained in their blog about some of the referees comments and having to submit a shorter paper. I can see where the referees are coming from, the papers are lacking in depth of analysis, but they do contain some interesting results.
I was very interested in Figure 2:
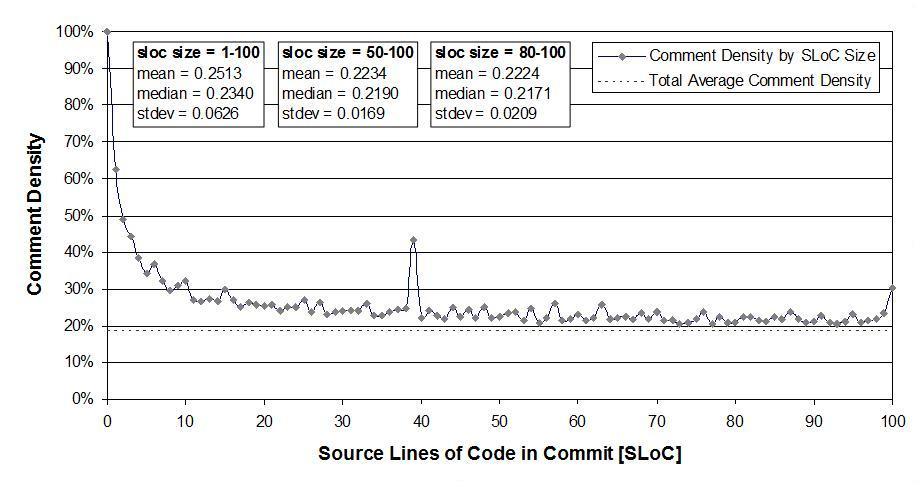
which plots the comment density of the lines in a source code commit. I would expect the ratio to be higher for small commits because a developer probably has a relatively fixed amount to say about updates involving a smallish number of lines (which probably fixes a problem). Larger commits are probably updated functionality and so would have a comment density similar to the ‘average’.
The problem with relying on third parties to supply the data is that obtaining the answers to follow up questions invariably involves lots of work, e.g., creating an environment to perform the measurements needed for the follow-up questions. However, the third party approach can significantly reduce the amount of work needed to get to a point where the interestingness of the results can be gauged.
Unexpected experimental effects
The only way to find out the factors that effect developers’ source code performance is to carry out experiments where they are the subjects. Developer performance on even simple programming tasks can be effected by a large number of different factors. People are always surprised at the very small number of basic operations I ask developers to perform in the experiments I run. My reply is that only by minimizing the number of factors that might effect performance can I have any degree of certainty that the results for the factors I am interested in are reliable.
Even with what appear to be trivial tasks I am constantly surprised by the factors that need to be controlled. A good example is one of the first experiments I ever ran. I thought it would be a good idea to replicate, using a software development context, a widely studied and reliably replicated human psychological effect; when asked to learn and later recall/recognize a list of words people make mistakes. Psychologists study this problem because it provides a window into the operation structure of the human memory subsystem over short periods of time (of the order of at most tens of seconds). I wanted to find out what sort of mistakes developers would make when asked to remember information about a sequence of simple assignment statements (e.g., qbt = 6;).
I carefully read the appropriate experimental papers and had created lists of variables that controlled for every significant factor (e.g., number of syllables, frequency of occurrence of the words in current English usage {performance is better for very common words}) and the list of assignment statements was sufficiently long that it would just overload the capacity of short term memory (about 2 seconds worth of sound).
The results contained none of the expected performance effects, so I ran the experiment again looking for different effects; nothing. A chance comment by one of the subjects after taking part in the experiment offered one reason why the expected performance effects had not been seen. By their nature developers are problem solvers and I had set them a problem that asked them to remember information involving a list of assignment statements that appeared to be beyond their short term memory capacity. Problem solvers naturally look for patterns and common cases and the variables in each of my carefully created list of assignment statements could all be distinguished by their first letter. Subjects did not need to remember the complete variable name, they just needed to remember the first letter (something I had not controlled for). Asking around I found that several other subjects had spotted and used the same strategy. My simple experiment was not simple enough!
I was recently reading about an experiment that investigated the factors that motivate developers to comment code. Subjects were given some code and asked to add additional functionality to it. Some subjects were given code containing lots of comments while others were given code containing few comments. The hypothesis was that developers were more likely to create comments in code that already contained lots of comments, and the results seemed to bear this out. However, closer examination of the answers showed that most subjects had cut and pasted chunks (i.e., code and comments) from the code they were given. So code the percentage of code in the problem answered mimicked that in the original code (in some cases subjects had complicated the situation by refactoring the code).
The sound of code
Speech, it is claimed, is the ability that separates humans from all other animals, yet working with code is almost exclusively based on sight. There are instances of ‘accidental’ uses of sound, e.g., listening to disc activity to monitor a programs process or in days of old the chatter of other mechanical parts.
Various projects have attempted to intentionally make use of sound to provide an interface to the software development process, including:
- People like to talk about what they do and perhaps this could be used to overcome developers dislike of writing comments. Unfortunately automated processing of natural language (assuming the speech to text problem is solved) has not reached the stage where it is possible to automatically detect when the topic of conversation has changed or to figure out what piece of code is being discussed. Perhaps the reason why developers find it so hard to write good comments is because it is a skill that requires training and effort, not random thoughts that happen to come to mind.
- Rather than relying on the side-effects of mechanical vibration it has been proposed that programs intentionally produce audio output that aids developers monitor their progress. Your authors experience with interpreting mechanically generated sound is that it requires a great deal of understanding of a program’s behavior and that it is a very low bandwidth information channel.
- Writing code by talking (i.e., voice input of source code) initially sounds attractive. As a form of input speech is faster than typing, however computer processing of speech is still painfully slow. Another problem that needs to be handled is the large number of different ways in which the same thing can and is spoken, e.g., numeric values. As a method of output reading is 70% faster than listening.
Unless developers have to spend lots of time commuting in person, rather than telecommuting, I don’ see a future for speech input of code. Audio program execution monitoring probably has market is specialist niches, no more.
I do see a future for spoken mathematics, which is something that people who are not a mathematicians might want to do. The necessary formating commands are sufficiently obtuse that they require too much effort from the casual user.
The 30% of source that is ignored
Approximately 30% of source code is not checked for correct syntax (developers can make up any rules they like for its internal syntax), semantic accuracy or consistency; people are content to shrug their shoulders at this this state of affairs and are generally willing to let it pass. I am of course talking about comments; the 30% figure comes from my own measurements with other published measurements falling within a similar ballpark.
Part of the problem is that comments often contain lots of natural language (i.e., human not computer language) and this is known to be very difficult to parse and is thought to be unusable without all sorts of semantic knowledge that is not currently available in machine processable form.
People are good at spotting patterns in ambiguous human communication and deducing possible meanings from it, and this has helped to keep comment usage alive, along with the fact that the information they provide is not usually available elsewhere and comments are right there in front of the person reading the code and of course management loves them as a measurable attribute that is cheap to do and not easily checkable (and what difference does it make if they don’t stay in sync with the code).
One study that did attempt to parse English sentences in comments found that 75% of sentence-style comments were in the past tense, with 55% being some kind of operational description (e.g., “This routine reads the data.”) and 44% having the style of a definition (e.g., “General matrix”).
There is a growing collection of tools for processing natural language (well at least for English). However, given the traditionally poor punctuation used in comments, the use of variable names and very domain specific terminology, full blown English parsing is likely to be very difficult. Some recent research has found that useful information can be extracted using something only a little more linguistically sophisticated than word sense disambiguation.
The designers of the iComment system sensibly limited the analysis domain (to memory/file lock related activities), simplified the parsing requirements (to looking for limited forms of requirements wording) and kept developers in the loop for some of the processing (e.g., listing lock related function names). The aim was to find inconsistencies between the requirements expressed in comments and what the code actually did. Within the Linux/Mozilla/Wine/Apache sources they found 33 faults in the code and 27 in the comments, claiming a 38.8% false positive rate.
If these impressive figures can be replicated for other kinds of coding constructs then comment contents will start to leave the dark ages.
Performance impact of comments on tasks taking a few minutes
How cost-effective is an investment in commenting code?
Answering this question requires knowing the time needed to write the comment and the time they save for later readers of the code.
A recent study investigated the impact of comments in small programming tasks on developer performance, and Sebastian Nielebock, the first author, kindly sent me a copy of the data.
How might the performance impact of comments be measured?
The obvious answer is to ask subjects to solve a coding problem, with half the subjects working with code containing comments and the other half the same code without the comments. This study used three kinds of commenting: No comments, Implementation comments and Documentation comments; the source was in Java.
Were the comments in the experiment useful, in the sense of providing information that was likely to save readers some time? A preliminary run was used to check that the comments provided some benefit.
The experiment was designed to be short enough that most subjects could complete it in less than an hour (average time to complete all tasks was 31 minutes). My own experience with running experiments is that it is possible to get professional developers to donate an hour of their time.
What is a realistic and experimentally useful amount of work to ask developers to in an hour?
The authors asked subjects to complete 9-tasks; three each of applying the code (i.e., use the code’s API), fix a bug in the code, and extend the code. Would a longer version of one of each, rather than a shorter three of each been better? I think the only way to find out is to try it both ways (I hope the authors plan to do another version).
What were the results (code+data)?
Regular readers will know, from other posts discussing experiments, that the biggest factor is likely to be subject (professional developers+students) differences, and this is true here.
Based on a fitted regression model, Documentation comments slowed performance on a task by 30 seconds, compared to No comments and Implementation comments (which both had the same performance impact). Given that average task completion time was 205 seconds, this is a 15% slowdown for Documentation comments.
This study set out to measure the performance impact of comments on small programming tasks. The answer, at least for tasks designed to take a few minutes, is that No comments, or if comments are required, then write Implementation comments.
This experiment measured the performance impact of comments on developers who did not write the code containing them. These developers have to first read and understand the comments (which takes time). However, the evidence suggests that code is mostly modified by the developer who wrote it (just reading the code does not leave a record that can be analysed). In this case, the reading a comment (that the developer previously wrote) can trigger existing memories, i.e., it has a greater information content for the original author.
Will comments have a bigger impact when read by the person who wrote them (and the code), or on tasks taking more than a few minutes? I await the results of more experiments…
Update: I have updated the script based on feedback about the data from Sebastian Nielebock.