Archive
Deciding whether a conclusion is possible or necessary
Psychologists studying human reasoning have primarily focused on syllogistic reasoning, i.e., the truthfulness of a necessary conclusion from two stated premises, as in the following famous example:
All men are mortal.
Socrates is a man.
Therefore, Socrates is mortal. |
Another form of reasoning is modal reasoning, which deals with possibilities and necessities; for example:
All programmers like jelly beans,
Tom likes jelly beans,
Therefore, it is possible Tom is a programmer. |
Possibilities and necessities are fundamental to creating software. I would argue (without evidence) that possibility situations occur much more frequently during software development than necessarily situations.
What is the coding impact of incorrect Possible/Necessary decisions (the believability of a syllogism has been found to influence subject performance)?
- Conclusion treated as possible, while being necessary: A possibility involves two states, while necessity is a single state. A possible condition implies coding an
if/else(or perhaps one arm of anif), while a necessary condition is at most one arm of anif(or perhaps nothing).The likely end result of making this incorrect decision is some dead code.
- Conclusion treated as necessary, while being possible: Here two states are considered to be a single state.
The likely end result of making this incorrect decision is incorrect code.
What have the psychology studies found?
The 1999 paper: Reasoning About Necessity and Possibility: A Test of the Mental Model Theory of Deduction by J. St. B. T. Evans, S. J. Handley, C. N. J. Harper, and P. N. Johnson-Laird, experimentally studied three predictions (slightly edited for readability):
- People are more willing to endorse conclusions as Possible than as Necessary.
- It is easier to decide that a conclusion is Possible if it is also Necessary. Specifically, we predict more endorsements of Possible for Necessary than for Possible problems.
- It is easier to decide that a conclusion is not Necessary if it is also not Possible. Specifically, we predict that more Possible than Impossible problems will be endorsed as Necessary.
Less effort is required to decide that a conclusion is Possible because just one case needs to be found, while making a Necessary decision requires evaluating all cases.
In one experiment, subjects (120 undergraduates studying psychology) saw a screen containing a question such as the following (an equal number of questions involved NECESSARY/POSSIBLE):
GIVEN THAT
Some A are B
IS IT NECESSARY THAT
Some B are not A |
Subjects saw each of the 28 possible combinations of four Premises and seven Conclusions. The table below shows eight combinations of the four Premises and seven conclusions, the Logic column shows the answer (N=Necessary; I=Impossible; P=Possible), and the Necessary/Possible columns show the number of subjects answering that the conclusion was Necessary/Possible:
Premise Conclusion Logic Necessary Possible All A are B Some A are B N 65 82 All A are B No A are B I 3 12 Some A are B All A are B P 3 53 Some A are B No A are B I 8 55 No A are B Some A are not B N 77 80 No A are B No B are A I 7 25 Some A are not B All A are B I 2 3 Some A are not B Some B are A P 70 95 |
The table below shows the percentage of answer specifying that the conclusion was Necessary/Possible (2nd/3rd rows), when the Logical answer was one of Impossible/Necessary/Possible (code+data):
Logic I N P
N 8% 59% 38%
P 19% 71% 60% |
The percentage of Possible answers is always much higher than Necessary answers (when a Conclusion is Necessary, it is also Possible), even when the Conclusion is Impossible. The 38% of Necessary answers for when the Conclusion is only Possible is somewhat concerning, as this decision could produce coding mistakes.
The paper ran a second experiment involving two premises, like the Jelly bean example, attempting to distinguish strong/weak forms of Possible.
Do these results replicate?
The 2024 study Necessity, Possibility and Likelihood in Syllogistic Reasoning by D. Brand, S. Todorovikj, and M. Ragni, replicated the results. This study also investigated the effect of using Likely, as well as Possible/Necessary. The results showed that responses for Likely suggested it was a middle ground between Possible/Necessary.
After writing the above, I asked Grok: list papers that have studied the use of syllogistic reasoning by software developers: nothing software specific. The same question for modal reasoning returned answers on the use of Modal logic, i.e., different subject. Grok did a great job of summarising the appropriate material in my Evidence-base Software Engineering book.
Polished human cognitive characteristics chapter
It has been just over two years since I release the first draft of the Human cognitive characteristics chapter of my evidence-based software engineering book. As new material was discovered, it got added where it seemed to belong (at the time), no effort was invested in maintaining any degree of coherence.
The plan was to find enough material to paint a coherence picture of the impact of human cognitive characteristics on software engineering. In practice, finishing the book in a reasonable time-frame requires that I stop looking for new material (assuming it exists), and go with what is currently available. There are a few datasets that have been promised, and having these would help fill some holes in the later sections.
The material has been reorganized into what is essentially a pass over what I think are the major issues, discussed via studies for which I have data (the rule of requiring data for a topic to be discussed, gets bent out of shape the most in this chapter), presented in almost a bullet point-like style. At least there are plenty of figures for people to look at, and they are in color.
I think the material will convince readers that human cognition is a crucial topic in software development; download the draft pdf.
Model building by cognitive psychologists is starting to become popular, with probabilistic languages, such as JAGS and Stan, becoming widely used. I was hoping to build models like this for software engineering tasks, but it would have taken too much time, and will have to wait until the book is done.
As always, if you know of any interesting software engineering data, please let me know.
Next, the cognitive capitalism chapter.
Practical psychology books for software engineers
So you have read my (draft) book on evidence-based software engineering and want to learn more about human psychology. What books do I suggest?
I wrote a book about C that attempted to use results from cognitive psychology to understand developer characteristics. This work dates from around 2000, and some of my book choices may have been different, had I studied the subject 10 years later. Another consequence is that this list is very weak on social psychology.
I own all the following books, but it may have been a few years since I last took them off the shelf.
There are two very good books providing a broad introduction: “Cognitive psychology and its implications” by Anderson, and “Cognitive psychology: A student’s handbook” by Eysenck and Keane. They have both been through many editions, and buying a copy that is a few editions earlier than current, saves money for little loss of content.
“Engineering psychology and human performance” by Wickens and Hollands, is a general introduction oriented towards stuff that engineering requires people to do.
Brain functioning: “Reading in the brain” by Dehaene (a bit harder going than “The number sense”). For those who want to get down among the neurons “Biological psychology” by Kalat.
Consciouness: This issue always comes up, so let’s kill it here and now: “The illusion of conscious will” by Wegner, and “The mind is flat” by Chater.
Decision making: What is the difference between decision making and reasoning? In psychology those with a practical orientation study decision making, while those into mathematical logic study reasoning. “Rational choice in an uncertain world” by Hastie and Dawes, is a general introduction; “The adaptive decision maker” by Payne, Bettman and Johnson, is a readable discussion of decision making models. “Judgment under Uncertainty: Heuristics and Biases” by Kahneman, Slovic and Tversky, is a famous collection of papers that kick started the field at the start of the 1980s.
Evolutionary psychology: “Human evolutionary psychology” by Barrett, Dunbar and Lycett. How did we get to be the way we are? Watch out for the hand waving (bones can be dug up for study, but not the software of our mind), but it weaves a coherent’ish story. If you want to go deeper, “The Adapted Mind: Evolutionary Psychology and the Generation of Culture” by Barkow, Tooby and Cosmides, is a collection of papers that took the world by storm at the start of the 1990s.
Language: “The psychology of language” by Harley, is the book to read on psycholinguistics; it is engrossing (although I have not read the latest edition).
Memory: I have almost a dozen books discussing memory. What these say is that there are a collection of memory systems having various characteristics; which is what the chapters in the general coverage books say.
Modeling: So you want to model the human brain. ACT-R is the market leader in general cognitive modeling. “Bayesian cognitive modeling” by Lee and Wagenmakers, is a good introduction for those who prefer a more abstract approach (“Computational modeling of cognition” by Farrell and Lewandowsky, is a big disappointment {they have written some great papers} and best avoided).
Reasoning: The study of reasoning is something of a backwater in psychology. Early experiments showed that people did not reason according to the rules of mathematical logic, and this was treated as a serious fault (whose fault it was, shifted around). Eventually most researchers realised that the purpose of reasoning was to aid survival and reproduction, not following the recently (100 years or so) invented rules of mathematical logic (a few die-hards continue to cling to the belief that human reasoning has a strong connection to mathematical logic, e.g., Evans and Johnson-Laird; I have nearly all their books, but have not inflicted them on the local charity shop yet). Gigerenzer has written several good books: “Adaptive thinking: Rationality in the real world” is a readable introduction, also “Simple heuristics that make us smart”.
Social psychology: “Social learning” by Hoppitt and Laland, analyzes the advantages and disadvantages of social learning; “The Secret of Our Success: How Culture Is Driving Human Evolution, Domesticating Our Species, and Making Us Smarter” by Henrich, is a more populist book (by a leader in the field).
Vision: “Visual intelligence” by Hoffman is a readable introduction to how we go about interpreting the photons entering our eyes, while “Graph design for the eye and mind” by Kosslyn is a rule based guide to visual presentation. “Vision science: Photons to phenomenology” by Palmer, for those who are really keen.
Several good books have probably been omitted, because I failed to spot them sitting on the shelf. Suggestions for books covering topics I have missed welcome, or your own preferences.
Ability to remember code improves with experience
What mental abilities separate an expert from a beginner?
In the 1940s de Groot studied expertise in Chess. Players were shown a chess board containing various pieces and then asked to recall the locations of the pieces. When the location of the chess pieces was consistent with a likely game, experts significantly outperformed beginners in correct recall of piece location, but when the pieces were placed at random there was little difference in recall performance between experts and beginners. Also players having the rank of Master were able to reconstruct the positions almost perfectly after viewing the board for just 5 seconds; a recall performance that dropped off sharply with chess ranking.
The interpretation of these results (which have been duplicated in other areas) is that experts have learned how to process and organize information (in their field) as chunks, allowing them to meaningfully structure and interpret board positions; beginners don’t have this ability to organize information and are forced to remember individual pieces.
In 1981 McKeithen, Reitman, Rueter and Hirtle repeated this experiment, but this time using 31 lines of code and programmers of various skill levels. Subjects were given two minutes to study 31 lines of code, followed by three minutes to write (on a blank sheet of paper) all the code they could recall; this process was repeated five times (for the same code). The plot below shows the number of lines correctly recalled by experts (2,000+ hours programming experience), intermediates (just finished programming course) and beginners (just started programming course), left performance using ‘normal’ code and right is performance viewing code created by randomizing lines from ‘normal’ code; only the mean values in each category are available (code+data):
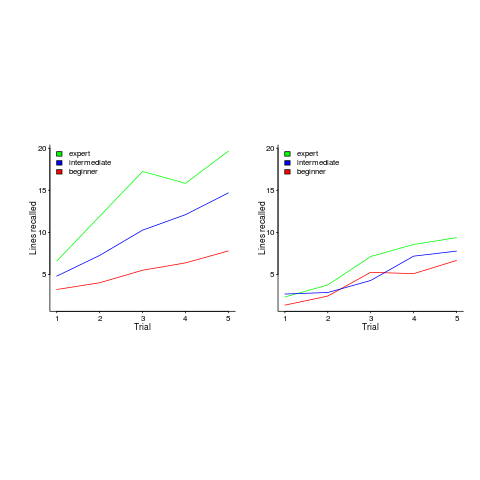
Experts start off remembering more than beginners and their performance improves faster with practice.
Compared to the Power law of practice (where experts should not get a lot better, but beginners should improve a lot), this technique is a much less time consuming way of telling if somebody is an expert or beginner; it also has the advantage of not requiring any application domain knowledge.
If you have 30 minutes to spare, why not test your ‘expertise’ on this code (the .c file, not the .R file that plotted the figure above). It’s 40 odd lines of C from the Linux kernel. I picked C because people who know C++, Java, PHP, etc should have no trouble using existing skills to remember it. What to do:
- You need five blank sheets of paper, a pen, a timer and a way of viewing/not viewing the code,
- view the code for 2 minutes,
- spend 3 minutes writing down what you remember on a clean sheet of paper,
- repeat until done 5 times.
Count how many lines you correctly wrote down for each iteration (let’s not get too fussed about exact indentation when comparing) and send these counts to me (derek at the primary domain used for this blog), plus some basic information on your experience (say years coding in language X, years in Y). It’s anonymous, so don’t include any identifying information.
I will wait a few weeks and then write up the data o this blog, as well as sharing the data.
Update: The first bug in the experiment has been reported. It takes longer than 3 minutes to write out all the code. Options are to stick with the 3 minutes or to spend more time writing. I will leave the choice up to you. In a test situation, maximum time is likely to be fixed, but if you have the time and want to find out how much you remember, go for it.
My R naming nemesis
When learning a new language I try to make an effort to write it like a native developer. R has one language feature that has been severely testing my desire to write like a native and this afternoon I realized that most of the people reading my code will also experience the same jarring sensation on encountering this construct, so I am not going to use it any more.
What is this language feature that induces a Stroop effect in my mind? It is the use of the period character as part of an identifier’s name (e.g., foo.bar). In almost all of the hundreds of thousands of lines of code I have read over the years this character is used as an operator, it selects a member/field of a struct/record. I’m sure that if I tried long enough and hard enough I could get used to using this character being part of an identifier; after a year or so writing Cobol I got used to the arithmetic minus character being permitted within identifiers (e.g., foo-bar), but that was 20 years ago and my neurons will probably take much longer to adapt this time around.
Most of the R I am writing will be distributed with my book Empirical software engineering with R and I think readers will experience the same jarring sensation I do (apart from those who have not yet been exposed to large amounts of non-R code). I have convinced myself that this is a good enough reason to give up trying to figure out how to use . in identifier name (I have been concocting all sorts of rules involving . being used to separate the primary part of the name and _ the secondary parts, e.g., total.red_light [yes, I should get out more often]; the underscore vs. camel case debate still erupts every now and again, let’s avoid creating more debate by introducing more choice).
Those R functions that include a . in their name will stand out from the crowd, [arm waving on] perhaps this will help differentiate them as ‘statistics stuff'[arm waving off]. There is always plan B if my unilateral naming decision looks too unilateral, a global renaming script.
Perhaps the use of periods in identifiers can be used as a test for being a native R developer. A simple timing test involving a sequence of characters appears on a screen with the developer having to respond as quickly as possible on the number of identifiers being displayed; I’m sure I would be much slower to give a ‘1’ response to total.count than to total_count, displaying total count and total.count on twp separate lines and asking me to quickly specify which line contained the most identifiers would turn me into a nervous wreck. Responses from a dozen or so different sequences ought to be enough be able to distinguish Jonny foreigner from the natives.
I don’t have a problem with $, which R uses as the column/list item selection operator, a character permitted by some compilers for commonly used languages as part of an identifier. This is because I have not read lots of code containing this identifier naming usage.
For my previous book I did a survey of the linguistic and cognitive psychology issues involved in identifier naming. This did a good job of debunking existing ideas about what constitutes good naming practices, but did not come up with any concrete recommendations to replace them (nature abhors a vacuum and the existing pop psychology naming ideas remained).
These days people write PhDs on identifier naming issues (method names, (not yet completed) correlation with quality and code comprehension to name a few); there is even a subfield within this field, how best to split an identifier into its component parts (e.g., refPtr is probably an abbreviation of reference pointer).
Correlation between risk attitude and willingness to refer back
What is the connection between a software developer’s risk attitude and the faults they insert in code they write or fail to detect in code they review? This is a very complicated question and in an experiment performed at the 2011 ACCU conference I investigated one particular instance; the connection between risk attitude and recall of previously seen information.
The experiment consisted of a series of problems having the same format (the identifiers used varied between problems). Each problem involved remembering information on four assignment statements of the form:
p = 6 ; b = 4 ; r = 9 ; k = 8 ; |
performing some other unrelated task for a short time (hopefully long enough for them to forget some of the information they had previously seen) and then having to recognize the variables they had previously seen within a list containing five identifiers and recall the numeric value assigned to each variable.
When reading code developers have the option of referring back to previously read code and this option was provided to subject. Next to each identifier listed in the recall part of the problem was space to write the numeric value previously seen and a “would refer back” box. Subjects were told to tick the “would refer back” box if, in real life” they would refer back to the previously seen assignment statements rather than rely on their memory.
As originally conceived this experimental format is investigating the impact of human short term memory on recall of previously seen code. Every time I ran this kind of experiment there was a small number of subjects who gave a much higher percentage of “would refer back” answers than the other subjects. One explanation was that these subjects had a smaller short term memory capacity than other subjects (STM capacity does vary between people), another explanation is that these subjects are much more risk averse than the other subjects.
The 2011 ACCU experiment was designed to test the hypothesis that there was a correlation between a subject’s risk attitude and the percentage of “would refer back” answers they gave. The Domain-Specific Risk-Taking (DOSPERT) questionnaire was used to measure subject’s risk attitude. This questionnaire and the experimental findings behind it have been published and are freely available for others to use. DOSPERT measures risk attitude in six domains: social, recreation, gambling, investing health and ethical.
The following scatter plot shows each (of 30) subject’s risk attitude in the six domains (x-axis) plotted against percentage of “would refer back” answers (y-axis).
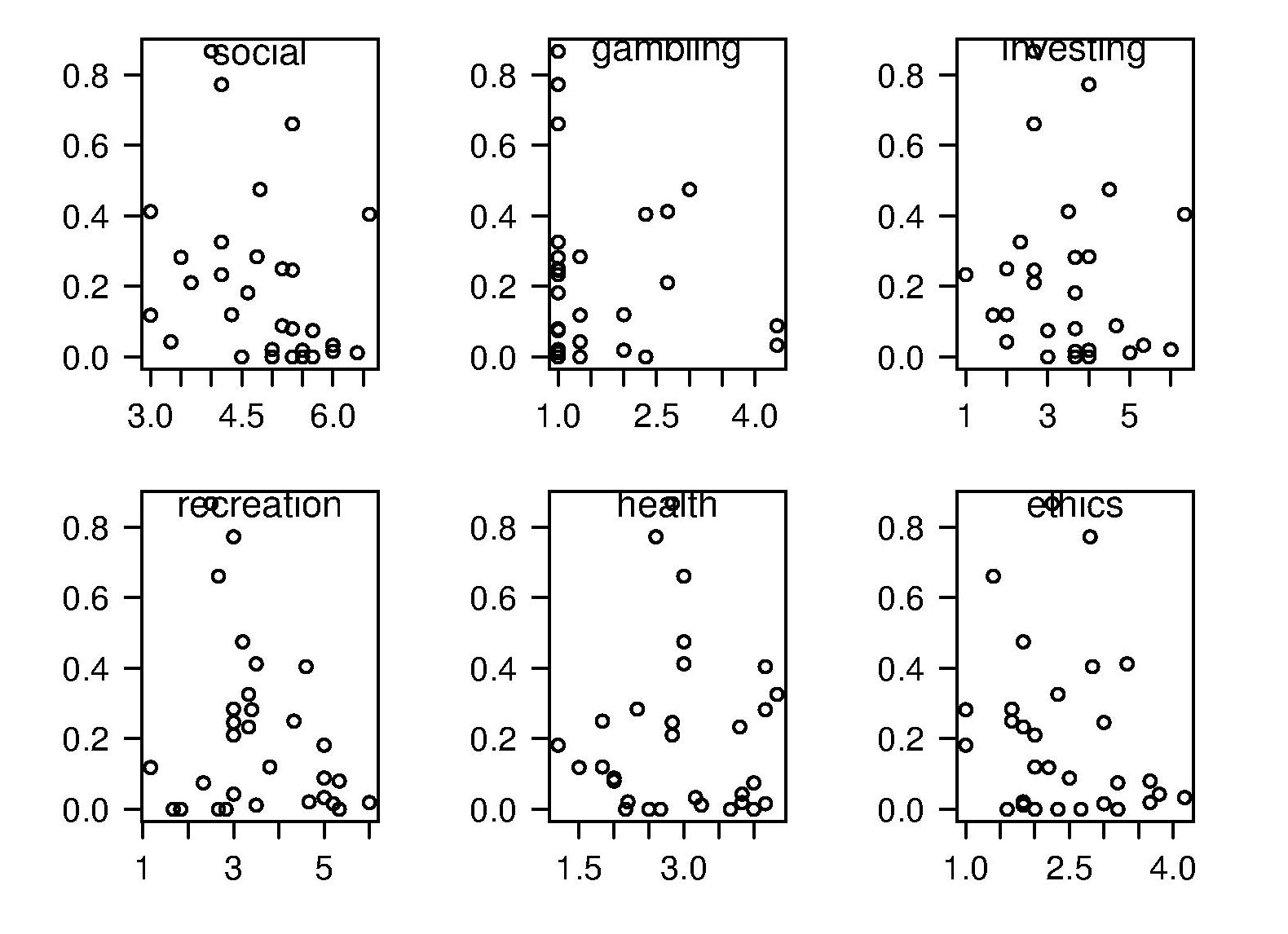
A Spearman rank correlation test confirms what is visibly apparent, there is no correlation between the two quantities. Scatter plots using percentage of correct answers and total number of questions answers show a similar lack of correlation.
The results suggest that risk attitude (at least as measured by DOSPERT) is not a measurable factor in subject recall performance. Perhaps the subjects that originally caught my attention (there were three in 2011) really do have a smaller STM capacity compared to other subjects. The organization of the experiment (one hour during a one lunchtime of the conference) does not allow for a more extensive testing of subject cognitive characteristics.
Readability: we know nothing
Readability is one of those terms that developers use and expect other developers to understand while at the same time being unable to define what it is or how it might be measured. I think all developers would agree that their own code is very readable; if only different developers stopped writing code in different ways the issue would go away 🙂
Having written a book containing lots of material on cognitive psychology and how it might apply to programming, developers who have advanced beyond “Write code like me and it will be readable” sometimes ask for my perceived expert view on the subject. Unfortunately my expertise has only advanced to the stage of: 1) having a good idea of what research questions need to be addressed, 2) being able to point at experimental results showing that most claimed good readability tips are at best worthless or may even increase cognitive load during reading.
To a good approximation we know nothing about code readability. What questions need to answered to change this situation?
The first and most important readability question is: what is the purpose of looking at the code? Is the code being read to gain understanding (likely to involve ‘slow’ and deliberate behavior) or is the reader searching for some construct (likely to involve skimming; yes, slow and deliberate is more accurate but people make cost/benefit decisions when deciding which strategies to use. The factors involved in reader strategy selection is another important question)?
Next we need to ask what characteristics of developer performance are expected to change with different code organization/layouts. Are we interested in minimizing error, minimizing the time taken to achieve the readers purpose or something else?
What source code attributes play a significant role in readability? Possibilities include the order in which various constructs appear (e.g., should variable definitions appear at the start of a function or close to where they are first used), variable names and the position of tokens relative to each other when viewed by the reader.
Questions involving the relative position of tokens probably generates the greatest volume of discussion among developers. To what extent does visual organization of source code affect reader performance? Fluent reading requires a significant amount of practice, perhaps readable code is whatever developers have spent lots of time reading.
If there is some characteristic of the human visual system that generates a worthwhile benefit to splitting long lines so that a binary operator appears at the {end of the last}/{start of the next} line, will it apply the same way to all developers? We could end up developers having to configure their editor so it displays code in a form that matches the characteristics of their visual system.
How might these ‘visual’ questions be answered? I think that eye tracking will play a large role (“Eyetracking Web Usability” by Jakob Nielsen and Kara Pernice is a good read). At the moment there are technical/usability issues that make this kind of research very difficult. Eye trackers capable of continuously supporting enough resolution to know which character on the screen a developer is looking at (e.g., EyeLink 1000) require that the head be held in a fixed position, while those allowing completely free head movement (e.g., S2 Eye Tracker) don’t yet continuously support the required resolution.
Of course any theory derived from eye tracking experiments will still have to be validated by measuring developer performance on various code snippets.
A power law artifact
Over the last few years software engineering academics have jumped aboard the power-law band-wagon (examples here and here). With few exceptions (one here) these researchers have done little more that plot their data on a log-log graph and shown that a straight line is a good fit for many of the points. What a sorry state of affairs.
Cognitive psychologists have also encountered straight lines in log-log graphs, but they have been in the analysis of data business much longer and are aware that there might be other distributions that are just as straight in the same places.
A very interesting paper, Toward an explanation of the power law artifact: Insights from response surface analysis, shows how averaging data obtained from a variety of sources (example given is the performance of different subjects in a psychology experiment) can produce a power law where none originally existed. The underlying fault could be that data from a non-linear system is being averaged using the arithmetic mean (I suspect that I have done this in the past), which it turns out should only be used to average data from a linear system. The authors list the appropriate averaging formula that should be used for various non-linear systems.
Unexpected experimental effects
The only way to find out the factors that effect developers’ source code performance is to carry out experiments where they are the subjects. Developer performance on even simple programming tasks can be effected by a large number of different factors. People are always surprised at the very small number of basic operations I ask developers to perform in the experiments I run. My reply is that only by minimizing the number of factors that might effect performance can I have any degree of certainty that the results for the factors I am interested in are reliable.
Even with what appear to be trivial tasks I am constantly surprised by the factors that need to be controlled. A good example is one of the first experiments I ever ran. I thought it would be a good idea to replicate, using a software development context, a widely studied and reliably replicated human psychological effect; when asked to learn and later recall/recognize a list of words people make mistakes. Psychologists study this problem because it provides a window into the operation structure of the human memory subsystem over short periods of time (of the order of at most tens of seconds). I wanted to find out what sort of mistakes developers would make when asked to remember information about a sequence of simple assignment statements (e.g.,
qbt = 6;).I carefully read the appropriate experimental papers and had created lists of variables that controlled for every significant factor (e.g., number of syllables, frequency of occurrence of the words in current English usage {performance is better for very common words}) and the list of assignment statements was sufficiently long that it would just overload the capacity of short term memory (about 2 seconds worth of sound).
The results contained none of the expected performance effects, so I ran the experiment again looking for different effects; nothing. A chance comment by one of the subjects after taking part in the experiment offered one reason why the expected performance effects had not been seen. By their nature developers are problem solvers and I had set them a problem that asked them to remember information involving a list of assignment statements that appeared to be beyond their short term memory capacity. Problem solvers naturally look for patterns and common cases and the variables in each of my carefully created list of assignment statements could all be distinguished by their first letter. Subjects did not need to remember the complete variable name, they just needed to remember the first letter (something I had not controlled for). Asking around I found that several other subjects had spotted and used the same strategy. My simple experiment was not simple enough!
I was recently reading about an experiment that investigated the factors that motivate developers to comment code. Subjects were given some code and asked to add additional functionality to it. Some subjects were given code containing lots of comments while others were given code containing few comments. The hypothesis was that developers were more likely to create comments in code that already contained lots of comments, and the results seemed to bear this out. However, closer examination of the answers showed that most subjects had cut and pasted chunks (i.e., code and comments) from the code they were given. So code the percentage of code in the problem answered mimicked that in the original code (in some cases subjects had complicated the situation by refactoring the code).