Archive
semgrep: the future of static analysis tools
When searching for a pattern that might be present in source code contained in multiple files, what is the best tool to use?
The obvious answer is grep, and grep is great for character-based pattern searches. But patterns that are token based, or include information on language semantics, fall outside grep‘s model of pattern recognition (which does not stop people trying to cobble something together, perhaps with the help of complicated sed scripts).
Those searching source code written in C have the luxury of being able to use Coccinelle, an industrial strength C language aware pattern matching tool. It is widely used by the Linux kernel maintainers and people researching complicated source code patterns.
Over the 15+ years that Coccinelle has been available, there has been a lot of talk about supporting other languages, but nothing ever materialized.
About six months ago, I noticed semgrep and thought it interesting enough to add to my list of tool bookmarks. Then, a few days ago, I read a brief blog post that was interesting enough for me to check out other posts at that site, and this one by Yoann Padioleau really caught my attention. Yoann worked on Coccinelle, and we had an interesting email exchange some 13-years ago, when I was analyzing if-statement usage, and had subsequently worked on various static analysis tools, and was now working on semgrep. Most static analysis tools are created by somebody spending a year or so working on the implementation, making all the usual mistakes, before abandoning it to go off and do other things. High quality tools come from people with experience, who have invested lots of time learning their trade.
The documentation contains lots of examples, and working on the assumption that things would be a lot like using Coccinelle, I jumped straight in.
The pattern I choose to search for, using semgrep, involved counting the number of clauses contained in Python if-statement conditionals, e.g., the condition in: if a==1 and b==2: contains two clauses (i.e., a==1, b==2). My interest in this usage comes from ideas about if-statement nesting depth and clause complexity. The intended use case of semgrep is security researchers checking for vulnerabilities in code, but I’m sure those developing it are happy for source code researchers to use it.
As always, I first tried building the source on the Github repo, (note: the Makefile expects a git clone install, not an unzipped directory), but got fed up with having to incrementally discover and install lots of dependencies (like Coccinelle, the code is written on OCaml {93k+ lines} and Python {13k+ lines}). I joined the unwashed masses and used pip install.
The pattern rules have a yaml structure, specifying the rule name, language(s), message to output when a match is found, and the pattern to search for.
After sorting out various finger problems, writing C rather than Python, and misunderstanding the semgrep output (some of which feels like internal developer output, rather than tool user developer output), I had a set of working patterns.
The following two patterns match if-statements containing a single clause (if.subexpr-1), and two clauses (if.subexpr-2). The option commutative_boolop is set to true to allow the matching process to treat Python’s or/and as commutative, which they are not, but it reduces the number of rules that need to be written to handle all the cases when ordering of these operators is not relevant (rules+test).
rules: - id: if.subexpr-1 languages: [python] message: if-cond1 patterns: - pattern: | if $COND1: # we found an if statement $BODY - pattern-not: | if $COND2 or $COND3: # must not contain more than one condition $BODY - pattern-not: | if $COND2 and $COND3: $BODY severity: INFO - id: if.subexpr-2 languages: [python] options: commutative_boolop: true # Reduce combinatorial explosion of rules message: if-cond2 pattern-either: - patterns: - pattern: | if $COND1 or $COND2: # if statement containing two conditions $BODY - pattern-not: | if $COND3 or $COND4 or $COND5: # must not contain more than two conditions $BODY - pattern-not: | if $COND3 or $COND4 and $COND5: $BODY - patterns: - pattern: | if $COND1 and $COND2: $BODY - pattern-not: | if $COND3 and $COND4 and $COND5: $BODY - pattern-not: | if $COND3 and $COND4 or $COND5: $BODY severity: INFO |
The rules would be simpler if it were possible for a pattern to not be applied to code that earlier matched another pattern (in my example, one containing more clauses). This functionality is supported by Coccinelle, and I’m sure it will eventually appear in semgrep.
This tool has lots of rough edges, and is still rapidly evolving, I’m using version 0.82, released four days ago. What’s exciting is the support for multiple languages (ten are listed, with experimental support for twelve more, and three in beta). Roughly what happens is that source code is mapped to an abstract syntax tree that is common to all supported languages, which is then pattern matched. Supporting a new language involves writing code to perform the mapping to this common AST.
It’s not too difficult to map different languages to a common AST that contains just tokens, e.g., identifiers and their spelling, literals and their value, and keywords. Many languages use the same operator precedence and associativity as C, plus their own extras, and they tend to share the same kinds of statements; however, declarations can be very diverse, which makes life difficult for supporting a generic AST.
An awful lot of useful things can be done with a tool that is aware of expression/statement syntax and matches at the token level. More refined semantic information (e.g., a variable’s type) can be added in later versions. The extent to which an investment is made to support the various subtleties of a particular language will depend on its economic importance to those involved in supporting semgrep (Return to Corp is a VC backed company).
Outside of a few languages that have established tools doing deep semantic analysis (i.e., C and C++), semgrep has the potential to become the go-to static analysis tool for source code. It will benefit from the network effects of contributions from lots of people each working in one or more languages, taking their semgrep skills and rules from one project to another (with source code language ceasing to be a major issue). Developers using niche languages with poor or no static analysis tool support will add semgrep support for their language because it will be the lowest cost path to accessing an industrial strength tool.
How are the VC backers going to make money from funding the semgrep team? The traditional financial exit for static analysis companies is selling to a much larger company. Why would a large company buy them, when they could just fork the code (other company sales have involved closed-source tools)? Perhaps those involved think they can make money by selling services (assuming semgrep becomes the go-to tool). I have a terrible track record for making business predictions, so I will stick to the technical stuff.
Update
Parts of the semgrep source have changed from an Open source license to a commercial one.
Opengrep is an Open source fork of semgrep.
Unused function parameters
I have started redoing the source code measurements that appear in my C book, this time using a lot more source, upgraded versions of existing tools, plus some new tools such as Coccinelle and R. The intent is to make the code and data available in a form that is easy for others to use (I am hoping that one or more people will measure the same constructs in other languages) and to make some attempt at teasing out relationships in the data (previously the data was simply plotted with little or no explanation).
While it might be possible to write a paper on every language construct measured, I don’t have the time to do the work. Instead, I will use this blog to make a note of the interesting things that crop up during the analysis of each construct I measure.
First up are unused function parameters (code and data), which at around 11% of all parameters are slightly more common than unused local variables (Figure 190.1). In the following plot black circles are the total number of functions having a given number of parameters, red circles a given number of unused parameters, blue line a linear regression fit of the red circles, and the green line is derived from black circle values using a formula I concocted to fit the data and have no theoretical justification for it.
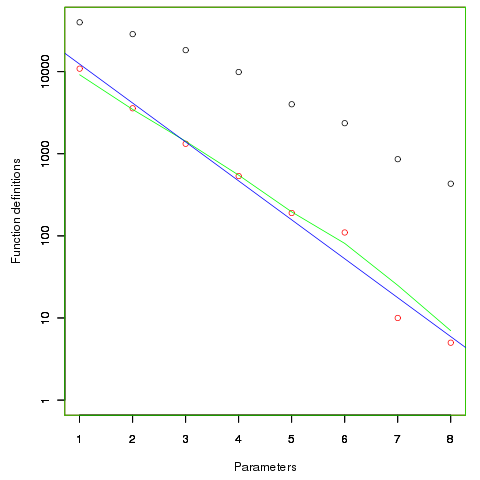
The number of functions containing a given number of unused parameters drops by around a factor of three for each additional unused parameter. Why is this? The formula I came up with for estimating the number of functions containing  unused parameters is:
unused parameters is:  , where
, where  is the total number of function definitions containing
is the total number of function definitions containing  parameters.
parameters.
Which parameter, for those functions defined with more than one, is most likely to be unused? My thinking was that the first parameter might either hold the most basic information (and so rarely be unused) or hold information likely to be superseded when new parameters are added (and so commonly be unused), either way I considered later parameters as often being put there for later use (and therefore more likely to be unused). The following plot is for eight programs plus the sum of them all; for all functions defined with between one and eight parameters, the percentage of times the  ‘th parameter is unused is given. The source measured contained 104,493 function definitions containing more than one parameter with 16,643 of these functions having one or more unused parameter, there were a total of 235,512 parameters with 25,886 parameters being unused.
‘th parameter is unused is given. The source measured contained 104,493 function definitions containing more than one parameter with 16,643 of these functions having one or more unused parameter, there were a total of 235,512 parameters with 25,886 parameters being unused.
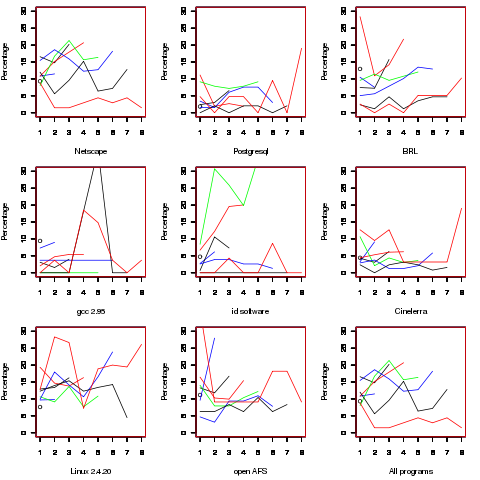
There is no obvious pattern to which parameters are likely to be unused, although a lot of the time the last parameter is more likely to be unused than the penultimate one.
Looking through the raw data I noticed that there seemed to be some clustering of names of unused parameters, in particular if the ‘th parameter was unused in two adjacent ‘unused parameter’ functions they often had the same name. The following plot is for all measured source and gives the percentage of same name occurrences; the matching process analyses function definitions in the order they occur within a source file and having found one unused parameter its name is compared against the corresponding parameter in the next function definition with the same number of parameters and having an unused parameter at the same position.
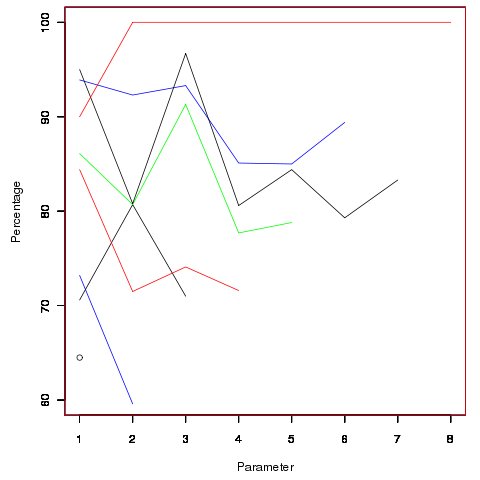
Before getting too excited about this pattern, we should ask if something similar exists for the used parameters. When I get around to redoing the general parameter measurements, I will look into this question. The numbers of occurrences for functions containing eight parameters is close to minimal.
The functions containing these same-name unused parameters appear to also have related function names. Is this a case of related function being grouped together, often sharing parameter names, and when one of them has an unused parameter the corresponding parameter in the others is also unused?
Is there a correlation between number of parameters and number of statements, are functions containing lots of statements less likely to have unused parameters? What effect does software evolution have (most of this kind of research measures executable code, not variable definitions)?
Assessing my predictions for 2009
I have been rather remiss in revisiting the predictions I made for 2009 to see how they fared. Only two out of the six predictions were sufficiently precise to enable an assessment one year later; the other four talking more about trends. What of these two predictions?
The LLVM project will die. Ok, the project is still going and at the end of December the compiler could build itself but the build is not yet in a state to self host (i.e., llvm compiler creates an executable of itself from its own source and this executable can build an executable from source that is identical to itself {modulo date/time stamps etc}). Self hosting is a major event and on some of the projects I have worked on it has been a contractual payment milestone.
Is llvm competition for gcc? While there might not be much commercial competition as such (would Apple be providing funding to gcc if it were not involved in llvm?), I’m sure that developers working on both projects want their respective compiler to be the better one. According to some llvm benchmarks they compile code twice as fast as gcc. If this performance difference holds up across lots of source how might the gcc folk respond? Is gcc compiler time performance an issue that developers care about or is quality of generated code more important? For me the latter is more important and I have not been able to find a reliable, recent, performance comparison. I understand that almost all gcc funding is targeted at code generation related development, so if compile time is an issue gcc may be in a hole.
I still don’t see the logic behind Apple funding this project and continue to think that this funding will be withdrawn sometime, perhaps I was just a year off. I do wish the llvm developers well and look forward to them celebrating a self hosted compiler.
Static analysis will go mainstream. Ok, I was overly optimistic here. There do not seem to have been any casualties in 2009 among the commercial vendors selling static analysis tools and the growth of PHP has resulted in a number of companies selling tools that scan for source security vulnerabilities (.e.g, SQL injection attacks).
I was hoping that the availability of Treehydra would spark the development of static analysis plugins for gcc. Perhaps the neatness of the idea blinded me to what I already knew; many developers dislike the warnings generated by the -Wall option and therefore might be expected to dislike any related kind of warning. One important usability issue is that Treehydra operates on the abstract syntax tree representation used internally by gcc, GIMPLE. Learning about this representation requires a big investment before a plugin developer becomes productive.
One tool that did experience a lot of growth in 2009 was Coccinelle, at least judged by the traffic on its mailing list. The Coccinelle developers continue to improve it and are responsive the questions. Don’t be put off by the low version number (currently 0.2), it is much better than most tools with larger version numbers.
Using Coccinelle to match if sequences
I have been using Coccinelle to obtain measurements of various properties of C if and switch statements. It is rare to find a tool that does exactly what is desired, but it is often possible to combine various tools to achieve the desired result.
I am interested in measuring sequences of if-else-if statements and one of the things I wanted to know was how many sequences of a given length occurred. Writing a pattern for each possible sequence was the obvious solution, but what is the longest sequence I should search for? A better solution is to use a pattern that matches short sequences and writes out the position (line/column number) where they occur in the code, as in the following Coccinelle pattern:
@ if_else_if_else @ expression E_1, E_2; statement S_1, S_2, S_3; position p_1, p_2; @@ if@p_1 (E_1) S_1 else if@p_2 (E_2) S_2 else S_3 @ script:python @ expr_1 << if_else_if_else.E_1; expr_2 << if_else_if_else.E_2; loc_1 << if_else_if_else.p_1; loc_2 << if_else_if_else.p_2; @@ print "--- ifelseifelse" print loc_1[0].line, " ", loc_1[0].column, " ", expr_1 print loc_2[0].line, " ", loc_2[0].column, " ", expr_2 |
noting that in a sequence of source such as:
if (x == 1) stmt_1; else if (x == 2) stmt_2; else if (x == 3) stmt_3; |
the tokens if (x == 2) will be matched twice, the first setting the position metavariable p_2 and then setting p_1. An awk script was written to read the Coccinelle output and merge together adjacent pairs of matches that were part of a longer if-else-if sequence.
The first pattern did not concern itself with the form of the controlling expression, it simply wrote it out. A second set of patterns was used to match those forms of controlling expression I was interested in, but first I had to convert the output into syntactically correct C so that it could be processed by Coccinelle. Again awk came to the rescue, converting the output:
--- ifelseifelse 186 2 op == FFEBLD_opSUBRREF 191 7 op == FFEBLD_opFUNCREF --- ifelseifelse 1094 3 anynum && commit 1111 8 ( c [ colon + 1 ] == '*' ) && commit |
into a separate function for each matched sequence:
void f_1(void) { // --- ifelseifelse /* 186 2 */ op == FFEBLD_opSUBRREF ; /* 191 7 */ op == FFEBLD_opFUNCREF ; } void f_2(void) { // --- ifelseifelse /* 1094 3 */ anynum && commit ; /* 1111 8 */ ( c [ colon + 1 ] == '*' ) && commit ; } |
The Coccinelle pattern:
@ if_eq_1 @ expression E_1; constant C_1, C_2; position p_1, p_2; @@ E_1 == C_1@p_1 ; E_1 == C_2@p_2 ; @ script:python @ expr_1<< if_eq_1.E_1; const_1 << if_eq_1.C_1; const_2 << if_eq_1.C_2; loc_1 << if_eq_1.p_1; loc_2 << if_eq_1.p_2; @@ print loc_1[0].line, " ", loc_1[0].column, " 3 ", expr_1, " == ", const_1 print loc_2[0].line, " ", loc_2[0].column, " 2 ", expr_1, " == ", const_2 |
matches a sequence of two statements which consist of an expression being compared for equality against a constant, with the expression being identical in both statements. Again positions were written out for post-processing, i.e., joining together matched sequences.
I was interested in any sequence of if-else-if that could be converted to an equivalent switch-statement. Equality tests against a constant is just one form of controlling expression that meets this requirement, another is the between operation. Separate patterns could be written and run over the generated C source containing the extracted controlling expressions.
Breaking down the measuring process into smaller steps reduced the amount of time needed to get a final result (with Coccinelle 0.1.19 the first pattern takes round 70 minutes, thanks to Julia Lawall‘s work to speed things up, an overhead that only has to occur once) and allows the same controlling expression patterns to be run against the output of both the if-else-if and if-if patterns.
At the end of this process I ended up with a list information (line numbers in source code and form of controlling expression) on if-statement sequences that could be rewritten as a switch-statement.
Semantic pattern matching (Coccinelle)
I have just discovered Coccinelle a tool that claims to fill a remarkable narrow niche (providing semantic patch functionality; I have no idea how the name is pronounced) but appears to have a lot of other uses. The functionality required of a semantic patch is the ability to write source code patterns and a set of transformation rules that convert the input source into the desired output. What is so interesting about Coccinelle is its pattern matching ability and the ability to output what appears to be unpreprocessed source (it has to be told the usual compile time stuff about include directory paths and macros defined via the command line; it would be unfair of me to complain that it needs to build a symbol table).
Creating a pattern requires defining identifiers to have various properties (eg, an expression in the following example) followed by various snippets of code that specify the pattern to match (in the following <… …> represents a bracketed (in the C compound statement sense) don’t care sequence of code and the lines starting with +/- have the usual patch meaning (ie, add/delete line)). The tool builds an abstract syntax tree so urb is treated as a complete expression that needs to be mapped over to the added line).
@@ expression lock, flags; expression urb; @@ spin_lock_irqsave(lock, flags); <... - usb_submit_urb(urb) + usb_submit_urb(urb, GFP_ATOMIC) ...> spin_unlock_irqrestore(lock, flags); |
Coccinelle comes with a bunch of predefined equivalence relations (they are called isomophisms) so that constructs such as if (x), if (x != NULL) and if (NULL != x) are known to be equivalent, which reduces the combinatorial explosion that often occurs when writing patterns that can handle real-world code.
It is written in OCaml (I guess there had to be some fly in the ointment) and so presumably borrows a lot from CIL, perhaps in this case a version number of 0.1.3 is not as bad as it might sound.
My main interest is in counting occurrences of various kinds of patterns in source code. A short-term hack is to map the sought-for pattern to some unique character sequence and pipe the output through grep and wc. There does not seem to be any option to output a count of the matched patterns … yet 🙂
Recent Comments