Archive
Taking a new GLR parser generator for a spin
It’s been 10 years since I last wrote about parsing tools, and the C parser, pycparser, I took for a test drive is still actively maintained. This week I read a post on Gecko, a new parser generator. Its author, Vladimir Makarov, implemented his first parser generator in 1985.
Gecko generates GLR parsers (Generalized Left-to-Right). In 2009, I predicted that GLR parsing was the future. It might still be the future, but since I made that prediction handwritten parsers, using some form of recursive descent, are what the major compilers (e.g., gcc and llvm) have been updated to use. Bison, the almost invisible market leader for parser generation, has supported GLR parsers for almost 20 years. The other ‘generalized’ technique, Earley parsing, produces parsers that are much slower and are memory hogs.
GLR parsers support Type-1 languages in the Chomsky hierarchy. The LR parsers supported by yacc compatible tools (e.g., the Bison default mode), and LL by ANTLR, can handle Type-2 languages, and regular expressions are Type-3 languages.
Programming language grammars are often context-sensitive (ambiguous is the common developer terminology), i.e., there is more than one way of parsing a sequence of input tokens. The classic example is the C statement: T *p;, which could be a declaration of p, or a redundant multiplication. This ambiguity can be resolved by maintaining a list of identifiers currently defined as typedefs, and have the lexer/parser lookup the status of identifiers in the contexts where a typedef could occur. This is not a big deal for compilers, which have to build a symbol table anyway. However, it’s very inconvenient when only syntax analysis is needed, i.e., no semantic analysis of the source.
An alternative approach is to parse all possibilities, and hope that eventually only one parse is syntactically possible. The following example could work, because there is a subsequent use of T in a non-typedef context (I’m not aware of any tools that do this):
T *p; // Is this a declaration of p as a pointer to T? T++; // No! It's a multiplication of T by p |
Another approach is to choose the most likely parse. Redundant multiplications are rare, and a declaration is the most likely usage. The token sequence f(x); is most likely to be a function call with one argument, rather than redundant parenthesis around a declaration of x to have type f.
Taking Gecko for a test drive requires a lexer and a grammar. Fortunately, one of the Gecko test cases includes a C lexer/grammar, and I adapted this to try out some C syntax test cases (code). My comparison point for these tests my memory of testing out Bison with GLR enabled.
Developers make coding mistakes, and I made mistakes when adapting the existing Gecko C grammar. Perhaps because I’m new to it, but Gecko’s minimalist error reporting was not helpful. Lots of debug information is available, but this is oriented towards somebody developing the innards of a parser generator. Hopefully, now Gecko is up and working, the focus will shift to improving developer diagnostics.
When Bison fails to merge multiple parses into a single parse, it failed. Gecko appears not to fail (it’s difficult to tell), it returns a parse tree.
Coding mistakes are sometime syntax errors, and without some form of error recovery, syntax errors often cascade to produce lots of spurious errors. Recovering from syntax errors is hard, but skipping to the next semicolon works remarkably well as a catch-all.
In Bison, syntax error recovery has to be hand-coded into the grammar and parser. Gecko supports an automatic syntax error recovery process. Based on a small sample, this automatic process failed to handle the common syntax errors (e.g., missing identifier or missing operator in an expression) I tried it on (code). It did handle the example in the documentation. Perhaps this is a work in progress.
The Gecko source built and passed all of its own tests. My tests are intended to check for handling of ambiguous constructs and error handling. As such, they are not pass/fail.
The main functional difference between Gecko and Bison is that Gecko is compiled into the program and can then be used to read and process a grammar at program runtime. Bison processes the grammar to produce tables that are included as part of the build process of a program.
This difference enables Gecko to handle grammars that are created or updated at application runtime. This approach also simplifies the process of handling multiple grammars.
While on the subject of parser generators, I have been following the progress of Marpa, but not tried it yet. The author has some interesting things to say about parsing.
Analysis of some C/C++ source file characteristics
Source code is contained in files within a file-system. However, source files as an entity are very rarely studied. The largest structural source code entities commonly studied are functions/methods/classes, which are stored within files.
To some extent this lack of research is understandable. In object-oriented languages one class per file appears to be a natural fit, at least for C++ and Java (I have not looked at other OO languages). In non-OO languages the clustering of functions/procedures/subroutines within a file appears to be one of developer convenience, or happenstance. Functions that are created/worked on together are in the same file because, I assume, this is the path of least resistance. At some future time functions may be moved to another file, or files split into smaller files.
What patterns are there in the way that files are organised within directories and subdirectories? Some developers keep everything within a single directory, while others cluster files by perceived functionality into various subdirectories. Program size is a factor here. Lots of subdirectories appears somewhat bureaucratic for small projects, and no subdirectories would be chaotic for large projects.
In general, there was little understanding of how files were typically organised, by users, within file-systems until around late 2000. Benchmarking of file-system performance was based on copies of the files/directories of a few shared file-systems. A 2009 paper uncovered the common usage patterns needed for generating realistic file-systems for benchmarking.
The following analysis investigates patterns in the source files and their contained functions in C/C++ programs. The information was extracted from 426 GitHub projects using CodeQL.
The 426 repos contained 116,169 C/C++ source files, which contained 29,721,070 function definitions. Which files contained C source and which C++? File name suffix provides a close approximation. The table below lists the top-10 suffixes:
Suffix Occurrences Percent
.c 53,931 46.4
.cpp 49,621 42.7
.cc 7,699 6.6
.cxx 2,616 2.3
.I 965 0.8
.inl 403 0.3
.ipp 400 0.3
.inc 159 0.1
.c++ 136 0.1
.ic 128 0.1 |
CodeQL analysis can provide linkage information, i.e., whether a function is defined with C linkage. I used this information to distinguish C from C++ source because it is simpler than deciding which suffix is most likely to correspond to which language. It produced 56,002 files classified as containing C source.
The full path to around 9% of files includes a subdirectory whose name is test/, tests/, or testcases/. Based on the (perhaps incorrect) belief that the characteristics of test files are different from source files, files contained under such directories were labelled test files. The plot below shows the number of files containing a given number of function definitions, with fitted power laws over two ranges (code and data):
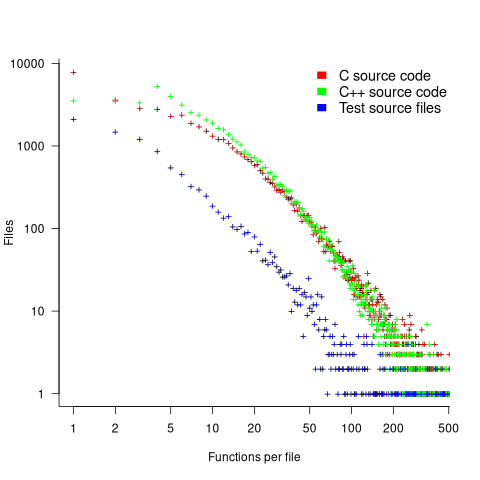
The shape of the file/function distribution is very surprising. I had not expected the majority of C files to contain a single function. For C++ there are two regions, with roughly the same number of files containing 1, 2, or 3 functions, and a smooth decline for files containing four or more methods (presumably most of these are contained in a class).
For C, C++ and test files, a power law could be fitted over a range of functions-per-file, e.g., between 6 and 2 for C, or between 4 and 2 for C++, or between 20 and 100 for C/C++, or 3 and more for test files. However, I have a suspicion that there is a currently unknown (to me) factor that needs to be adjusted for. Alternatively, I will get over my surprise at the shape of this distribution (files in general have a lognormal size, in bytes, distribution).
For C, C++ and test files, a power law is fitted over a range of functions-per-file, e.g., between 6 and 21 (exponent -1.1), and 22 and 100 (exponent -2) for C, between 4 and 21 (exponent -1.2), and 22 and 100 (exponent -2.2) for C++, between 4 and 50 (exponent -1.7), for test files. Files in general have a lognormal size, in bytes, distribution.
Perhaps a file contains only a few functions when these functions are very long. The plot below shows lines of code contained in files containing a given number of function, with fitted loess regression line in red (code and data):
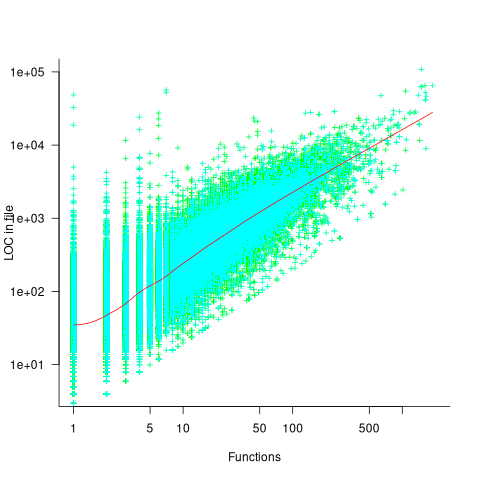
A fitted regression model has the form  . The number of LOC per function in a file does slowly decrease as the number of functions increases, but the impact is not that large.
. The number of LOC per function in a file does slowly decrease as the number of functions increases, but the impact is not that large.
How are source files distributed across subdirectories? The plot below shows number of C/C++ files appearing within a subdirectory of a given depth, with fitted Poisson distribution (code and data):
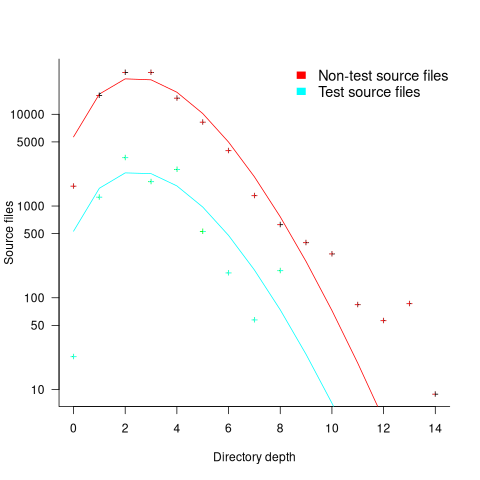
Studies of general file-systems found that number of files at a given subdirectory depth has a Poisson distribution with mean around 6.5. The mean depth for these C/C++ source files is 2.9.
Is this pattern of source file use specific to C/C++, or does it also occur in Java and Python? A question for another post.
Occurrence of binary operator overloading in C++
Operator overloading, like many programming language constructs, was first supported in the 1960s (Algol 68 also provided a means to specify a precedence for the operator). C++ is perhaps the most widely used language supporting operator overloading; but not redefining their precedence.
I have always thought that operator overloading was more talked about than actually used (despite its long history, I have not been able to find any published usage information). A previous post noted that the CodeQL databases hosted by GitHub provides the data needed to measure usage, and having wrestled with the documentation (ql scripts used), C++ operator overload usage data is available.
The table below shows the total uses of overloaded and ‘usual’ binary operators in the source code (excluding headers) of 77 C++ repositories on GitHub (the 100 repositories C/C+ MRVA). The table is ordered by total occurrences of overloads, with the Percentage column showing the percentage use of overloaded operators against the total for the respective operator (i.e.,  ; code and data):
; code and data):
Binary Overload Usual Total Percentage << 103,855 20,463 124,318 83.5 == 21,845 118,037 139,882 15.6 != 14,749 69,273 84,022 17.6 * 12,849 57,906 70,755 18.2 + 10,928 103,072 114,000 9.6 && 8,183 64,148 72,331 11.3 - 5,064 77,775 82,839 6.1 <= 3,960 18,344 22,304 17.8 & 3,320 27,388 30,708 10.8 < 1,351 93,393 94,744 1.4 >> 1,082 11,038 12,120 8.9 / 1,062 29,023 30,085 3.5 > 537 44,556 45,093 1.2 >= 473 27,738 28,211 1.7 | 293 13,959 14,252 2.0 ^ 71 1,248 1,319 5.4 <=> 13 12 25 52.0 % 11 9,338 9,349 0.1 || 9 53,829 53,838 0.017 |
Use of the overloaded << operator is driven by standard library I/O, rather than left shifting.
There are seven operators where 10-20% of the usage is overloaded, which is a lot higher than I was expecting (not that I am a C++ expert).
How much does overloaded binary operator usage vary across projects? In the plot below, each vertical colored violin plot shows the distribution of overload usage for one operator across all 77 projects (the central black lines denote the range of the central 50% of the points; code and data):

While there is some variation between these 77 projects, in most cases a non-trivial percentage of an operator's usage is overloaded.
Finding links between gcc source code and the C Standard
How close is the agreement between the behavior of a compiler and its corresponding language specification?
In the previous century, some Standards’ bodies offered a compiler validation service. However, even when the number of commercial compilers numbered in the hundreds, this service was not commercially viable. These days there are only a handful of industrial strength compilers.
The availability of huge quantities of Open source, for some languages, has created a new language specification. Being able to turn much of this source into executable programs has become an effective measure of compiler correctness.
Those working on C/C++ compilers (Open source or otherwise), often claim that they implement the requirements contained in the corresponding ISO Standard. Some are active in the ISO Standards’ process, and I believe that they do strive to implement the requirements contained in the language standard.
How confident can we be that all the requirements contained in a language standard are correctly implemented by a compiler?
There is a cottage industry of testing compiler runtime behavior, often using fuzzers, and sometimes a compiler is one of the programs chosen to test new fuzzing techniques. This research checks optimization and code generation.
This runtime testing is all well and good, but a large percentage of the text in a language specification contains requirements on the syntax and semantics. The quality of syntax/semantic testing depends on how well the people writing the tests understand the language semantics. It takes a year or two of detailed study to achieve an effective compiler-level of understanding of these ‘front-end’ requirements.
The approach taken by the Model Implementation C Checker to show syntax/semantic correctness was to cross-referenced every if-statement in the front-end to one or more lines in the C90 Standard (the 1990 edition of the ISO C Standard), or an internal house-keeping reference (the source contained 3K references to 1.3K requirements in the C Standard). This compiler/checker was formally validated by BSI. As far as I know, this is the only compiler source cross-referenced at the level of individual lines/if-statements; there are compilers whose source contains cross-references to the sections of a language specification.
The main benefit of this cross-referencing process is insuring that every requirement in the C Standard is addressed by the compiler (correctly or otherwise). Other benefits include providing packets of wording for targeted tests and the ability to generate a runtime trace of all language features involved in compiling a given translation unit.
Replicating this cross-referencing for the gcc or llvm C compiler front-ends would be a huge amount of work for somebody who already has a detailed knowledge of the C Standard, along with some knowledge of compilers. The number of pages in the Standard relating to the C language has grown from 101 pages in C90 to 190 pages in C23. At an average of 14 cross-referenceable lines per page, the expected number of cross-references is now likely to be around 2,700.
LLMs are great at extracting information from text, can generate impressive quality C conformance tests, and are much, much cheaper than C language experts. How good are LLMs at working out which section(s)/paragraph(s) in the C Standard are implemented by the source code of a function contained in, say, gcc?
The LLM prompt I used to test out the idea was:
List the section and paragraph number of the latest ISO C standard containing the requirements implemented in the following source code from a C compiler |
Links to all responses from: ChatGPT5 Thinking, Grok3 Fast and Gok3 Expert.
It is very likely that text from the various versions of the C Standard were in the training data of the larger LLMs, so I did not include this material in the prompt. ChatGPT5 Thinking listed the 2024 draft N3220 as its source document.
The source code was copied from the C front-end code of gcc (i.e., the directory: gcc-15.1.0/gcc/c), which contains 67KLOC, with 6.8K if-statements.
Starting small, the following code looked like an easy test (I removed the comment containing text from the C Standard and obscured the big clue in the original function name: null_pointer_constant_p):
bool check_is_n_ptr (const_tree expr) { /* This should really operate on c_expr structures, but they aren't yet available everywhere required. */ tree type = TREE_TYPE (expr); if (expr == nullptr_node) return true; return (TREE_CODE (expr) == INTEGER_CST && !TREE_OVERFLOW (expr) && integer_zerop (expr) && (INTEGRAL_TYPE_P (type) || (TREE_CODE (type) == POINTER_TYPE && VOID_TYPE_P (TREE_TYPE (type)) && TYPE_QUALS (TREE_TYPE (type)) == TYPE_UNQUALIFIED))); } |
Wow, ChatGPT5 Thinking’s response even included a note on why the code checks for an unqualified type:
Here are the exact C23 (ISO/IEC 9899:2024) clauses that your function is implementing:
6.3.2.3 Pointers, ¶3 — Definition of a null pointer constant: “An integer constant expression
with the value 0, such an expression cast to type void *, or the predefined constant nullptr
is called a null pointer constant.”
6.6 Constant expressions, ¶8 — What qualifies as an integer constant expression
(your INTEGER_CST / INTEGRAL_TYPE_P checks).
6.6 Constant expressions, ¶4 — Range requirement for constant expressions
(motivates the !TREE_OVERFLOW (expr) check).
6.4.4.6 Predefined constants, ¶¶1–3 — nullptr is a predefined constant (token classification;
ties to your expr == nullptr_node fast-path).
6.3.2.4 nullptr_t, ¶¶1–2 — Conversions of nullptr_t (confirms nullptr converts to any pointer
type yielding the null pointer value).
Notes
• The “cast to type void *” wording in 6.3.2.3 means unqualified void *,
which is why your code insists the pointed-to void is unqualified.
Grok3 Fast’s response was even more expansive (and almost instantaneous), listing examples of section/paragraphs containing uses of null pointers, and pointing out that the wording was unchanged until C23 (when the nullptr keyword was introduced, along with its type nullptr_t). It also pointed out gcc specific features of the implementation (the prompt did not identify the compiler).
That’s enough of the easy questions. The following code (comments removed, function name unchanged) is essentially asking a question: What is the promoted type of the argument?
tree c_type_promotes_to (tree type) { tree ret = NULL_TREE; if (TYPE_MAIN_VARIANT (type) == float_type_node) ret = double_type_node; else if (c_promoting_integer_type_p (type)) { if (TYPE_UNSIGNED (type) && (TYPE_PRECISION (type) == TYPE_PRECISION (integer_type_node))) ret = unsigned_type_node; else ret = integer_type_node; } if (ret != NULL_TREE) return (TYPE_ATOMIC (type) ? c_build_qualified_type (ret, TYPE_QUAL_ATOMIC) : ret); return type; } |
ChatGPT5 listed six references. Three were good, and the other three were closely related, but I would not have cited them. The seven Grok3 references came from several documents using slightly different section numbers. Updating the prompt to explicitly name N3220 as the document to use did not change Grok3’s cited references (for this question).
All the code in the previous questions was there because of text in the C Standard. How do ChatGPT5/Grok3 handle the presence of code that does not have standard associated text?
The following function contains code to handle named address spaces (defined in a 2005 Technical Report: TR 18037 Extensions to support embedded processors).
static tree qualify_type (tree type, tree like) { addr_space_t as_type = TYPE_ADDR_SPACE (type); addr_space_t as_like = TYPE_ADDR_SPACE (like); addr_space_t as_common; /* If the two named address spaces are different, determine the common superset address space. If there isn't one, raise an error. */ if (!addr_space_superset (as_type, as_like, &as_common)) { as_common = as_type; error ("%qT and %qT are in disjoint named address spaces", type, like); } return c_build_qualified_type (type, TYPE_QUALS_NO_ADDR_SPACE (type) | TYPE_QUALS_NO_ADDR_SPACE_NO_ATOMIC (like) | ENCODE_QUAL_ADDR_SPACE (as_common)); } |
ChatGPT5 listed six good references and pointed out the association between the named address space code and TR 18037. Grok3 Fast hallucinated extensive quoted text/references from TR 18037 related to named address spaces. Grok3 Expert pointed out that the Standard does not contain any requirements related to named address spaces and listed two reasonable references.
Finding appropriate cross-references is the time-consuming first step. Next, I want the LLM to add them as comments next to the corresponding code.
I picked a 312 line function, and updated the prompt to add comments to the attached file:
Find the section and paragraph numbers in the ISO C standard, specified in document N3220, containing the requirements implemented in the source code contained in the attached file, and add these section and paragraph numbers at the corresponding places in the code as comment |
ChatGPT5 Thinking thought for 5 min 46 secs (output), and Grok3 Expert thought for 3 mins 4 secs (output).
Both ChatGPT5 and Grok3 modified the existing code, either by joining adjacent lines, changing variable names, or deleting lines. ChatGPT made far fewer changes, while the Grok3 output was 65 lines shorter than the original (including the added comments).
Both LLMs added comments to blocks of if-statements (my fault for not explicitly specifying that every if should be cross-referenced), with ChatGPT5 adding the most cross-references.
One way to stop the LLMs making unasked for changes to the source is to have them focus on the added comments, i.e., ask for a diff that can be fed into patch. The updated prompt is:
Find the section and paragraph numbers in the ISO C standard, specified in document N3220, containing the requirements implemented by each if statement in the source code contained in the attached file. Create a diff file that patch can use to add these section and paragraph numbers as comments at the corresponding lines in the original code |
ChatGPT5 Thinking thought for around 4 min (it reported inconsistent values (output), and Grok3 Expert thought for 5 min 1 sec (output).
The ChatGPT5 patch contained many more cross-references than its earlier output, with comments on more if-statements. The Grok3 patch was a third the size of the ChatGPT5 patch.
How well did the LLMs perform?
ChatGPT5 did very well, and its patch output would be a good starting point for a detailed human expert edit. Perhaps an improved prompt, or some form of fine-tuning would useful improve performance.
Grok3 Fast does not appear to be usable, but Grok3 Expert could be used as an independent check against ChatGPT5 output.
Working at the section/paragraph level it is not always possible to give the necessary detailed cross-reference because some paragraphs contain multiple requirements. It might be easier to split the C Standard text into smaller chunks, rather than trying to get LLMs to give line offsets within a paragraph.
Modeling the distribution of method sizes
The number of lines of code in a method/function follows the same pattern in the three languages for which I have measurements: C, Java, Pharo (derived from Smalltalk-80).
The number of methods containing a given number of lines is a power law, with an exponent of 2.8 for C, 2.7 for Java and 2.6 for Pharo.
This behavior does not appear to be consistent with a simplistic model of method growth, in lines of code, based on the following three kinds of steps over a 2-D lattice: moving right with probability  , moving up and to the right with probability
, moving up and to the right with probability  , and moving down and to the right with probability
, and moving down and to the right with probability  . The start of an
. The start of an if or for statement are examples of coding constructs that produce a step followed by a step at the end of the statement; steps are any non-compound statement. The image below shows the distinct paths for a method containing four statements:

For this model, if  the probability of returning to the origin after taking
the probability of returning to the origin after taking  is a complicated expression with an exponentially decaying tail, and the case
is a complicated expression with an exponentially decaying tail, and the case  is a well studied problem in 1-D random walks (the probability of returning to the origin after taking steps is
is a well studied problem in 1-D random walks (the probability of returning to the origin after taking steps is  approx n^{-1.5}") ).
).
Possible changes to this model to more closely align its behavior with source statement production include:
- include terms for the correlation between statements, e.g., assigning to a local variable implies a later statement that reads from that variable,
- include context terms in the up/down probabilities, e.g., nesting level.
Measuring statement correlation requires handling lots of special cases, while measurements of up/down steps is easily obtained.
How can / probabilities be written such that step length has a power law with an exponent greater than two?
ChatGPT 5 told me that the Langevin equation and Fokker–Planck equation could be used to derive probabilities that produced a power law exponent greater than two. I had no idea had they might be used, so I asked ChatGPT, Grok, Deepseek and Kimi to suggest possible equations for the / probabilities.
The physics model corresponding to this code related problem involves the trajectories of particles at the bottom of a well, with the steepness of the wall varying with height. This model is widely studied in physics, where it is known as a potential well.
Reaching a possible solution involved refining the questions I asked, following suggestions that turned out to be hallucinations, and trying to work out what a realistic solution might look like.
One ChatGPT suggestion that initially looked promising used a Metropolis–Hastings approach, and a logarithmic potential well. However, it eventually dawned on me that ^a") , where
, where  is nesting level, and
is nesting level, and  some constant, is unlikely to be realistic (I expect the probability of stepping up to decrease with nesting level).
some constant, is unlikely to be realistic (I expect the probability of stepping up to decrease with nesting level).
Kimi proposed a model based on what it called algebraic divergence:
=r/{z(y)},U(y)={u_0y^{1-2/{alpha}}}/{z(y)}, D(y)={d_0y^{1-2/{alpha}}}/{z(y)}")
where: ") normalises the probabilities to equal one,
normalises the probabilities to equal one, =r+u_0y^{1-2/alpha}+d_0y^{1-2/alpha}") ,
,  is the up probability at nesting 0,
is the up probability at nesting 0,  is the down probability at nesting 0, and
is the down probability at nesting 0, and  is the desired power law exponent (e.g., 2.8).
is the desired power law exponent (e.g., 2.8).
For C,  , giving
, giving =r/{z(y)},U(y)={u_0y^{0.29}}/{z(y)}, D(y)={d_0y^{0.29}}/{z(y)}")
The average length of a method, in LOC, is given by:
![E[LOC]={alpha r}/{2(d_0-u_0)}+O(e^{lambda}-1)](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_969.5_ffcacf0bb8190096d4d17fb475c0a290.png "E[LOC]={alpha r}/{2(d_0-u_0)}+O(e^{lambda}-1)") , where:
, where: }/{d_0+u_0}")
For C, the mean function length is 26.4 lines, and the values of  , , and need to be chosen subject to the constraint
, , and need to be chosen subject to the constraint  .
.
Combining the normalization factor with the requirement  , shows that as increases,
, shows that as increases, ") slowly decreases and
slowly decreases and ") slowly increases.
slowly increases.
One way to judge how closely a model matches reality is to use it to make predictions about behavior patterns that were not used to create the model. The behavior patterns used to build this model were: function/method length is a power law with exponent greater than 2. The mean length, ![E[LOC]](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_981.5_0ac27fa76bd7c6e393f3497c9f30db7e.png "E[LOC]") , is a tuneable parameter.
, is a tuneable parameter.
Ideally a model works across many languages, but to start, given the ease of measuring C source (using Coccinelle), this one language will be the focus.
I need to think of measurable source code patterns that are not an immediate consequence of the power law pattern used to create the model. Suggestions welcome.
It’s possible that the impact of factors not included in this model (e.g., statement correlation) is large enough to hide any nesting related patterns that are there. While different kinds of compound statements (e.g., if vs. for) may have different step probabilities, in C, and I suspect other languages, if-statement use dominates (Table 1713.1: if 16%, for 4.6% while 2.1%, non-compound statements 66%).
Distribution of integer literals in text/speech and source code
Numeric values are an integral to communication between people. What is the distribution of integer values in text/speech, and does the use of integer literals in source code have a similar distribution?
- The paper Numbers in Context: Cardinals, Ordinals, and Nominals in American English by Greg Woodin, and Bodo Winter studied the 9+ million numbers contained in the Corpus of Contemporary American English (7,744,038 integer values). The plot below shows the number of occurrences of the smaller integer values, and a fitted regression line for values in the range 1..50 (code+data):

The frequency of integer values in this corpus is proportional to:
 .
. - The paper Frequency of occurrence of numbers in the World Wide Web by Dorogovtsev, Mendes, and Gama Oliveira found that the number of web pages containing a given integer value declines as the value increases, with the decline for non-round numbers being roughly proportional to
 (round numbers are much more frequent than adjacent values and bias fitted models), and including all values gives
(round numbers are much more frequent than adjacent values and bias fitted models), and including all values gives  (for values up to
(for values up to  ).
).
Programs are an implementation of a sliver of the world in which people live, and it is to be expected that the frequency of numeric literal values in source code is highly correlated with real world frequency. Numeric values also appear in the algorithms and mathematical expressions used to create implementations. I am not aware of any studies looking at the frequency of use of numeric constants in algorithms and mathematics. As an aside, the frequency of occurrence of mathematical expressions containing a given number of operators is similar to that in C source
What are the usage characteristics of integer literals in source code (floating-point literal use is very rare outside of particular application domains)?
The plot below shows occurrences of decimal (green) and hexadecimal (blue) literals in C source (data from fig 825.1 from my C book) with a regression line fitted to values 1..50 of the decimal data (code+data):

The frequency of decimal literal values in C source is proportional to: . Adding the hexadecimal values to the model has little effect.
The paper What do developers consider magic literals? A smalltalk perspective by Anquetil, Delplanque, Ducasse, Zaitsev, Fuhrman, and Guéhéneuc studied the use of literals in Smalltalk. The plot below shows the number of occurrences of all kinds of integer literals and a fitted regression line (code+data):

The frequency of integer literal values in Smalltalk source is proportional to:  .
.
The distribution of integer literals in both human communication and source code is well-fitted by a power law. Smalltalk appears to be the outlier, with an exponent of 1.7 vs 1.3-1.4. Perhaps it’s a sample size issue; 14,054 integer literals for Smalltalk and a million+ for the other datasets.
I had expected source code to contain a lot more zeroes/ones, relative to other values, than human communication. Zero/one are such common values that there are implicit short-cuts that people can use to express them; removing the effort/cost needed to explicitly specify them. Some programming languages specify default 0/1 values for common idioms, but C-like languages generally require explicit specification of values.
The Whitehouse report on adopting memory safety
Last month’s Whitehouse report: BACK TO THE BUILDING BLOCKS: A Path Towards Secure and Measurable Software “… outlines two fundamental shifts: the need to both rebalance the responsibility to defend cyberspace and realign incentives to favor long-term cybersecurity investments.”
From the abstract: “First, in order to reduce memory safety vulnerabilities at scale, … This report focuses on the programming language as a primary building block, …” Wow, I never expected to see the term ‘memory safety’ in a report from the Whitehouse (not that I recall ever reading a Whitehouse report). And, is this the first Whitehouse report to talk about programming languages?
tl;dr They mistakenly to focus on the tools (i.e., programming languages), the focus needs to be on how the tools are used, e.g., require switching on C compiler’s memory safety checks which currently default to off.
The report’s intent is to get the community to progress from defence (e.g., virus scanning) to offence (e.g., removing the vulnerabilities at source). The three-pronged attack focuses on programming languages, hardware (e.g., CHERI), and formal methods. The report is a rallying call to the troops, who are, I assume, senior executives with no little or no knowledge of writing software.
How did memory safety and programming languages enter the political limelight? What caused the Whitehouse claim that “…, one of the most impactful actions software and hardware manufacturers can take is adopting memory safe programming languages.”?
The cited reference is a report published two months earlier: The Case for Memory Safe Roadmaps: Why Both C-Suite Executives and Technical Experts Need to Take Memory Safe Coding Seriously, published by an alphabet soup of national security agencies.
This report starts by stating the obvious (at least to developers): “Memory safety vulnerabilities are the most prevalent type of disclosed software vulnerability.” (one Microsoft reports says 70%). It then goes on to make the optimistic claim that: “Memory safe programming languages (MSLs) can eliminate memory safety vulnerabilities.”
This concept of a ‘memory safe programming language’ leads the authors to fall into the trap of believing that tools are the problem, rather than how the tools are used.
C and C++ are memory safe programming languages when the appropriate compiler options are switched on, e.g., gcc’s sanitize flags. Rust and Ada are not memory safe programming languages when the appropriate compiler options are switched on/off, or object/function definitions include the unsafe keyword.
People argue over the definition of memory safety. At the implementation level, it includes checks that storage is not accessed outside of its defined bounds, e.g., arrays are not indexed outside the specified lower/upper bound.
I’m a great fan of array/pointer bounds checking and since the 1980s have been using bounds checking tools to check my C programs. I found bounds checking is a very cost-effective way of detecting coding mistakes.
Culture drives the (non)use of bounds checking. Pascal, Ada and now Rust have a culture of bounds checking during development, amongst other checks. C, C++, and other languages have a culture of not having switching on bounds checking.
Shipping programs with/without bounds checking enabled is a contentious issue. The three main factors are:
- Runtime performance overhead of doing the checks (which can vary from almost nothing to a factor of 5+, depending on the frequency of bounds checked accesses {checks don’t need to be made when the compiler can figure out that a particular access is always within bounds}). I would expect the performance overhead to be about the same for C/Rust compilers using the same compiler technology (as the Open source compilers do). A recent study found C (no checking) to be 1.77 times faster, on average, than Rust (with checking),
- Runtime memory overhead. Adding code to check memory accesses increases the size of programs. This can be an issue for embedded systems, where memory is not as plentiful as desktop systems (recent survey of Rust on embedded systems),
- Studies (here and here) have found that programs can be remarkably robust in the presence of errors. Developers’ everyday experience is that programs containing many coding mistakes regularly behave as expected most of the time.
If bounds checking is enabled on shipped applications, what should happen when a bounds violation is detected?
Many bounds violations are likely to be benign, and a few not so. Should users have the option of continuing program execution after a violation is flagged (assuming they have been trained to understand the program message they are seeing and are aware of the response options)?
Java programs ship with bounds checking enabled, but I have not seen any studies of user response to runtime errors.
The reason that C/C++ is the language used to write so many of the programs listed in vulnerability databases is that these languages are popular and widely used. The Rust security advisory database contains few entries because few widely used programs are written in Rust. It’s possible to write unsafe code in Rust, just like C/C++, and studies find that developers regularly write such code and security risks exist within the Rust ecosystem, just like C/C++.
There have been various attempts to implement bounds checking in x86
processors. Intel added the MPX instruction, but there were problems with the specification, and support was discontinued in 2019.
The CHERI hardware discussed in the Whitehouse report is not yet commercially available, but organizations are working towards commercial products.
A comparison of C++ and Rust compiler performance
Large code bases take a long time to compile and build. How much impact does the choice of programming language have on compiler/build times?
The small number of industrial strength compilers available for the widely used languages makes the discussion as much about distinct implementations as distinct languages. And then there is the issue of different versions of the same compiler having different performance characteristics; for instance, the performance of Microsoft’s C++ Visual Studio compiler depends on the release of the compiler and the version of the standard specified.
Implementation details can have a significant impact on compile time. Compile time may be dominated by lexical analysis, while support for lots of fancy optimization shifts the time costs to code generation, and poorly chosen algorithms can result in symbol table lookup being a time sink (especially for large programs). For short programs, compile time may be dominated by start-up costs. These days, developers rarely have to worry about small memory size causing occurring when compiling a large source file.
A recent blog post compared the compile/build time performance of Rust and C++ on Linux and Apple’s OS X, and strager kindly made the data available.
The most obvious problem with attempting to compare the performance of compilers for different languages is that the amount of code contained in programs implementing the same functionality will differ (this is also true when the programs are written in the same language).
strager’s solution was to take a C++ program containing 9.3k LOC, plus 7.3K LOC of tests, and convert everything to Rust (9.5K LOC, plus 7.6K LOC of tests). In total, the benchmark consisted of compiling/building three C++ source files and three equivalent Rust source files.
The performance impact of number of lines of source code was measured by taking the largest file and copy-pasting it 8, 16, and 32 times, to create three every larger versions.
The OS X benchmarks did not include multiple file sizes, and are not included in the following analysis.
A variety of toolchain options were included in different runs, and for Rust various command line options; most distinct benchmarks were run 10 times each. On Linux, there were a total of 360 C++ runs, and for Rust 1,066 runs (code+data).
The model  , where
, where  is a fitted regression constant, and
is a fitted regression constant, and  is the fitted regression coefficient for the
is the fitted regression coefficient for the  ‘th benchmark, explains just over 50% of the variance. The language is implicit in the benchmark information.
‘th benchmark, explains just over 50% of the variance. The language is implicit in the benchmark information.
The model -0.84L}") , where
, where  is the number of copies,
is the number of copies,  is 0 for C++ and 1 for Rust, explains 92% of the variance, i.e., it is a very good fit.
is 0 for C++ and 1 for Rust, explains 92% of the variance, i.e., it is a very good fit.
The expression -0.84L}") is a language and source code size multiplication factor. The numeric values are:
is a language and source code size multiplication factor. The numeric values are:
1 8 16 32 C++ 1.03 1.25 1.57 2.45 Rust 0.98 1.52 2.52 6.90 |
showing that while Rust compilation is faster than C++, for ‘shorter’ files, it becomes much relatively slower as the quantity of source increases.
The size factor for Rust is growing quadratically, while it is much closer to linear for C++.
What are the threats to the validity of this benchmark comparison?
The most obvious is the small number of files benchmarked. I don’t have any ideas for creating a larger sample.
How representative is the benchmark of typical projects? An explicit goal in benchmark selection was to minimise external dependencies (to reduce the effort likely to be needed to translate to Rust). Typically, projects contain many dependencies, with compilers sometimes spending more time processing dependency information than compiling the actual top-level source, e.g., header files in C++.
A less obvious threat is the fact that the benchmarks for each language were run in contiguous time intervals, i.e., all Rust, then all C++, then all Rust (see plot below; code+data):

It is possible that one or more background processes were running while one set of language benchmarks was being run, which would skew the results. One solution is to intermix the runs for each language (switching off all background tasks is much harder).
I was surprised by how well the regression model fitted the data; the fit is rarely this good. Perhaps a larger set of benchmarks would increase the variance.
Widely used programming languages: past, present, and future
Programming languages are like pop groups in that they have followers, fans and supporters; new ones are constantly being created and some eventually become widely popular, while those that were once popular slowly fade away or mutate into something else.
Creating a language is a relatively popular activity. Science fiction and fantasy authors have been doing it since before computers existed, e.g., the Elf language Quenya devised by Tolkien, and in the computer age Star Trek’s Klingon. Some very good how-to books have been written on the subject.
As soon as computers became available, people started inventing programming languages.
What have been the major factors influencing the growth to widespread use of a new programming languages (I’m ignoring languages that become widespread within application niches)?
Cobol and Fortran became widely used because there was widespread implementation support for them across computer manufacturers, and they did not have to compete with any existing widely used languages. Various niches had one or more languages that were widely used in that niche, e.g., Algol 60 in academia.
To become widely used during the mainframe/minicomputer age, a new language first had to be ported to the major computers of the day, whose products sometimes supported multiple, incompatible operating systems. No new languages became widely used, in the sense of across computer vendors. Some new languages were widely used by developers, because they were available on IBM computers; for several decades a large percentage of developers used IBM computers. Based on job adverts, RPG was widely used, but PL/1 not so. The use of RPG declined with the decline of IBM.
The introduction of microcomputers (originally 8-bit, then 16, then 32, and finally 64-bit) opened up an opportunity for new languages to become widely used in that niche (which would eventually grow to be the primary computing platform of its day). This opportunity occurred because compiler vendors for the major languages of the day did not want to cannibalize their existing market (i.e., selling compilers for a lot more than the price of a microcomputer) by selling a much lower priced product on microcomputers.
BASIC became available on practically all microcomputers, or rather some dialect of BASIC that was incompatible with all the other dialects. The availability of BASIC on a vendor’s computer promoted sales of the hardware, and it was not worthwhile for the major vendors to create a version of BASIC that reduced portability costs; the profit was in games.
The dominance of the Microsoft/Intel partnership removed the high cost of porting to lots of platforms (by driving them out of business), but created a major new obstacle to the wide adoption of new languages: Developer choice. There had always been lots of new languages floating around, but people only got to see the subset that were available on the particular hardware they targeted. Once the cpu/OS (essentially) became a monoculture most new languages had to compete for developer attention in one ecosystem.
Pascal was in widespread use for a few years on micros (in the form of Turbo Pascal) and university computers (the source of Wirth’s ETH compiler was freely available for porting), but eventually C won developer mindshare and became the most widely used language. In the early 1990s C++ compiler sales took off, but many developers were writing C with a few C++ constructs scattered about the code (e.g., use of new, rather than malloc/free).
Next, the Internet took off, and opened up an opportunity for new languages to become dominant. This opportunity occurred because Internet related software was being made freely available, and established compiler vendors were not interested in making their products freely available.
There were people willing to invest in creating a good-enough implementation of the language they had invented, and giving it away for free. Luck, plus being in the right place at the right time resulted in PHP and Javascript becoming widely used. Network effects prevent any other language becoming widely used. Compatible dialects of PHP and Javascript may migrate widespread usage to quite different languages over time, e.g., Facebook’s Hack.
Java rode to popularity on the coat-tails of the Internet, and when it looked like security issues would reduce it to niche status, it became the vendor supported language for one of the major smart-phone OSs.
Next, smart-phones took off, but the availability of Open Source compilers closed the opportunity window for new languages to become dominant through lack of interest from existing compiler vendors. Smart-phone vendors wanted to quickly attract developers, which meant throwing their weight behind a language that many developers were already familiar with; Apple went with Objective-C (which evolved to Swift), Google with Java (which evolved to Kotlin, because of the Oracle lawsuit).
Where does Python fit in this grand scheme? I don’t yet have an answer, or is my world-view wrong to treat Python usage as being as widespread as C/C++/Java?
New programming languages continue to be implemented; I don’t see this ever stopping. Most don’t attract more users than their implementer, but a few become fashionable amongst the young, who are always looking to attach themselves to something new and shiny.
Will a new programming language ever again become widely used?
Like human languages, programming languages experience strong networking effects. Widely used languages continue to be widely used because many companies depend on code written in it, and many developers who can use it can obtain jobs; what company wants to risk using a new language only to find they cannot hire staff who know it, and there are not many people willing to invest in becoming fluent in a language with no immediate job prospects.
Today’s widely used programmings languages succeeded in a niche that eventually grew larger than all the other computing ecosystems. The Internet and smart-phones are used by everybody on the planet, there are no bigger ecosystems to provide new languages with a possible route to widespread use. To be widely used a language first has to become fashionable, but from now on, new programming languages that don’t evolve from (i.e., be compatible with) current widely used languages are very unlikely to migrate from fashionable to widely used.
It has always been possible for a proficient developer to dedicate a year+ of effort to create a new language implementation. Adding the polish need to make it production ready used to take much longer, but these days tool chains such as LLVM supply a lot of the heavy lifting. The problem for almost all language creators/implementers is community building; they are terrible at dealing with other developers.
It’s no surprise that nearly all the new languages that become fashionable originate with language creators who work for a company that happens to feel a need for a new language. Examples include:
- Go created by Google for internal use, and attracted an outside fan base. Company languages are not new, with IBM’s PL/1 being the poster child (or is there a more modern poster child). At the moment Go is a trendy language, and this feeds a supply of young developers willing to invest in learning it. Once the trendiness wears off, Google will start to have problems recruiting developers, the reason: Being labelled as a Go developer limits job prospects when few other companies use the language. Talk to a manager who has tried to recruit developers to work on applications written in Fortran, Pascal and other once-widely used languages (and even wannabe widely used languages, such as Ada),
- Rust a vanity project from Mozilla, which they have now
abandonedcast adrift. Did Rust become fashionable because it arrived at the right time to become the not-Google language? I await a PhD thesis on the topic of the rise and fall of Rust, - Microsoft’s C# ceased being trendy some years ago. These days I don’t have much contact with developers working in the Microsoft ecosystem, so I don’t know anything about the state of the C# job market.
Every now and again a language creator has the social skills needed to start an active community. Zig caught my attention when I read that its creator, Andrew Kelley, had quit his job to work full-time on Zig. Two and a-half years later Zig has its own track at FOSEM’21.
Will Zig become the next fashionable language, as Rust/Go popularity fades? I’m rooting for Zig because of its name, there are relatively few languages whose name starts with Z; the start of the alphabet is over-represented with language names. It would be foolish to root for a language because of a belief that it has magical properties (e.g., powerful, readable, maintainable), but the young are foolish.
Recent Comments