Archive
Why did organizations fund the creation of the first computers?
What were the events that drove organizations to fund the creation of the first computers?
I suspect that many readers do not appreciate how long scientific/engineering calculations took before electronic computers became available, or the huge number of clerical staff employed to process the paperwork associated with running any sizeable business.
If somebody wanted to know the logarithm of some value, or the sine/cosine of an angle, they looked up the answer in a table. Individuals owned small booklets of tables supplying some level of granularity and number of significant digits. My school boy booklet contains 60-pages of tables, all to five digits of output accuracy, with logarithm supporting four-digit input values and the sine/cosine/tangent tables having an input granularity of hundredth of a degree.
The values in these tables were calculated by human computers; with the following being among the most well known (for more details, see Calculation and Tabulation in the Nineteenth Century: Airy versus Babbage by Doron Swade, and The History of Mathematical Tables: from Sumer to Spreadsheets edited by Campbell-Kelly, Croarken, Flood, and Robson):
- In 1624 Henry Briggs published logarithms for the integer ranges 1-20,000 and 90,001-100,000 (to 14 decimal places), followed some years later by tables of sine and logarithm of sine; in 1628 Adriaan Vlacq publishing tables that filled in the missing values (to 10 decimal places). In 1783 Jurij Vega published a bug-fixed and extended version of Vlacq’s tables.
In 1827 Charles Babbage (that Babbage) published Table of Logarithms of the Natural Numbers from 1 to 10800. These tables were based on corrected versions of these tables, a rigorous nine-stage proofreading process was followed to prevent new mistakes creeping in.
Today, one person can publish A reconstruction of the tables of Briggs’ Arithmetica logarithmica (1624), with an appendix containing 300 pages of calculated values,
- between 1794 and 1799, Gaspard de Prony employed sixty to eighty computers to calculate the logarithms of the integers from 1 to 200,000 to fifteen significant digits (rounding issues sometimes required calculating 25 decimal digits; published in eighteen volumes). Around 400 man-years.
Logarithms and trigonometric functions are very widely used, creating incentives for investing in calculating and publishing tables. While it may be financially worthwhile investing in producing tables for some niche markets (e.g. Life tables for insurance companies), there is an unmet demand that will only be filled by a dramatic drop in the cost of computing simple expressions.
Babbage’s Difference engine was designed to evaluate polynomial expressions and print the results; perfect for publishing tables. While Babbage did not build a Difference engine, starting in 1837, engines based on Babbage’s design were built and sold commercially by the Swede Per Georg Scheutz.
Mechanical calculators improve accuracy and speed the process up. Vacuum tubes are invented in 1904 and become widely used to process analogue signals. World War II created an urgent demand for the results of a variety of time-consuming calculations, e.g., accurate ballistic tables, and valve computers were built. The plot below shows the cost per million operations for manual, mechanical and valve computers (code+data):
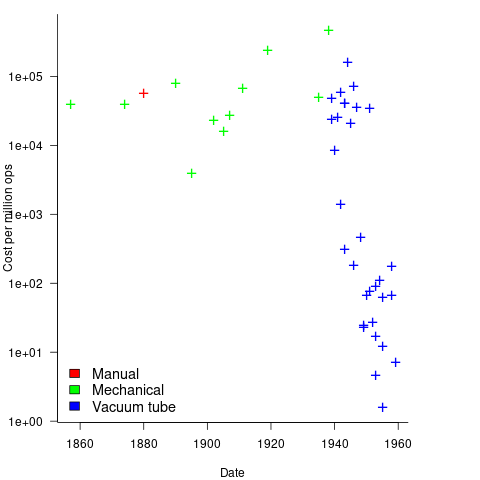
To many observers at the start of the 1950s, the market for electronic computers appeared to be organizations who needed to perform large amounts of scientific/engineering calculation.
Most businesses perform simple calculations on many unrelated values, e.g., banks have to credit/debit the appropriate account when money is deposited/withdrawn. There is no benefit in having a machine that can perform hundreds of calculations per second unless it can be fed data fast enough to keep it busy.
It so happened that, at the start of the 1950s, the US banking system was facing a crisis, the growth in the number of cheques being written meant that it would soon take longer than one day to process all the cheques that arrived in one day. In 1950 Bank of America managed 4.6 million checking accounts, and were opening 23,000 new account per month. Bank of America was then the largest bank in the world, and had a keen interest in continued growth. They funded the development of a bespoke computer system for processing cheques, the ERMA Banking system, which went live in 1959. The plot below shows the number of cheques processed per year by US banks (code+data):
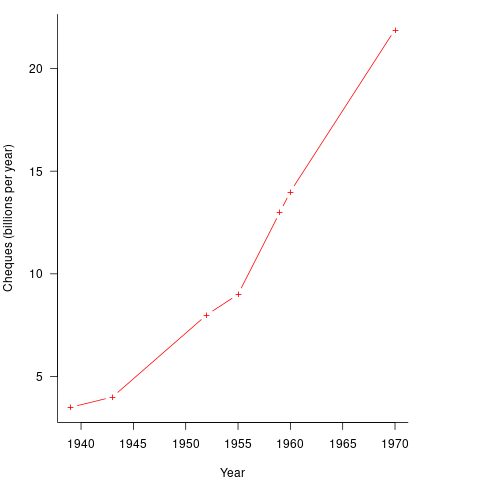
The ERMA system included electronic storage for holding account details, and data entry was speeded up by encoding account details on a magnetic strip included within every cheque.
Businesses are very interested in an integrated combination of input devices plus electronic storage plus compute. There are more commerce oriented businesses than scientific/engineering businesses, and commercial businesses usually have a lot more money to spend, i.e., the real money to be made by selling computers was the business data processing market.
The plot below shows the decreasing cost of hard disc storage (blue, right axis), along with the decreasing computing cost of valve based computers (red, left axis; code+data):
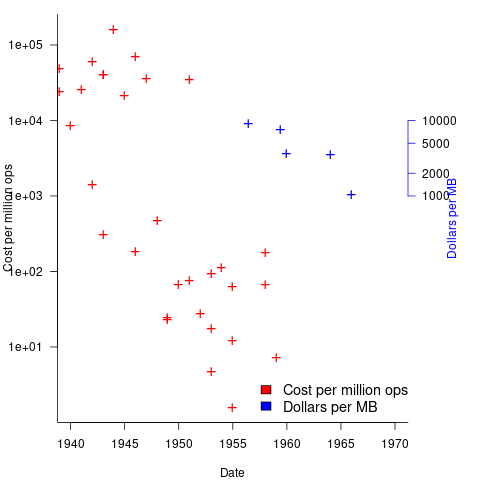
There was a larger business demand to be able to store information electronically, and the hard disc was invented by IBM, roughly 15 years after the first electronic computers.
The very different application demands of data processing and scientific/engineering are reflected in the features supported by the two languages designed in the 1950s, and widely used for the rest of the century: Cobol and Fortran.
Data processing involves simple operations on large quantities of data stored in a potentially huge number of different combinations (the myriad of mechanical point-of-sale terminals stored data in a myriad of different formats, which evolved over time, and the demand for backward compatibility created spaghetti data well before spaghetti code existed). Cobol has extensive functionality supporting the layout and format of input and output data, and simplistic coding constructs.
Scientific/engineering code involves complex calculations on some amount of input. Fortran has extensive functionality supporting program control flow, and relatively basic support for data input/output.
A third major application domain is real-time processing, such as SAGE. However, data on this domain is very hard to find, so it is not discussed.
Production of software may continue to be craft based
Andrew Carnegie made his fortune in the steel industry, and his autobiography is a fascinating insight into the scientific vs. craft/folklore approach to smelting iron ore. Carnegie measured the processes involved in smelting; he tracked the input and outputs involved in the smelting process, and applied the newly available scientific knowledge (e.g., chemistry) to minimize the resources needed to extract iron from ore. Other companies continued to treat Iron smelting as a suck-it-and-see activity, driven by personal opinion and the application of techniques that had worked in the past.
The technique of using what-worked-last-time can be a successful strategy when the variability of the inputs is low. In the case of smelting Iron there was a lot of variability in the Iron ore, Limestone and Coke fed into the furnaces. The smelting companies in Carnegie’s day ‘solved’ this input variability problem by restricting their purchase of raw materials to mines that delivered material that worked last time.
Hiring an experienced chemist (the only smelting company to do so), Carnegie found out that the quality of ore (i.e., percentage Iron content) in some mines with a high reputation was much lower than the ore quality of some mines with a low reputation; Carnegie was able to obtain a low price for high quality ore because other companies did not appreciate its characteristics (and shunned using it). Other companies were unable to extract Iron from high quality ore because they stuck to using a process that worked for lower quality ore (the amount of Limestone and Coke added to the smelting process has to be adjusted based on the Iron content of the ore, otherwise the process may deliver poor results, or even fail to produce Iron; see chapter 13).
When Carnegie’s application of scientific knowledge, and his competitors’ opinion driven production, is combined with being a good businessman, it’s no surprise that Carnegie made a fortune from his Iron smelting business.
What are the parallels between iron smelting in Carnegie’s day and the software industry?
An obvious parallel is the industry dominance of opinion driven processes. But then, the lack of any scientific basis for the processes involved in building software systems would seem to make drawing parallels a pointless exercise.
Let’s assume that there was a scientific basis for some of the major processes involved in software engineering. Would any of these science-based processes be adopted?
The reason for using science based knowledge and mechanization is to reduce costs, which may lead to increased profits or just staying in business (in a Red Queen’s race).
Agriculture is an example of a business where science and mechanization dominate, and building construction is a domain where this has not happened. Perhaps building construction will become more mechanized when unknown missing components become available (mechanization was available for agricultural processes in the 1700s, but they did not spread for a century or two, e.g., threshing machines).
It’s possible to find parallels between software engineering and the smelting process, agriculture, and building construction. In fact, it parallels can probably be found between software engineering and any other major business domain.
Drawing parallels between software engineering and other major business domains creates a sense of familiarity. In practice, software is unlike most existing business domains in that software products are one-off creations of an intangible good, which has (virtually) zero cost of reproduction, while the economics of creating tangible goods (e.g., by smelting, sowing and reaping, or building houses) is all about reducing the far from zero cost of reproduction.
Perhaps the main take-away from the history of the production of tangible goods is that the scientific method has not always supplanted the craft approach to production.
Complexity is a source of income in open source ecosystems
I am someone who regularly uses R, and my interest in programming languages means that on a semi-regular basis spend time reading blog posts about the language. Over the last year, or so, I had noticed several patterns of behavior, and after reading a recent blog post things started to make sense (the blog post gets a lot of things wrong, but more of that later).
What are the patterns that have caught my attention?
Some background: Hadley Wickham is the guy behind some very useful R packages. Hadley was an academic, and is now the chief scientist at RStudio, the company behind the R language specific IDE of the same name. As Hadley’s thinking about how to manipulate data has evolved, he has created new packages, and has been very prolific. The term Hadley-verse was coined to describe an approach to data manipulation and program structuring, based around use of packages written by the man.
For the last nine-months I have noticed that the term Tidyverse is being used more regularly to describe what had been the Hadley-verse. And???
Another thing that has become very noticeable, over the last six-months, is the extent to which a wide range of packages now have dependencies on packages in the HadleyTidyverse. And???
A recent post by Norman Matloff complains about the Tidyverse’s complexity (and about the consistency between its packages; which I had always thought was a good design principle), and how RStudio’s promotion of the Tidyverse could result in it becoming the dominant R world view. Matloff has an academic world view and misses what is going on.
RStudio, the company, need to sell their services (their IDE is clunky and will be wiped out if a top of the range product, such as Jetbrains, adds support for R). If R were simple to use, companies would have less need to hire external experts. A widely used complicated library of packages is a god-send for a company looking to sell R services.
I don’t think Hadley Wickam intentionally made things complicated, any more than the creators of the Microsoft server protocols added interdependencies to make life difficult for competitors.
A complex package ecosystem was probably not part of RStudio’s product vision, at least for many years. But sooner or later, RStudio management will have realised that simplicity and ease of use is not in their interest.
Once a collection of complicated packages exist, it is in RStudio’s interest to get as many other packages using them, as quickly as possible. Infect the host quickly, before anybody notices; all the while telling people how much the company is investing in the community that it cares about (making lots of money from).
Having this package ecosystem known as the Hadley-verse gives too much influence to one person, and makes it difficult to fire him later. Rebranding as the Tidyverse solves these problems.
Matloff accuses RStudio of monopoly behavior, I would have said they are fighting for survival (i.e., creating an environment capable of generating the kind of income a VC funded company is expected to make). Having worked in language environments where multiple, and incompatible, package ecosystems existed, I can see advantages in there being a monopoly. Matloff is also upset about a commercial company swooping in to steal their precious, a common academic complaint (academics swooping in to steal ideas from commercially developed software is, of course, perfectly respectable). Matloff also makes claims about teachability of programming that are not derived from any experimental evidence, but then everybody makes claims about programming languages without there being any experimental evidence.
RStudio management rode in on the data science wave, raising money from VCs. The wave is subsiding and they now need to appear to have a viable business (so they can be sold to a bigger fish), which means there has to be a visible market they can sell into. One way to sell in an open source environment is for things to be so complicated, that large companies will pay somebody to handle the complexity.
Business school research in software engineering is some of the best
There is a group of software engineering researchers that don’t feature as often as I would like in my evidence-based software engineering book; academics working in business schools.
Business school academics have written some of the best papers I have read on software engineering; the catch is that the data they use is confidential. For somebody writing a book that only discusses a topic if there is data publicly available, this is a problem.
These business school researchers show that it is possible for academics to obtain ‘interesting’ software engineering data from industry. My experience with talking to researchers in computing departments is that most are too involved in their own algorithmic bubble to want to talk to anybody else.
One big difference between the data analysis papers written by academics in computing departments and business schools, is statistical sophistication. Computing papers are still using stone-age pre-computer age techniques, the business papers use a wide range of sophisticated techniques (sometimes cutting edge).
There is one aspect of software engineering papers written by business school researchers that grates with me, many of the authors obviously don’t understand software engineering from a developer’s perspective; well, obviously, they are business oriented people.
The person who has done the largest amount of interesting software engineering research, whose work I don’t (yet; I will find a way) discuss, is Chris Kemerer; a researcher who has a long list of empirical papers going back to the late 1980s, and rarely gets cited by papers by people in computing departments (I am the only person I know, who limits themself to papers where the data is publicly available).
EDG and Github are both logical purchases for Microsoft
It looks like my prediction that Microsoft buys Github may be about to come true.
Microsoft has been sluggish in integrating their LinkedIn purchase into their identity management system. Lots of sites have verify identity using Github options (or at least the kind of sites I visit do), so perhaps LinkedIn identity will be trialed via Github.
A Github purchase will also allow Microsoft to directly connect lots of developers to Azure. Being able to easily build and execute Github code on Azure is the bait, customer data is where the money is; making Github more data friendly is an obvious first priority for new owners.
Who else should Microsoft buy? As a protective move, I think they should snap up Edison Design Group (EDG) before somebody else does. Readers outside of the compiler/static analysis/C++ standards world are unlikely to have heard of EDG. They sell C/C++ front ends (plus other languages) that support all the historical features/warts supported by other C/C++ compilers. The features only found in Microsoft’s compilers is what make it very costly/time-consuming for many companies to port their applications to other platforms; developer use of Microsoft compiler dependent features is a moat that makes it difficult for many companies to leave the Microsoft ecosystem. EDG have been in the business a long time and have built up an extensive knowledge of vendor specific compiler features; the kind of knowledge that can only be obtained by having customers tell you what language constructs they are using that your current product does not handle (and what those constructs actually mean).
What would happen if a very large company bought EDG, and open sourced its code (to make it easier for Windows developers to switch platforms, not to make any money off compiler related tools)? Somebody would have to bolt on a back-end, to generate code; but that would not be hard (EDG have designed their product to make this easy). A freely available compiler, supporting all/most of the foibles of the Microsoft C++ compiler, would tempt many Windows only developers to give it a go. A free compiler removes management from the loop, developers can try things out as a side project, without having to get management approval to spend money on a compiler (from practical experience I know how hard it is to sell compatible compiler products, i.e., there is no real money to be made by anybody doing this commercially).
Is this risk, to Microsoft, really worth the (relatively) low cost of buying EDG? The EDG guys are not getting any younger, why wouldn’t they be willing sell?
Apps in Space Hackathon
I went along to the Satellite Applications hackathon last weekend. As a teenager I was very much into space flight and with this event being only 30 miles away how could I not attend. Around 25 or so hackers turned up, supported by seven or so knowledgeable and motivated people from the organizers/sponsors. Excellent food+drink, including sending out for Indian/Chinese for dinner. The one important item in short supply was example data to experiment with; the organizers are aware of this and plan to have a lot more data available at the next event.
The rationale for the event is to encourage the creation of business activities in the UK around the increasing amount of data beamed to Earth from satellites. At the moment a satellite image costs something like £100 if its in the back catalog and £10,000 if you want them to take one just for you; the price of images in the back catalog is about to plummet (new satellites coming on stream) and a company is being set up to act as a one stop shop+good user interface for pics (at the moment customers have to talk to a variety of suppliers to find see what’s available). I was excited to hear that I could have my own satellite launched for £100,000, the catch being that they are a bit more expensive to build.
Making use of satellite data requires other data plus support software. Many of the projects people decided to work on needed access to mapping data, e.g., which road is closest to this latitude/longitude. Open Streetmap is the obvious source of mapping data, the UK’s Ordinance Survey have also made some data freely available for public/commercial use. The current problem with this data is the lack of support libraries designed to handle satellite related queries (e.g., return nearest road, town, etc), the existing APIs are good for creating mapping images and dealing with routing.
Support for very large images is one area where existing tools are going to need an upgrade; by very large I mean single image files measured in gigabytes. I did not manage to view any gigabyte image files on my laptop (with 4G of ram), even after going for a coffee and sitting talking to somebody waiting for it to cool before drinking it, still a black rectangle. If the price of satellite images plummets and are easy to buy online, then I can imagine them becoming a discretionary item that people buy for a bit of fun and will then want to view using the devices they already own; telling them that this is not sensible is the wrong answer, the customer is always right and it has to be made to work.
One area where there is good software tool support is working out where satellites will appear in the sky; this is really an astronomical application and there are lots of astronomical tools out there. The Python crowd will be happy to know that scientific-grade astronomy routines are available in Pyephem.
For the most part the hacks created are bullet points of ideas and things to do. The team working on calculating the satellite beam likely to have the strongest signal at a given point on the Earth’s surface made a lot more progress than anybody else. This is because they had an existing Python library to use and ‘only’ needed to apply the trigonometry that we all learn in school.
Some suggestions for the organizers:
- put lightening talks on existing technologies and some of their uses on the agenda (the brief presentation given on SAR was eye opening),
- make some good example data public, i.e., downloadable for all to use. This is the only way to get lots of library support written,
- create cut-down datasets that are usable on laptops. At a Hackathon people can only productively use what they know well and requiring them to use something unfamiliar, such as a virtual machine, is a major road block,
- allow external users to take part, why limit your potential customer base to what can be fitted into a medium size room?
Recent Comments