Archive
Beta release of data analysis chapters: Evidence-based software engineering
When I started my evidence-based software engineering book, nobody had written a data analysis book for software developers, so I had to write one (in fact, a book on this topic has still to be written). When I say “I had to write one”, what I mean is that the 200 pages in the second half of my evidence-based software engineering book contains a concentrated form of such a book.
This 200 pages is now on beta release (it’s 186 pages, if the bibliography is excluded); chapters 8 to 15 of the draft pdf. Originally I was going to wait until all the material was ready, before making a beta release; the Coronavirus changed my plans.
Here is your chance to learn a new skill during the lockdown (yes, these are starting to end; my schedule has not changed, I’m just moving with the times).
All the code+data is available for you to try out any ideas you might have.
The software engineering material, the first half of the book, is also part of the current draft pdf, and the polished form should be available on beta release in about 6 weeks.
If you have a comment or find a problem, either email me or raise an issue on the book’s Github page.
Yes, a few figures and tables still bump into each other. I’m loath to do very fine-tuning because things will shuffle around a bit with minor changes to the words.
I’m thinking of running some online sessions around each chapter. Watch this space for information.
Source code chapter of ‘evidence-based software engineering’ reworked
The Source code chapter of my evidence-based software engineering book has been reworked (draft pdf).
When writing the first version of this chapter, I was not certain whether source code was a topic warranting a chapter to itself, in an evidence-based software engineering book. Now I am certain. Source code is the primary product delivery, for a software system, and it is takes up much of the available cognitive effort.
What are the desirable characteristics that source code should have, to minimise production costs per unit of functionality? This is what an evidence-based chapter on source code is all about.
The release of this chapter completes my second pass over the material. Readers will notice the text still contains ... and ?‘s. The third pass will either delete these, or say something interesting (I suspect mostly the former, because of lack of data).
Talking of data, February has been a bumper month for data (apologies if you responded to my email asking for data, and it has not appeared in this release; a higher than average number of people have replied with data).
The plan is to spend a few months getting a beta release ready. Have the beta release run over the summer, with the book in the shops for Christmas.
I’m looking at getting a few hundred printed, for those wanting paper.
The only publisher that did not mind me making the pdf freely available was MIT Press. Unfortunately one of the reviewers was foaming at the mouth about the things I had to say about software engineering researcher (it did not help that I had written a blog post containing a less than glowing commentary on academic researchers, the week of the review {mid-2017}); the second reviewer was mildly against, and the third recommended it.
If any readers knows the editors at MIT Press, do suggest they have another look at the book. I would rather a real publisher make paper available.
Next, getting the ‘statistics for software engineers’ second half of the book ready for a beta release.
Source code has a brief and lonely existence
The majority of source code has a short lifespan (i.e., a few years), and is only ever modified by one person (i.e., 60%).
Literate programming is all well and good for code written to appear in a book that the author hopes will be read for many years, but this is a tiny sliver of the source code ecosystem. The majority of code is never modified, once written, and does not hang around for very long; an investment is source code futures will make a loss unless the returns are spectacular.
What evidence do I have for these claims?
There is lots of evidence for the code having a short lifespan, and not so much for the number of people modifying it (and none for the number of people reading it).
The lifespan evidence is derived from data in my evidence-based software engineering book, and blog posts on software system lifespans, and survival times of Linux distributions. Lifespan in short because Packages are updated, and third-parties change/delete APIs (things may settle down in the future).
People who think source code has a long lifespan are suffering from survivorship bias, i.e., there are a small percentage of programs that are actively used for many years.
Around 60% of functions are only ever modified by one author; based on a study of the change history of functions in Evolution (114,485 changes to functions over 10 years), and Apache (14,072 changes over 12 years); a study investigating the number of people modifying files in Eclipse. Pointers to other studies that have welcome.
One consequence of the short life expectancy of source code is that, any investment made with the expectation of saving on future maintenance costs needs to return many multiples of the original investment. When many programs don’t live long enough to be maintained, those with a long lifespan have to pay the original investments made in all the source that quickly disappeared.
One benefit of short life expectancy is that most coding mistakes don’t live long enough to trigger a fault experience; the code containing the mistake is deleted or replaced before anybody notices the mistake.
Update: a few days later
I was remiss in not posting some plots for people to look at (code+data).
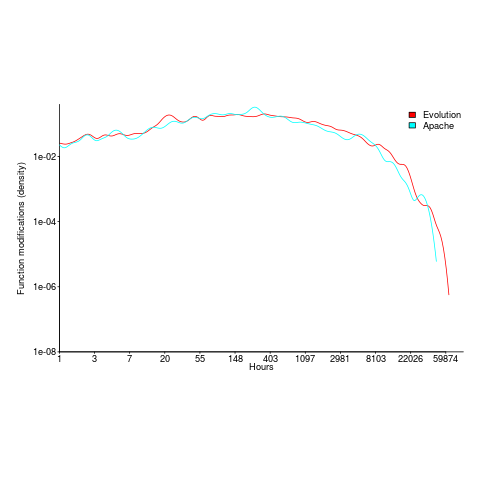
The plot below shows number of function, in Evolution, modified a given number of times (left), and functions modified by a given number of authors (right). The lines are a bi-exponential fit.

What is the interval (in hours) between between modifications of a function? The plot below has a logarithmic x-axis, and is sort-of flat over most of the range (you need to squint a bit). This is roughly saying that the probability of modification in hours 1-3 is the same as in hours 3-7, and hours, 7-15, etc (i.e., keep doubling the hour interval). At round 10,000 hours function modification probability drops like a stone.
The dark-age of software engineering research: some evidence
Looking back, the 1970s appear to be a golden age of software engineering research, with the following decades being the dark ages (i.e., vanity research promoted by ego and bluster), from which we are slowly emerging (a rough timeline).
Lots of evidence-based software engineering research was done in the 1970s, relative to the number of papers published, and I have previously written about the quantity of research done at Rome and the rise of ego and bluster after its fall (Air Force officers studying for a Master’s degree publish as much software engineering data as software engineering academics combined during the 1970s and the next two decades).
What is the evidence for a software engineering research dark ages, starting in the 1980s?
One indicator is the extent to which ancient books are still venerated, and the wisdom of the ancients is still regularly cited.
I claim that my evidence-based software engineering book contains all the useful publicly available software engineering data. The plot below shows the number of papers cited (green) and data available (red), per year; with fitted exponential regression models, and a piecewise regression fit to the data (blue) (code+data).
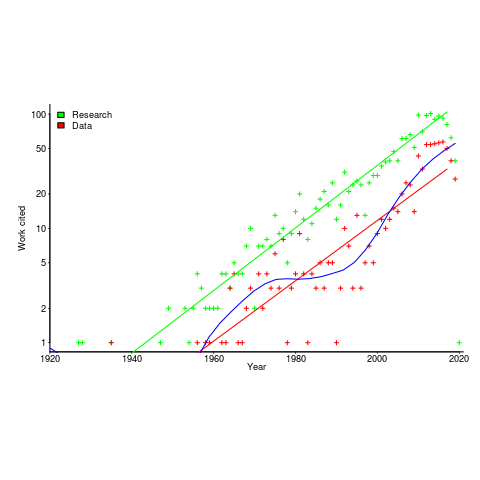
The citations+date include works that are not written by people involved in software engineering research, e.g., psychology, economics and ecology. For the time being I’m assuming that these non-software engineering researchers contribute a fixed percentage per year (the BibTeX file is available if anybody wants to do the break-down)
The two straight line fits are roughly parallel, and show an exponential growth over the years.
The piecewise regression (blue, loess was used) shows that the rate of growth in research data leveled-off in the late 1970s and only started to pick up again in the 1990s.
The dip in counts during the last few years is likely to be the result of me not having yet located all the recent empirical research.
Reliability chapter of ‘evidence-based software engineering’ updated
The Reliability chapter of my evidence-based software engineering book has been updated (draft pdf).
Unlike the earlier chapters, there were no major changes to the initial version from over 18-months ago; we just don’t know much about software reliability, and there is not much public data.
There are lots of papers published claiming to be about software reliability, but they are mostly smoke-and-mirror shows derived from work down one of several popular rabbit holes:
- Machine learning is a popular technique for fault prediction, and I have written about what a train wreck this research is, along with the incomplete and very noisy data that makes nearly every attempt at fault prediction a waste of time.
- Mutation testing sounds like a technique that would be useful (and it is for pumping out papers), but it has the fatal flaw of telling people what they already know (i.e., that their test suites are not very good), and targeting coding mistakes that represent around 5% of known fault experiences (around 5% of all fixes to reported faults involve changing one line; most mutation testing works by modifying a single line of code).
- Other researchers are busily adding more epicycles to models based on the nonhomogeneous Poisson process.
The growth in research on Fuzzing is the only good news (especially with the availability of practical introductory material).
There is one source of fault experience data that looks like it might be very useful, but it’s hard to get hold of; NASA has kept detailed about what happened using space missions. I have had several people promise to send me data, but none has arrived yet :-(.
Updating the reliability chapter did not take too much time, so I updated earlier chapters with data that has arrived since they were last released.
As always, if you know of any interesting software engineering data, please tell me.
Next, the Source code chapter.
Projects chapter of ‘evidence-based software engineering’ reworked
The Projects chapter of my evidence-based software engineering book has been reworked; draft pdf available here.
A lot of developers spend their time working on projects, and there ought to be loads of data available. But, as we all know, few companies measure anything, and fewer hang on to the data.
Every now and again I actively contact companies asking data, but work on the book prevents me spending more time doing this. Data is out there, it’s a matter of asking the right people.
There is enough evidence in this chapter to slice-and-dice much of the nonsense that passes for software project wisdom. The problem is, there is no evidence to suggest what might be useful and effective theories of software development. My experience is that there is no point in debunking folktales unless there is something available to replace them. Nature abhors a vacuum; a debunked theory has to be replaced by something else, otherwise people continue with their existing beliefs.
There is still some polishing to be done, and a few promises of data need to be chased-up.
As always, if you know of any interesting software engineering data, please tell me.
Next, the Reliability chapter.
Ecosystems chapter of “evidence-based software engineering” reworked
The Ecosystems chapter of my evidence-based software engineering book has been reworked (I have given up on the idea that this second pass is also where the polishing happens; polishing still needs to happen, and there might be more material migration between chapters); download here.
I have been reading books on biological ecosystems, and a few on social ecosystems. These contain lots of interesting ideas, but the problem is, software ecosystems are just very different, e.g., replication costs are effectively zero, source code does not replicate itself (and is not self-evolving; evolution happens because people change it), and resources are exchanged rather than flowing (e.g., people make deals, they don’t get eaten for lunch). Lots of caution is needed when applying ecosystem related theories from biology, the underlying assumptions probably don’t hold.
There is a surprising amount of discussion on the computing world as it was many decades ago. This is because ecosystem evolution is path dependent; understanding where we are today requires knowing something about what things were like in the past. Computer memory capacity used to be a big thing (because it was often measured in kilobytes); memory does not get much publicity because the major cpu vendor (Intel) spends a small fortune on telling people that the processor is the most important component inside a computer.
There are a huge variety of software ecosystems, but you would not know this after reading the ecosystems chapter. This is because the work of most researchers has been focused on what used to be called the desktop market, which over the last few years the focus has been shifting to mobile. There is not much software engineering research focusing on embedded systems (a vast market), or supercomputers (a small market, with lots of money), or mainframes (yes, this market is still going strong). As the author of an evidence-based book, I have to go where the data takes me; no data, then I don’t have anything to say.
Empirical research (as it’s known in academia) needs data, and the ‘easy’ to get data is what most researchers use. For instance, researchers analyzing invention and innovation invariably use data on patents granted, because this data is readily available (plus everybody else uses it). For empirical research on software ecosystems, the readily available data are package repositories and the Google/Apple Apps stores (which is what everybody uses).
The major software ecosystems barely mentioned by researchers are the customer ecosystem (the people who pay for everything), the vendors (the companies in the software business) and the developer ecosystem (the people who do the work).
Next, the Projects chapter.
My book’s pdf generation workflow
The process used to generate the pdf of my evidence-based software engineering book has been on my list of things to blog about, for ever. An email arrived this afternoon, asking how I produced various effects using Asciidoc; this post probably contains rather more than N. Psaris wanted to know.
It’s very easy to get sucked into fiddling around with page layout and different effects. So, unless I am about to make a release of a draft, I only generate a pdf once, at the end of each month.
At the end of the month the text is spell checked using aspell, and then grammar checked using Language tool. I have an awk script that checks the text for mistakes I have made in the past; this rarely matches, i.e., I seem to be forever making different mistakes.
The sequencing of tools is: R (Sweave) -> Asciidoc -> docbook -> LaTeX -> pdf; assorted scripts fiddle with the text between outputs and inputs. The scripts and files mention below are available for download.
R generates pdf files (via calls to the Sweave function, I have never gotten around to investigating Knitr; the pdfs are cropped using scripts/pdfcrop.sh) and the ascii package is used to produce a few tables with Asciidoc markup.
Asciidoc is the markup language used for writing the text. A few years after I started writing the book, Stuart Rackham, the creator of Asciidoc, decided to move on from working and supporting it. Unfortunately nobody stepped forward to take over the project; not a problem, Asciidoc just works (somebody did step forward to reimplement the functionality in Ruby; Asciidoctor has an active community, but there is no incentive for me to change). In my case, the output from Asciidoc is xml (it supports a variety of formats).
Docbook appears in the sequence because Asciidoc uses it to produce LaTeX. Docbook takes xml as input, and generates LaTeX as output. Back in the day, Docbook was hailed as the solution to all our publishing needs, and wonderful tools were going to be created to enable people to produce great looking documents.
LaTeX is the obvious tool for anybody wanting to produce lovely looking books and articles; tex/ESEUR.tex is the top-level LaTeX, which includes the generated text. Yes, LaTeX is a markup language, and I could have written the text using it. As a language I find LaTeX too low level. My requirements are not complicated, and I find it easier to write using a markup language like Asciidoc.
The input to Asciidoc and LuaTeX (used to generate pdf from LaTeX) is preprocessed by scripts (written using sed and awk; see scripts/mkpdf). These scripts implement functionality that Asciidoc does not support (or at least I could see how to do it without modifying the Python source). Scripts are a simple way of providing the extra functionality, that does not require me to remember details about the internals of Asciidoc. If Asciidoc was being actively maintained, I would probably have worked to get some of the functionality integrated into a future release.
There are a few techniques for keeping text processing scripts simple. For instance, the cost of a pass over text is tiny, there is little to be gained by trying to do everything in one pass; handling the possibility that markup spans multiple lines can be complicated, a simple solution is to join consecutive lines together if there is a possibility that markup spans these lines (i.e., the actual matching and conversion no longer has to worry about line breaks).
Many simple features are implemented by a script modifying Asciidoc text to include some ‘magic’ sequence of characters, which is subsequently matched and converted in the generated LaTeX, e.g., special characters, and hyperlinks in the pdf.
A more complicated example handles my desire to specify that a figure appear in the margin; the LaTeX sidenotes package supports figures in margins, but Asciidoc has no way of specifying this behavior. The solution was to add the word “Margin”, to the appropriate figure caption option (in the original Asciidoc text, e.g., [caption="Margin ", label=CSD-95-887]), and have a script modify the LaTeX generated by docbook so that figures containing “Margin” in the caption invoked the appropriate macro from the sidenotes package.
There are still formatting issues waiting to be solved. For instance, some tables are narrow enough to fit in the margin, but I have not found a way of embedding this information in the table information that survives through to the generated LaTeX.
My long time pet hate is the formatting used by R’s plot function for exponentiated values as axis labels. My target audience are likely to be casual users of R, so I am sticking with basic plotting (i.e., no calls to ggplot). I do wish the core R team would integrate the code from the magicaxis package, to bring the printing of axis values into the era of laser printers and bit-mapped displays.
Ideas and suggestions welcome.
Cognitive capitalism chapter reworked
The Cognitive capitalism chapter of my evidence-based software engineering book took longer than expected to polish; in fact it got reworked, rather than polished (which still needs to happen, and there might be more text moving from other chapters).
Changing the chapter title, from Economics to Cognitive capitalism, helped clarify lots of decisions about the subject matter it ought to contain (the growth in chapter page count is more down to material moving from other chapters, than lots of new words from me).
I over-spent time down some interesting rabbit holes (e.g., real options), before realising that no public data was available, and unlikely to be available any time soon. Without data, there is not a lot that can be said in a data driven book.
Social learning is a criminally under researched topic in software engineering. Some very interesting work has been done by biologists (e.g., Joseph Henrich, and Kevin Laland), in the last 15 years; the field has taken off. There is a huge amount of social learning going on in software engineering, and virtually nobody is investigating it.
As always, if you know of any interesting software engineering data, please let me know.
Next, the Ecosystems chapter.
Polished human cognitive characteristics chapter
It has been just over two years since I release the first draft of the Human cognitive characteristics chapter of my evidence-based software engineering book. As new material was discovered, it got added where it seemed to belong (at the time), no effort was invested in maintaining any degree of coherence.
The plan was to find enough material to paint a coherence picture of the impact of human cognitive characteristics on software engineering. In practice, finishing the book in a reasonable time-frame requires that I stop looking for new material (assuming it exists), and go with what is currently available. There are a few datasets that have been promised, and having these would help fill some holes in the later sections.
The material has been reorganized into what is essentially a pass over what I think are the major issues, discussed via studies for which I have data (the rule of requiring data for a topic to be discussed, gets bent out of shape the most in this chapter), presented in almost a bullet point-like style. At least there are plenty of figures for people to look at, and they are in color.
I think the material will convince readers that human cognition is a crucial topic in software development; download the draft pdf.
Model building by cognitive psychologists is starting to become popular, with probabilistic languages, such as JAGS and Stan, becoming widely used. I was hoping to build models like this for software engineering tasks, but it would have taken too much time, and will have to wait until the book is done.
As always, if you know of any interesting software engineering data, please let me know.
Next, the cognitive capitalism chapter.
Recent Comments