Archive
Fifth anniversary of Evidence-based Software Engineering book
Yesterday was the 5th anniversary of the publication of my book Evidence-based Software Engineering.
The general research trajectory I was expecting in the 2020s (e.g., more sophisticated statistical analysis and more evidence based studies) has been derailed by the arrival of LLMs three years ago. Almost all software engineering researchers have jumped on the LLM bandwagon, studying whatever LLM use case is likely to result in a published paper. While I have noticed more papers using statistical techniques discovered after the digital computer was invented (perhaps influenced by the second half of the book), there seems to be a lot fewer evidence based papers being published. I don’t expect researches studying software engineering to jump off the LLM bandwagon in the next few years.
The net result of this lack of new research findings is that the book contents are not yet in need of an update.
On a positive note, LLMs’ mathematical problem-solving capabilities have significantly reduced the time needed to analyse models of software engineering processes.
Had today’s LLMs been available while I was writing the book, the text would probably have included many more theoretical models and their analysis. ‘Probably’, because sometimes the analysis finds that a model does not provide meaningfully mimic reality, so it’s possible that only a few more models would have been included.
My plan for the next year is to use LLM’s mathematical problem-solving capabilities to help me analyse models of software engineering processes. A discussion of any interested results found will appear on this blog. I’m hoping that there will be active conversations on the evidence based software engineering Discord channel.
It makes sense to hone my model analysis skills by starting with the subject I am most familiar with, i.e., source code. It also helps that tools are available for obtaining more source measurement data.
I will continue to write about any interesting papers that appear on the arXiv lists cs.se and cs.PL, as well as the major conferences. There won’t be time to track the minor conferences.
Questions raised during model analysis sometimes suggest ideas that, when searched for, lead to new data being discovered. Discovering new data using a previously untried search phrase is always surprising.
Data+code for book: The New C Standard
All the data+code from my book The New C Standard: An Economic and Cultural Commentary is now available on GitHub. For many years I have been meaning to create an easy way to map from a graph/table in the book to the file containing the data, which has blocked me adding the data to GitHub. I have unblocked by releasing this minimal viable product, i.e., it is essentially a copy of the usage subdirectory in the book’s directory.
While the five stage process to get from graph/table to data is tedious, at least there is a process that provides the data. The caption of the graphs in my Evidence-based Software Engineering book contain a link to the corresponding file on GitHub. This was not possible for the C book because GitHub was still 3-years in the future when the book was published (in 2005).
Work on the book started in late 1999 and measurements of C usage was an integral component. Publicly available source code was still a novelty and large Open source projects were rare (SourceForge was launched at the end of 1999). The large projects with C source available to measure were: Linux, Netscape, Gcc, PostgresSQL, OpenAFS, and OpenMotif. Several popular projects originally written in C had migrated to using C++, and were therefore not applicable.
As the book was completed in 2005, evidence-based software engineering restarted, 20-years after the fall of Rome. Or rather, I have nominated 2005 as the year this happened. Feel free to quibble plus/minus a few years.
Search engines were an essential tool for obtaining research papers, reports, and occasionally downloading data. In 2000 the search engine of choice was AltaVista, but a few years later Google had become the best.
While writing the book, I was a regular visitor to bricks and mortar buildings called libraries. Back then, university libraries contained tens of thousands of physical books, and researchers would photocopy papers of interest. Little did I know that this research practice would soon be dead.
In 2005, I had this to say about software evolution:
Measuring the characteristics of software that change over many releases (software evolution) is a relatively new research topic. Software evolution is discussed in a few sentences, and any future major revision ought to cover this important topic in substantially more detail. |
How might C source code characteristics have changed in the last 20 years?
- The use of K&R style function definitions is probably very rare; it was well on the way out in 1999,
- big software systems have gotten bigger, i.e., more lines of code and more
#includes, - A lot more code using 32-bit integers and 64-bit pointers,
- More storage allocated (memory capacity has increased) because it’s faster to do everything in memory, and there is more data.
Evidence-based Software Engineering book: the last year
It’s now three years since my book, Evidence-based Software Engineering: based on the publicly available data, was released. What has happened in the last year, since I wrote about the first two years, and what might happen in the next year or so?
There is now a Discord channel for discussing evidence-based software engineering. Blog readers and anyone with an interest in the subject are most welcome.
I keep a copy of software related papers that I think might be worth looking at again, and have been meaning to make this list public. A question by ysch, a Discord channel member, asked after ways of checking whether a software paper was worth reading. This prompted me to create a Github repo containing the titles of these 7,756 saved papers, along with some data related annotations. On the more general question of paper quality, my view is that most papers are not worth reading, with a few being very well worth reading. People have to develop techniques for rapidly filtering out the high volume of drivel; techniques I use, and understanding the publication ecosystem.
This last year saw the sudden arrival of a new tool, LLMs. My experience with using ChatGPT (and other such LLMs) as an evidence-based research tool is that the answers are too generic or just plain wrong (for several months, one LLM reported that I had a degree in Divinity Studies). If I was writing a book, I suspect that they would provide a worthwhile copy-editing service.
I was hoping that the recently released GPT-4 vision model would do high quality text extraction from scanned pdfs, but the quality of output I have received is about the same as traditional OCR-based tools. I expect that the data extraction ability LLM based tools will get a lot better, because they are at the start of the learning curve and there is a commercial incentive for them to be a lot better.
An LLM is driven by the token weights learned during training. Roughly speaking, the more training data on a topic, the larger the trained weights for that topic. There is not a lot of data (i.e., text) relating to evidence-based software engineering, compared to the huge quantities available for some topics, so responses are generic and often parrot established folklore. The following image was generated by DALL-E3:

There is a tale of software product evolution waiting to be told via the data contained in magazine adverts; the magazines are on bitsavers, we just need LLMs to be good enough to reliably extract advert contents (currently, too many hallucinations).
The book contents continue to survive almost completely unscathed, primarily because reader feedback continues to be almost non-existent. Despite the close to 500k downloads (now averaging 4k-5k downloads per month, from the logs I have, with the mobile friendly version around 10%), most people I meet have not heard of the book. The concept of an evidence-based approach to software engineering continues to be met with blank looks, although a commonly cited listener use case for the book’s data is validating a pet theory (my suggestion that the data may show their pet theory to be wrong is not appreciated).
Analysis/data in the following blog posts, from the last 12-months, belongs in the book in some form or other:
Some human biases in conditional reasoning
Unneeded requirements implemented in Waterfall & Agile
Analysis of Cost Performance Index for 338 projects
Evaluating Story point estimation error
Frequency of non-linear relationships in software engineering data
Analysis of when refactoring becomes cost-effective
An evidence-based software engineering book from 2002
Perturbed expressions may ‘recover’
Predicting the size of the Linux kernel binary
Local variable naming: some previously unexplored factors
Optimal function length: an analysis of the cited data
Some data on the size of Cobol programs/paragraphs
Hardware/Software cost ratio folklore
Criteria for increased productivity investment
Likelihood of encountering a given sequence of statements
Evidence-based Software Engineering book: two years later
Two years ago, my book Evidence-based Software Engineering: based on the publicly available data was released. The first two weeks saw 0.25 million downloads, and 0.5 million after six months. The paperback version on Amazon has sold perhaps 20 copies.
How have the book contents fared, and how well has my claim to have discussed all the publicly available software engineering data stood up?
The contents have survived almost completely unscathed. This is primarily because reader feedback has been almost non-existent, and I have hardly spent any time rereading it.
In the last two years I have discovered maybe a dozen software engineering datasets that would have been included, had I known about them, and maybe another dozen non-software related datasets that could have been included in the Human behavior/Cognitive capitalism/Ecosystems/Reliability chapters. About half of these have been the subject of blog posts (links below), with the others waiting to be covered.
Each dataset provides a sliver of insight into the much larger picture that is software engineering; joining the appropriate dots, by analyzing multiple datasets, can provide a larger sliver of insight into the bigger picture. I have not spent much time attempting to join dots, but have joined a few tiny ones, and a few that are not so small, e.g., Estimating using a granular sequence of values and Task backlog waiting times are power laws.
I spent the first year, after the book came out, working through the backlog of tasks that had built up during the 10-years of writing. The second year was mostly dedicated to trying to find software project data (including joining Twitter), and reading papers at a much reduced rate.
The plot below shows the number of monthly downloads of the A4 and mobile friendly pdfs, along with the average kbytes per download (code+data):
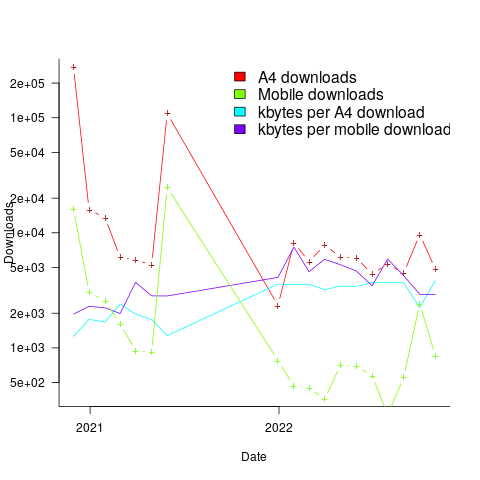
The monthly averages for 2022 are around 6K A4 and 700 mobile friendly pdfs.
I have been averaging one in-person meetup per week in London. Nearly everybody I tell about the book has not previously heard of it.
The following is a list of blog posts either analyzing existing data or discussing/analyzing new data.
Introduction
analysis: Software effort estimation is mostly fake research
analysis: Moore’s law was a socially constructed project
Human behavior
data (reasoning): The impact of believability on reasoning performance
data: The Approximate Number System and software estimating
data (social conformance): How large an impact does social conformity have on estimates?
data (anchoring): Estimating quantities from several hundred to several thousand
data: Cognitive effort, whatever it might be
Ecosystems
data: Growth in number of packages for widely used languages
data: Analysis of a subset of the Linux Counter data
data: Overview of broad US data on IT job hiring/firing and quitting
Projects
analysis: Delphi and group estimation
analysis: The CESAW dataset: a brief introduction
analysis: Parkinson’s law, striving to meet a deadline, or happenstance?
analysis: Evaluating estimation performance
analysis: Complex software makes economic sense
analysis: Cost-effectiveness decision for fixing a known coding mistake
analysis: Optimal sizing of a product backlog
analysis: Evolution of the DORA metrics
analysis: Two failed software development projects in the High Court
data: Pomodoros worked during a day: an analysis of Alex’s data
data: Multi-state survival modeling of a Jira issues snapshot
data: Over/under estimation factor for ‘most estimates’
data: Estimation accuracy in the (building|road) construction industry
data: Rounding and heaping in non-software estimates
data: Patterns in the LSST:DM Sprint/Story-point/Story ‘done’ issues
data: Shopper estimates of the total value of items in their basket
Reliability
analysis: Most percentages are more than half
Statistical techniques
Fitting discontinuous data from disparate sources
Testing rounded data for a circular uniform distribution
Post 2020 data
Pomodoros worked during a day: an analysis of Alex’s data
Impact of number of files on number of review comments
Finding patterns in construction project drawing creation dates
Evidence-based Software Engineering: now in paperback form
I made my Evidence-based Software Engineering book available as a pdf file. While making a printed version available looked possible, I was uncertain that the result would be of acceptable quality; the extensive use of color and an A4 page size restricted the number of available printers who could handle it. Email exchanges with several publishers suggested that the number of likely print edition copies sold would be small (based on experience with other books, under 100). The pdf was made available under a creative commons license.
Around half-million copies of the pdf have been downloaded (some partially).
A few weeks ago, I spotted a print version of this book on Amazon (USA). I have no idea who made this available. Is the quality any good? I was told that it was, so I bought a copy.
The printed version looks great, with vibrant colors, and is reasonably priced. It sits well in the hand, while reading. The links obviously don’t work for the paper version, but I’m well practised at using multiple fingers to record different book locations.
I have one report that the Kindle version doesn’t load on a Kindle or the web app.
If you love printed books, I heartily recommend the paperback version of Evidence-based Software Engineering; it even has a 5-star review on Amazon 😉
Evidence-based book: six months of downloads
When my C book was first made available as a freely downloadable pdf, in 2005, there were between 19k to 37k downloads in the first week. The monthly download rate remained stable at around 1k per month for several years, and now floats around 100 per month.
I was hoping to have many more downloads for my Evidence-based software engineering book. The pdf became available last year on November 8th, and there were around 10k downloads in the first week. Then a link to my blog post announcing the availability of the book was posted to news.ycombinator. That generated quarter million downloads of the pdf, with an end-of-month figure of 275,309 plus 16,135 for the mobile friendly version.
The initial release did not include a mobile friendly version. After a half-a-dozen or so requests in various forums, I quickly worked up a mobile friendly pdf (i.e., the line length was reduced to be visually readable on a mobile phone, or at least on my 7-year-old phone which is smaller than most).
In May a link to the book’s webpage was posted on news.ycombinator. This generated 125k+ downloads, and the top-rated comment was that this was effectively a duplicate of the November post.
The plot below shows the number of pdf downloads for A4 and mobile formats, along with the number of kilo-bytes downloaded, for the 6-months since the initial release (code+data):
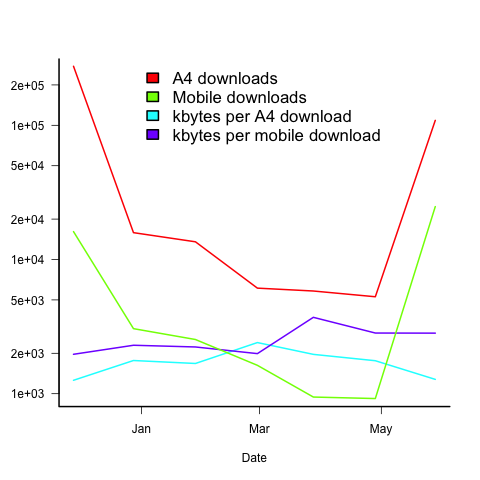
On average, there are five A4 downloads per mobile download (excluding November because of the later arrival of a mobile friendly version).
A download is rarely a complete copy (which is 23Mbyte), with the 6-month average being 1.7M for A4 and 2.5M for mobile. I have no idea of the reason for this difference.
The bytes per download is lower in the months when the ycombinator activity occurred. Is this because the ycombinator crowd tend to skim content (based on some of the comments, I suspect that many comments never read further than the cover)?
Copies of the pdf were made available on other sites, but based on the data I have seen, the downloads were not more than a few thousand.
I have not had any traffic spikes caused by non-English language interest. The C book experienced a ‘China’ spike, and I emailed the author of the blog post that caused it, to notify him of the Evidence-based book; he kindly posted an article on the book, but this did not generate a noticeable spike.
I’m confident that eventually a person in China/Russia/India/etc, with tens of thousands of followers, will post a link and there will be a noticeable download spike from that region.
What was the impact of content delivery networks and ISP caching? I have no idea. Pointers to write-ups on the topic welcome.
What impact might my evidence-based book have in 2021?
What impact might the release of my evidence-based software engineering book have on software engineering in 2021?
Lots of people have seen the book. The release triggered a quarter of a million downloads, or rather it getting linked to on Twitter and Hacker News resulted in this quantity of downloads. Looking at the some of the comments on Hacker News, I suspect that many ‘readers’ did not progress much further than looking at the cover. Some have scanned through it expecting to find answers to a question that interests them, but all they found was disconnected results from a scattering of studies, i.e., the current state of the field.
The evidence that source code has a short and lonely existence is a gift to those seeking to save time/money by employing a quick and dirty approach to software development. Yes, there are some applications where a quick and dirty iterative approach is not a good idea (iterative as in, if we make enough money there will be a version 2), the software controlling aircraft landing wheels being an obvious example (if the wheels don’t deploy, telling the pilot to fly to another airport to see if they work there is not really an option).
There will be a few researchers who pick up an idea from something in the book, and run with it; I have had a couple of emails along this line, mostly from just starting out PhD students. It would be naive to think that lots of researchers will make any significant changes to their existing views on software engineering. Planck was correct to say that science advances one funeral at a time.
I’m hoping that the book will produce a significant improvement in the primitive statistical techniques currently used by many software researchers. At the moment some form of Wilcoxon test, invented in 1945, is the level of statistical sophistication wielded in most software engineering papers (that do any data analysis).
Software engineering research has the feeling of being a disjoint collection of results, and I’m hoping that a few people will be interested in starting to join the dots, i.e., making connections between findings from different studies. There are likely to be a limited number of major dot joinings, and so only a few dedicated people are needed to make it happen. Why hasn’t this happened yet? I think that many academics in computing departments are lifestyle researchers, moving from one project to the next, enjoying the lifestyle, with little interest in any research results once the grant money runs out (apart from trying to get others to cite it). Why do I think this? I have emailed many researchers information about the patterns I have found in the data they sent me, and a common response is almost completely disinterest (some were interested) in any connections to other work.
What impact do you think ‘all’ the evidence presented will have?
Evidence-based software engineering: book released
My book, Evidence-based software engineering, is now available; the pdf can be downloaded here, here and here, plus all the code+data. Report any issues here. I’m investigating the possibility of a printed version. Mobile friendly pdf (layout shaky in places).
The original goals of the book, from 10-years ago, have been met, i.e., discuss what is currently known about software engineering based on an analysis of all the publicly available software engineering data, and having the pdf+data+code freely available for download. The definition of “all the public data” started out as being “all”, but as larger and higher quality data was discovered the corresponding were ignored.
The intended audience has always been software developers and their managers. Some experience of building software systems is assumed.
How much data is there? The data directory contains 1,142 csv files and 985 R files, the book cites 895 papers that have data available of which 556 are cited in figure captions; there are 628 figures. I am currently quoting the figure of 600+ for the ‘amount of data’.

Things that might be learned from the analysis has been discussed in previous posts on the chapters: Human cognition, Cognitive capitalism, Ecosystems, Projects and Reliability.
The analysis of the available data is like a join-the-dots puzzle, except that the 600+ dots are not numbered, some of them are actually specs of dust, and many dots are likely to be missing. The future of software engineering research is joining the dots to build an understanding of the processes involved in building and maintaining software systems; work is also needed to replicate some of the dots to confirm that they are not specs of dust, and to discover missing dots.
Some missing dots are very important. For instance, there is almost no data on software use, but there can be lots of data on fault experiences. Without software usage data it is not possible to estimate whether the software is very reliable (i.e., few faults experienced per amount of use), or very unreliable (i.e., many faults experienced per amount of use).
The book treats the creation of software systems as an economically motivated cognitive activity occurring within one or more ecosystems. Algorithms are now commodities and are not discussed. The labour of the cognitariate is the means of production of software systems, and this is the focus of the discussion.
Existing books treat the creation of software as a craft activity, with developers applying the skills and know-how acquired through personal practical experience. The craft approach has survived because building software systems has been a sellers market, customers have paid what it takes because the potential benefits have been so much greater than the costs.
Is software development shifting from being a sellers market to a buyers market? In a competitive market for development work and staff, paying people to learn from mistakes that have already been made by many others is an unaffordable luxury; an engineering approach, derived from evidence, is a lot more cost-effective than craft development.
As always, if you know of any interesting software engineering data, please let me know.
The Weirdest people in the world
Western, Educated, Industrialized, Rich and Democratic: WEIRD people are the subject of Joseph Henrich’s latest book “The Weirdest People in the World: How the West Became Psychologically Peculiar and Particularly Prosperous”.
This book is in the mold of Jared Diamond’s Guns, Germs, and Steel: The Fates of Human Societies, but comes at the topic from a psychological/sociological angle.
This very readable book is essential reading for anyone wanting to understand how very different WEIRD people are, along with the societies they have created, compared to people and societies in the rest of the world today and the entire world up until around 500 years ago.
The analysis of WEIRD people/societies has three components: why we are different (I’m assuming that most of this blog’s readers are WEIRD), the important differences that are known about, and the cultural/societal consequences (the particularly prosperous in the subtitle is a big clue).
Henrich cites data to back up his theories.
Starting around 1,500 years ago the Catholic church started enforcing a ban on cousin marriage, which was an almost universal practice at the time and is still widely practiced in non-WEIRD societies. Over time the rules got stricter, until by the 11th century people were not allowed to marry anyone related out to their sixth cousin. The rules were not always strictly enforced, as Henrich documents, but the effect was to change the organization of society from being kin-based to being institution-based (in particular institutions such as the Church and state). Finding a wife/husband required people to interact with others outside their extended family.
Effects claimed, operating over centuries, of the shift from extended families to nuclear families are that people learned what Henrich calls “impersonal prosociality”, e.g., feeling comfortable dealing with strangers. People became more altruistic, the impartial rule of law spread (including democracy and human rights), plus other behaviors needed for the smooth running of large social units (such as towns, cities and countries).
The overall impact was that social units of WEIRD people could grow to include tens of thousands, even millions, or people, and successfully operate at this scale. Information about beneficial inventions could diffuse rapidly and people were free(ish) to try out new things (i.e., they were not held back by family customs), and operating in a society with free movement of people there were lots of efficiencies, e.g., companies were not obligated to hire family members, and could hire the best person they could find.
Consequently, the West got to take full advantage of scientific progress, invent and mass produce stuff. Outcompeting the non-WEIRD world.
The big ideas kind of hang together. Some of the details seem like a bit of a stretch, but I’m no expert.
My WEIRD story occurred about five years ago, when I was looking for a publisher for the book I was working on. One interested editor sent out an early draft for review. One of the chapters discusses human cognition, and I pointed out that it did not matter that most psychology experiments had been done using WEIRD subjects, because software developers were WEIRD (citing Henrich’s 2010 WEIRD paper). This discussion of WEIRD people was just too much for one of the reviewers, who sounded like he was foaming at the mouth when reviewing my draft (I also said a few things about academic researchers that upset him).
Learning useful stuff from the Projects chapter of my book
What useful, practical things might professional software developers learn from the Projects chapter in my evidence-based software engineering book?
This week I checked the projects chapter; what useful things did I learn (combined with everything I learned during all the other weeks spent working on this chapter)?
There turned out to be around three to four times more data publicly available than I had first thought. This is good, but there is a trap for the unweary. For many topics there is one data set, and that one data set may not be representative. What is needed is a selection of data from various sources, all relating to a given topic.
Some data is better than no data, provided small data sets are treated with caution.
Estimation is a popular research topic: how long will a project take and how much will it cost.
After reading all the papers I learned that existing estimation models are even more unreliable than I had thought, and what is more, there are plenty of published benchmarks showing how unreliable the models really are (these papers never seem to get cited).
Models that include lines of code in the estimation process (i.e., the majority of models) need a good estimate of the likely number of lines in the final software system. One issue that nobody had considered was the impact of developer variability on the number of lines written to implement the same functionality, which turns out to be large. Oops.
Machine learning has infested effort estimation research. What the machine learning models actually do is estimate adjustment, i.e., they do not create their own estimate but adjust one passed in as input to the model. Most estimation data sets are tiny, and only contain a few different variables; unless the estimate is included in the training phase, the generated model produces laughable results. Oops.
The good news is that there appear to be lots of recurring patterns in the project data. This is good news because recurring patterns are something to be explained by a theory of software project development (apparent randomness is bad news, from the perspective of coming up with a model of what is going on). I think we are still a long way from having workable theories, but seeing patterns is a good sign that one or more theories will be possible.
I think that the main takeaway from this chapter is that software often has a short lifetime. People in industry probably have a vague feeling that this is true, from experience with short-lived projects. It is not cost effective to approach commercial software development from the perspective that the code will live a long time; some code does live a long time, but most dies young. I see the implications of this reality being a major source of contention with those in academia who have spent too long babbling away in front of teenagers (teaching the creation of idealized software that lives on forever), and little or no time building software systems.
A lot of software is written by teams of people, however, there is not a lot of data available on teams (software or otherwise). Given the difficulty of hiring developers, companies have to make do with what they have, so a theory of software teams might not be that useful in practice.
Readers might have a completely different learning experience from reading the projects chapter. What useful things did you learn from the projects chapter?
Recent Comments