Archive
How useful are automatically generated compiler tests?
Over the last decade, testing compilers using automatically generated source code has been a popular research topic (for those working in the compiler field; Csmith kicked off this interest). Compilers are large complicated programs, and they will always contain mistakes that lead to faults being experienced. Previous posts of mine have raised two issues on the use of automatically generated tests: a financial issue (i.e., fixing reported faults costs money {most of the work on gcc and llvm is done by people working for large companies}, and is intended to benefit users not researchers seeking bragging rights for their latest paper), and applicability issue (i.e., human written code has particular characteristics and unless automatically generated code has very similar characteristics the mistakes it finds are unlikely to commonly occur in practice).
My claim that mistakes in compilers found by automatically generated code are unlikely to be the kind of mistakes that often lead to a fault in the compilation of human written code is based on the observations (I don’t have any experimental evidence): the characteristics of automatically generated source is very different from human written code (I know this from measurements of lots of code), and this difference results in parts of the compiler that are infrequently executed by human written code being more frequently executed (increasing the likelihood of a mistake being uncovered; an observation based on my years working on compilers).
An interesting new paper, Compiler Fuzzing: How Much Does It Matter?, investigated the extent to which fault experiences produced by automatically generated source are representative of fault experiences produced by human written code. The first author of the paper, Michaël Marcozzi, gave a talk about this work at the Papers We Love workshop last Sunday (videos available).
The question was attacked head on. The researchers instrumented the code in the LLVM compiler that was modified to fix 45 reported faults (27 from four fuzzing tools, 10 from human written code, and 8 from a formal verifier); the following is an example of instrumented code:
warn ("Fixing patch reached"); if (Not.isPowerOf2()) { if (!(C-> getValue().isPowerOf2() // Check needed to fix fault && Not != C->getValue())) { warn("Fault possibly triggered"); } else { /* CODE TRANSFORMATION */ } } // Original, unfixed code |
The instrumented compiler was used to build 309 Debian packages (around 10 million lines of C/C++). The output from the builds were (possibly miscompiled) built versions of the packages, and log files (from which information could be extracted on the number of times the fixing patches were reached, and the number of cases where the check needed to fix the fault was triggered).
Each built package was then checked using its respective test suite; a package built from miscompiled code may successfully pass its test suite.
A bitwise compare was run on the program executables generated by the unfixed and fixed compilers.
The following (taken from Marcozzi’s slides) shows the percentage of packages where the fixing patch was reached during the build, the percentages of packages where code added to fix a fault was triggered, the percentage where a different binary was generated, and the percentages of packages where a failure was detected when running each package’s tests (0.01% is one failure):
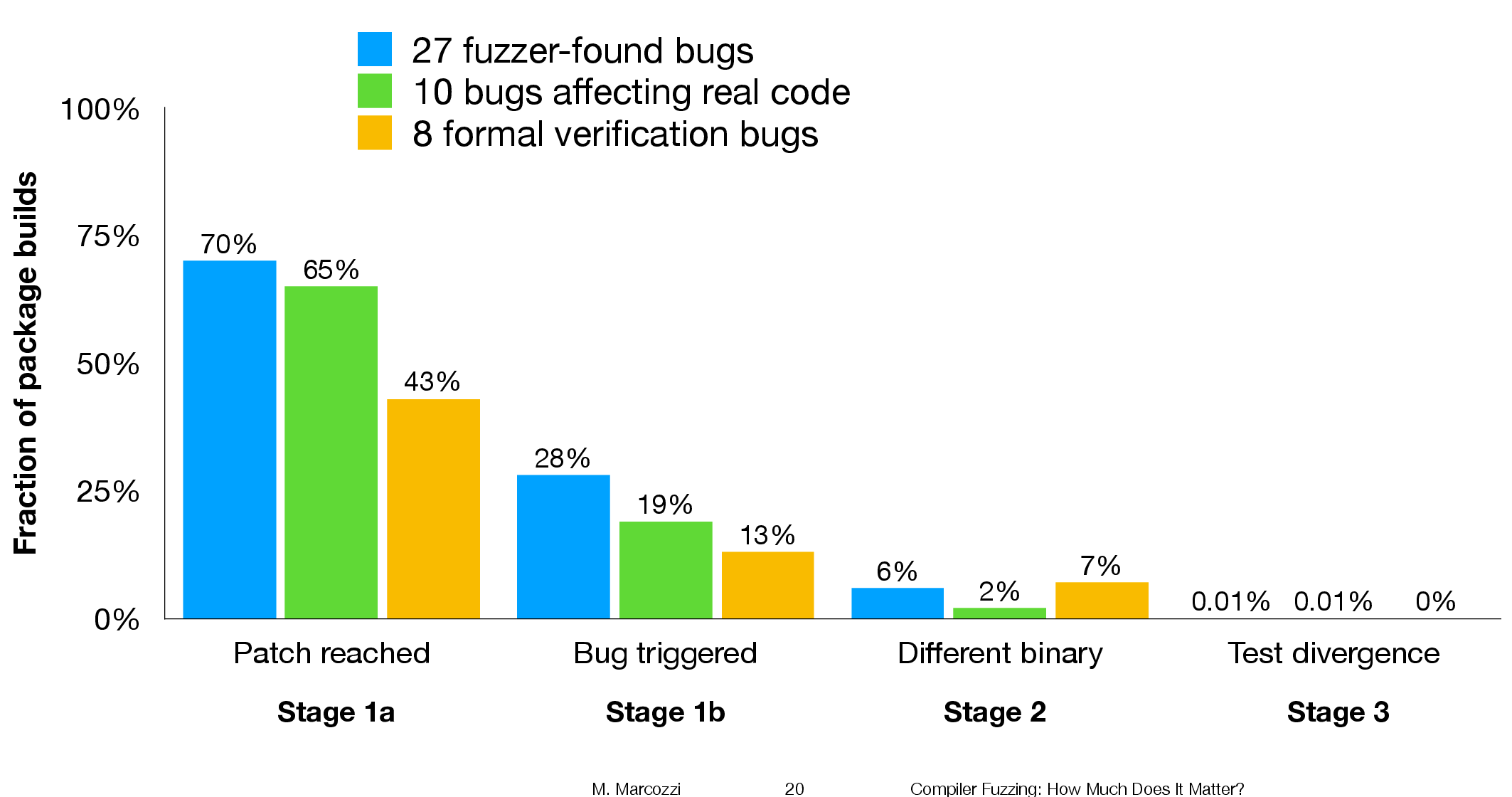
The takeaway from the above figure is that many packages are affected by the coding mistakes that have been fixed, but that most package test suites are not affected by the miscompilations.
To find out whether there is a difference, in terms of impact on Debian packages, between faults reported in human and automatically generated code, we need to compare the number of occurrences of “Fault possibly triggered”. The table below shows the break-down by the detector of the coding mistake (i.e., Human and each of the automated tools used), and the number of fixed faults they contributed to the analysis.
Human, Csmith and EMI each contributed 10-faults to the analysis. The fixes for the 10-fault reports in human generated code were triggered 593 times when building the 309 Debian packages, while each of the 10 Csmith and EMI fixes were triggered 1,043 and 948 times respectively; a lot more than the Human triggers :-O. There are also a lot more bitwise compare differences for the non-Human fault-fixes.
Detector Faults Reached Triggered Bitwise-diff Tests failed Human 10 1,990 593 56 1 Csmith 10 2,482 1,043 318 0 EMI 10 2,424 948 151 1 Orange 5 293 35 8 0 yarpgen 2 608 257 0 0 Alive 8 1,059 327 172 0 |
Is the difference due to a few packages being very different from the rest?
The table below breaks things down by each of the 10-reported faults from the three Detectors.
Ok, two Human fault-fix locations are never reached when compiling the Debian packages (which is a bit odd), but when the locations are reached they are just not triggering the fault conditions as often as the automatic cases.
Detector Reached Triggered
Human
300 278
301 0
305 0
0 0
0 0
133 44
286 231
229 0
259 40
77 0
Csmith
306 2
301 118
297 291
284 1
143 6
291 286
125 125
245 3
285 16
205 205
EMI
130 0
307 221
302 195
281 32
175 5
122 0
300 295
297 215
306 191
287 10 |
It looks like I am not only wrong, but that fault experiences from automatically generated source are more (not less) likely to occur in human written code (than fault experiences produced by human written code).
This is odd. At best, I would expect fault experiences from human and automatically generated code to have the same characteristics.
Ideas and suggestions welcome.
Update: the morning after
I have untangled my thoughts on how to statistically compare the three sets of data.
The bootstrap is based on the idea of exchangeability; which items being measured might we consider to be exchangeable, i.e., being able to treat the measurement of one as being the equivalent to measuring the other.
In this experiment, the coding mistakes are not exchangeable, i.e., different mistakes can have different outcomes.
But we might claim that the detection of mistakes is exchangeable; that is, a coding mistake is just as likely to be detected by source code produced by an automatic tool as source written by a Human.
The bootstrap needs to be applied without replacement, i.e., each coding mistake is treated as being unique. The results show that for the sum of the Triggered counts (code+data):
- treating Human and Csmith as being equally likely to detect the same coding mistake, there is a 18% change of the Human results being lower than 593.
- treating Human and EMI as being equally likely to detect the same coding mistake, there is a 12% change of the Human results being lower than 593.
So the likelihood of the lower value, 593, of Human Triggered events is expected to occur quite often (i.e., 12% and 18%). Automatically generated code is not more likely to detect coding mistakes than human written code (at least based on this small sample set).
Distorting the input profile, to stress test a program
A fault is experienced in software when there is a mistake in the code, and a program is fed the input values needed for this mistake to generate faulty behavior.
There is suggestive evidence that the distribution of coding mistakes and inputs generating fault experiences both have an influence of fault discovery.
How might these coding mistakes be found?
Testing is one technique, it involves feeding inputs into a program and checking the resulting behavior. What are ‘good’ input values, i.e., values most likely to discover problems? There is no shortage of advice for manually writing tests, suggesting how to select input values, but automatic generation of inputs is often somewhat random (relying on quantity over quality).
Probabilistic grammar driven test generators are trivial to implement. The hard part is tuning the rules and the probability of them being applied.
In most situations an important design aim, when creating a grammar, is to have one rule for each construct, e.g., all arithmetic, logical and boolean expressions are handled by a single expression rule. When generating tests, it does not always make sense to follow this rule; for instance, logical and boolean expressions are much more common in conditional expressions (e.g., controlling an if-statement), than other contexts (e.g., assignment). If the intent is to mimic typical user input values, then the probability of generating a particular kind of binary operator needs to be context dependent; this might be done by having context dependent rules or by switching the selection probabilities by context.
Given a grammar for a program’s input (e.g., the language grammar used by a compiler), decisions have to be made about the probability of each rule triggering. One way of obtaining realistic values is to parse existing input, counting the number of times each rule triggers. Manually instrumenting a grammar to do this is a tedious process, but tool support is now available.
Once a grammar has been instrumented with probabilities, it can be used to generate tests.
Probabilities based on existing input will have the characteristics of that input. A recent paper on this topic (which prompted this post) suggests inverting rule probabilities, so that common becomes rare and vice versa; the idea is that this will maximise the likelihood of a fault being experienced (the assumption is that rarely occurring input will exercise rarely executed code, and such code is more likely to contain mistakes than frequently executed code).
I would go along with the assumption about rarely executed code having a greater probability of containing a mistake, but I don’t think this is the best test generation strategy.
Companies are only interested in fixing the coding mistakes that are likely to result of a fault being experienced by a customer. It is a waste of resources to fix a mistake that will never result in a fault experienced by a customer.
What input is likely to interact with coding mistakes to be the root cause of faults experienced by a customer? I have no good answer to this question. But, given there are customer input contains patterns (at least in the world of source code, and I’m told in other application domains), I would generate test cases that are very similar to existing input, but with one sub-characteristic changed.
In the academic world the incentive is to publish papers reporting loads-of-faults-found, the more the merrier. Papers reporting only a few faults are obviously using inferior techniques. I understand this incentive, but fixing problems costs money and companies want a customer oriented rationale before they will invest in fixing problems before they are reported.
The availability of tools that automate the profiling of a program’s existing input, followed by the generation of input having slightly, or very, different characteristics make it easier to answer some very tough questions about program behavior.
Human vs automatically generated source code: an arms race?
How well do I understand the process of writing source, as performed by human developers? If I could write a program that could generate source code that was indistinguishable from human written code, then I think I could claim to have a decent understanding of the human processes.
An important question is the skill of the entity attempting to distinguish automatically generated and human written code. As of today I think I could fool existing tools (mostly because such tools don’t really exist; n-gram analysis is really all there is), but a human developer with a smattering of coding experience would not be fooled.
I think I know enough to write a tool that could generate single function definitions that would fool most developers, but not a moderately sophisticated analysis tool (I don’t know enough to combine multiple functions into a plausible call graph).
At the CREST workshop today I met Martin Monperrus who shared my view that the only way to prove an understanding of source is to be able to generate it; other people at the workshop seemed more interested in the detection side of things.
Perhaps the time is ripe to kick off a generator/detector arms race would certainly increase our knowledge of the characteristics of human written code.
What counts as automatically generated code? Printing complete function definitions mined from Github is obviously not what most people would associate with the concept of automatic source generation. What about printing statements mined from Github (with each statement coming from a different function definition)? Well, if people could make that work, then good luck to them (it hardly seems worth the bother because most statements are very simple and easily generated on a token by token basis).
Should functions be judged in isolation, or should a detector get to see multiple instances of each case (which would make the detector’s life easier)? It might be best to go with whatever rules make for an interesting arms race.
To start the ball rolling, here is my first entry to the generator side of the race (a rather minimal entry, but still the leader in its field; the recurrent neural network trained on the Linux source would easily beat it, but my interest is in understanding developer behavior and will leave it to others to go down the neural network path).
Testing compiler semantics with minimal manual input
The 2011 revision of the C++ Standard added lots of new constructs to the language and in the past few months both the GCC and LLVM teams have been claiming that the next release of their C++ compilers will fully support the 2011 Standard. How true are these claims? One way of answering this question is to run both compilers over an extensive test suite. There are commercial C++ compiler test suites available, but I don’t have access to them and if I did the license agreement would probably not allow me to talk in detail about the results. Writing compiler tests cases requires a very detailed knowledge of the language; I have done it often enough in previous lives to know that more than a year or so of my time would be needed just to get my head around the semantics of the new C++ features, before I could produce anything half decent.
Is there a way of automating the generation of test cases for language semantics? Automated statement/expression generation is very effective at finding problems with optimizers and code generators. Can this technique be applied to check the semantic requirements of a language?
Having concocted various elaborate schemes over the years I recently realised that life would be a lot simpler if I was willing to accept a very high percentage of erroneous test programs (the better manually written test suites usually contain around as many test cases that intended to fail to compile as tests that pass, i.e., intended to compile correctly; the not so good ones have few failing tests).
If two or more compilers are available the behavior of each of them on a given source file can be compared: differential testing. If both compile a file or fail to compile it, they may both be right or wrong; either way this shared behavior is not interesting, but is likely to be the common case. The interesting case is if one compiles a file and the other fails to compile it; this could be a fault in one of them, or one of those cases where the Standard permits compilers to do their own thing.
I hereby jump to the conclusion that behavior differences is a good proxy for compiler conformance to the language Standard (actually developers are often more interested in all compilers they are likely to use having the same external behavior than conforming to a Standard).
Lets implement this (source code here)!
First we need to generate lots of test cases. The process I used is based on program templates, such as the following (lines starting with ! are places where various constructs can be inserted):
int v; ! declare_id 2 int main(void) { ! declare_id 2 ! ref_id 2 } |
the identifier after the ! is the name of a file containing lines to be inserted at the given location (the number after the identifier is the maximum number of lines that can be inserted at that point; default 1 if no number given). The following is example file contents for the above template:
declare_id
int i; enum {i, j}; enum i {x, y}; struct i {int f;}; typedef int i; |
ref_id
enum i ev_i; struct i sv_i; typedef i tv_i; v=i; |
It is then simply a matter of permuting through all of the possible combinations of lines that can be inserted in the program template, creating a stand alone file for each possibility (18,000 of them in the above example); I used the Python Natural Language Toolkit to do the heavy lifting.
A shell script compiles each source file and compares the compiler exit codes. For the above example there were 16,366 failures, 1,634 passes and no differences (this example contains well established C constructs and any difference would have been surprising).
Next, a feature new in C++11, lambda functions!
Here is the template used:
! declare_xy 2 int main(void) { ! declare_xy 2 auto foo_bar = ! define_lambda ; return 0; } |
I cut and pasted some examples from the Standard to create the following optional lines:
define_lambda
[](float a, float b) { return a + b; } [=](float a, float b) { return a + b; } [=,x](float a, float b) { return a + b; } [y](float a, float b) { return a + b; } [=]()->int { return operator()(this->x + y); } [&, i]{ } [=] { decltype(x) y1; decltype((x)) y2 = y1; decltype(y) r1 = y1; decltype((y)) r2 = y2; } |
which generated 6,300 source files of which 5,865 failed, 396 passed and 39 were treated differently by the compilers (g++ version 4.7.2, clang version 3.3).
How should the percentages be calculated? If we take the human written numbers for well written test suites containing (roughly) equal numbers of pass/fail tests, then we have around 800 tests of which (say) 40 gave different behavior, giving us a 5% fault rate. Do we share that 5% equally between both compilers or assign 3% for both being wrong and 1% for each being uniquely wrong?
Submitting a bug report to both compiler teams pointing out that their behavior is different from the other’s is a sure fire way to make myself unpopular. Any suggestions for how to resolve this issue, that does not involve me having to study the tiresomely long and convoluted C++ Standard, welcome.
Generating code that looks like it is human written
I am very interested in understanding the patterns of developer behavior that lead to the human characteristics that can be found in code. To help me get some idea of how well I understand this behavior I have decided to build a tool that generates source code that appears to be written by human programmers. I hope to reach a point where I can offer a challenge to tell the difference between generated code and human written code.
The three main production techniques I plan to use are, in increasing order of relatedness to humans production techniques, are:
- Random generation based on percentage occurrence of language constructs obtained from measurements of existing source. This is the simplest approach and the one furthest away from common developer behavior; even so there are things that can be learned from this information. For instance, the theory that developers are more likely to create a function once code becomes heavily nested code implies that the probability of encountering an if-statement decreases as nesting depth increases; measurements show the probability of encountering an if-statement remaining approximately constant as depth of nesting increases.
- Behavior templates. People have habits in everyday life and also when writing software. While some habits are idiosyncratic and not encountered very often there are some that appear to be generally used. For instance, developers tend to assign a fixed role to every variable they define (e.g., stepper for stepping through a succession of values and most-recent holder holding the latest value encountered in going through a succession of values).
I am expecting/hoping that generation by behavioral templates will result in code having some of the probabilistic properties seen in human code, removing the need for purely random generation driven by low level language probability measurements. For instance, the probability of a local variable appearing in a function is proportional to the percentage of its previous occurrences up to that point in the source of the function (
percentage = occurrences_of_X / occurrences_of_all_local_variables) and I am hoping that this property appears as emergent behavior from generating using the role of variable template. - Story telling. A program is like the plot of a story, it has a cast of characters (e.g., classes, functions, libraries) that perform various actions and interact with each other in order to achieve various goals, there are subplots (intermediate results are calculated, devices are initialized, etc), there are resource limits, etc.
While a lot of stories are application domain specific there are subplots common to many stories; also how a story is told can be heavily influenced by the language used, for instance Prolog programs have a completely different structure than those written in procedural languages such as Java. I want to stay away from being application specific and I don’t plan to tackle languages too far outside the common-or-garden procedural variety.
Researchers have created automatic story generators; the early generators were template based while more recent systems have used an agent based approach. Story based generation of code is my ideal, but I am a long way away from having enough knowledge of developer behavior to be more than template based.
In a previous post I described a system for automatically generating very simply C programs. I plan to build on this system to incrementally improve the ‘humanness’ of the generated code. At some point, hopefully before the end of this year, I will challenge people to tell the difference between automatically generated and human written code.
The language I have studied the most is C and this will be the main target. I don’t want to be overly C specific and am trying to decide on a good second language (i.e., lots of source available for measurement, used by lots of developers and not too different from C). JavaScript is the current front runner, it is a class-less object oriented language which is not ‘wildly’ OO (the patterns of usage in human written OO code continue to evolve at a rapid rate which can make a lot of human C++/Java code look automatically generated).
As well as being a test bed for understanding of human generated code other uses for an automatic generator include compiler stress testing and providing code snippets to an automated fault fixing tool.
Recent Comments