Archive
Algorithm complexity and implementation LOC
As computer functionality increases, it becomes easier to write programs to handle more complicated problems which require more computing resources; also, the low-hanging fruit has been picked and researchers need to move on. In some cases, the complexity of existing problems continues to increase.
The Linux kernel is an example of a solution to a problem that continues to increase in complexity, as measured by the number of lines of code.
The distribution of problem complexities will vary across application domains. Treating program size as a proxy for problem complexity is more believable when applied to one narrow application domain.
Since 1960, the journal Transactions on Mathematical Software has been making available the source code of implementations of the algorithms provided with the papers it publishes (before the early 1970s they were known as the Collected Algorithms of the ACM, and included more general algorithms). The plot below shows the number of lines of code in the source of the 893 published implementations over time, with fitted regression lines, in black, of the form  before 1994-1-1, and
before 1994-1-1, and  after that date (black dashed line is a LOESS regression model; code+data).
after that date (black dashed line is a LOESS regression model; code+data).
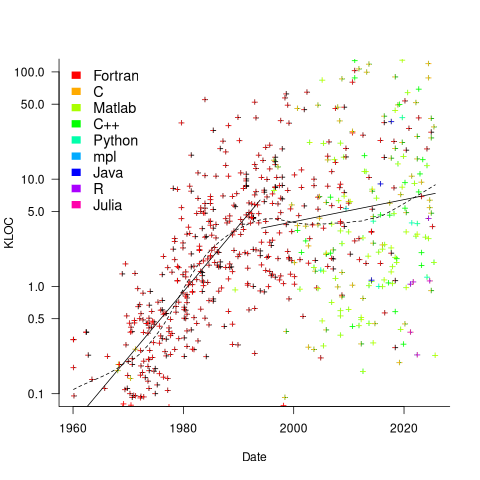
The two immediately obvious patterns are the sharp drop in the average rate of growth since the early 1990s (from 15% per year to 2% per year), and the dominance of Fortran until the early 2000s.
The growth in average implementation LOC might be caused by algorithms becoming more complicated, or because increasing computing resources meant that more code could be produced with the same amount of researcher effort, or another reason, or some combination. After around 2000, there is a significant increase in the variance in the size of implementations. I’m assuming that this is because some researchers focus on niche algorithms, while others continue to work on complicated algorithms.
An aim of Halstead’s early metric work was to create a measure of algorithm complexity.
If LLMs really do make researchers more productive, then in future years LOC growth rate should increase as more complicated problems are studied, or perhaps because LLMs generate more verbose code.
The table below shows the primary implementation language of the algorithm implementations:
Language Implementations
Fortran 465
C 79
Matlab 72
C++ 24
Python 7
R 4
Java 3
Julia 2
MPL 1 |
If algorithms are becoming more complicated, then the papers describing/analysing them are likely to contain more pages. The plot below shows the number of pages in the published papers over time, with fitted regression line of the form  (0.38 pages per year; red dashed line is a LOESS regression model; code+data).
(0.38 pages per year; red dashed line is a LOESS regression model; code+data).
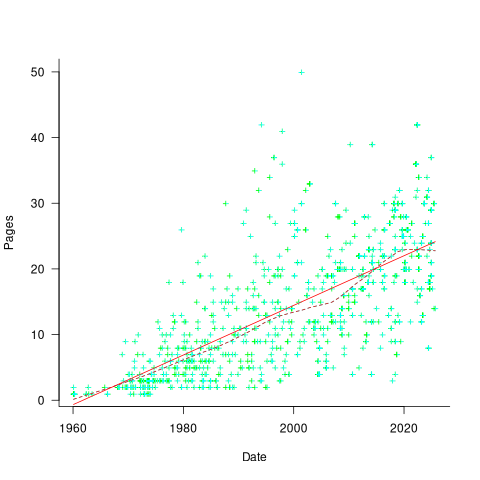
Unlike the growth of implementation LOC, there is no break-point in the linear growth of page count. Yes, page count is influence by factors such as long papers being less likely to be accepted, and being able to omit details by citing prior research.
It would be a waste of time to suggest more patterns of behavior without looking at a larger sample papers and their implementations (I have only looked at a handful).
When the source was distributed in several formats, the original one was used. Some algorithms came with build systems that included tests, examples and tutorials. The contents of the directories: CALGO_CD, drivers, demo, tutorial, bench, test, examples, doc were not counted.
Benchmarking string search algorithms
Searching a sequence of items for occurrences of a specific pattern is a common operation, and researchers are still discovering faster string search algorithms.
While skimming the paper Efficient Exact Online String Matching Through Linked Weak Factors by M. N. Palmer, S. Faro, and S. Scafiti, Tables 1, 2 and 3 jumped out at me. The authors put a lot of effort into benchmarking the performance of 21 search algorithms representing a selection of go-faster techniques (they wanted to show that their new algorithm, using hash chains, was the fastest; Grok explains the paper). I emailed the authors for the data, and Matt Palmer kindly added it to the HashChain Github repo. Matt was also generous with his time answering my questions.
The benchmark search involved three sequences of items, each of 100MB, a genome sequence, a protein sequence and English text. The following analysis if based on results from searching the English text. The search process returned the number of occurrences of the pattern in the character sequence.
The patterns to search for were randomly extracted from the sequence being searched. Eleven pattern lengths were used, ranging from 4 to 4,096 items in powers of 2 (the tables in the paper list lengths in the range 8 to 512). There were 500 runs for each length, with a different pattern used each time, i.e., a total of 5,500 patterns. Every search algorithm matched the same 5,500 patterns.
Some algorithms have tuneable parameters (e.g., the number of characters hashed), and 107 variants of the 21 algorithms were run, giving a total of 555,067 timing measurements (a 200ms time limit sometimes prevented a run completing).
To understand some of the patterns present in the timing results, it’s necessary to know something about how industrial strength string search algorithms work. The search pattern is first processed to create either a finite state machine or some other data structure. The matching process starts at the right of the pattern and moves left, comparing items. This approach makes it possible to skip over sequences of text that cannot match. For instance, if the current text character is X, this is fed into the finite state machine created from the pattern, and if X is not in the pattern, the matching process can move forward by the length of the pattern (if the pattern contains an X, the matching process skips forward the appropriate number of characters). This pattern shift technique was first implemented in the Boyer-Moore algorithm in 1977.
One consequence of skipping over sequences that cannot match, is that longer pattern enable longer skips, resulting in faster searches. The following plot shows the search time against pattern length for two algorithms; total time includes preprocessing the pattern and searching the text (red plus symbols have been offset by 10% to show both timings; code+data):
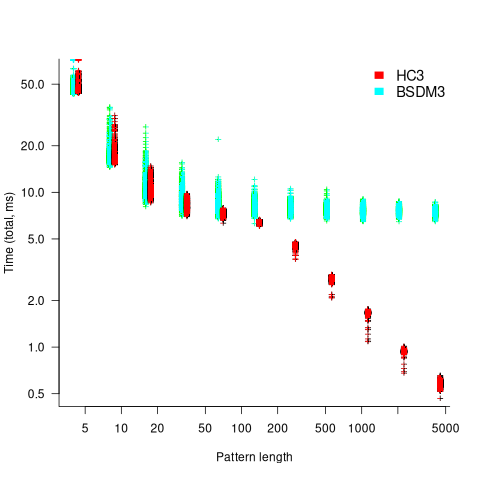
Why does the search time for HC3 (one variant of the author’s new algorithm) start to plateau and then start decreasing again? One possible cause of this saddle point is the cpu cache line width, which is 64 bytes on the system that ran the benchmarks. When the skip length is at least twice the cache line width, it is not necessary to read characters that would cause the filling of at least one cache line. As always, further research is needed.
What is the most informative method for comparing the algorithm/tool performance?
The most commonly used method is to compare mean performance times, and this is what the authors do for each pattern length. A related alternative, given that different patterns are used for each run, is to compare median times, on the basis that users are interested in the fastest algorithm across many patterns. When variance in the search times is taken into account, there is no clear winner across all pattern lengths (the uncertainty in the mean value is sometimes larger than the difference in performance).
Comparing performance across pattern lengths is interesting for algorithm designers, but users want a single performance value. The traditional approach to building a single model, that would include pattern length and algorithm, is to fit a regression model. However, this approach requires that the change in performance with pattern length roughly have the same form across all algorithms. The plot above clearly shows two algorithms with different forms of change of timing behavior with pattern length (other algorithms exhibit different behaviors).
A completely different modelling approach is to treat each pattern search as a competition between algorithms, with algorithms ranked by search time (fastest first). In this approach, the relative performance of each algorithm is ranked; there are 500 ranks for each pattern length. The fitted model can be used to calculate the probability, over all patterns, that algorithm A1 will be faster than algorithm A2.
Readers might be familiar with the Bradley-Terry model, where two items are ranked, e.g., the results from football games played between pairs of teams during a season. When more than two items are ranked, a Plackett-Luce model can be fitted. The output from fitting these models is a value,  , for each of the algorithms, e.g.,
, for each of the algorithms, e.g.,  . The probability that algorithm
. The probability that algorithm A1 will rank higher than Algorithm A2 is calculated from the expression:
 , this expression can also be written as:
, this expression can also be written as: 
Switch A1 and A2 to calculate the opposite ranking.
The probability that algorithm A1 ranks higher than Algorithm A2 which in turn ranks higher than Algorithm A3 is calculated as follows (and so on for more algorithms):

For ease of comparison, only the 53 algorithms with 500 sets of timing data for all pattern lengths was fitted. The following plot shows the fitted values for each algorithm (blue/green lines are standard errors, and names containing HC are some variant of the authors’ hash chain technique; code+data):
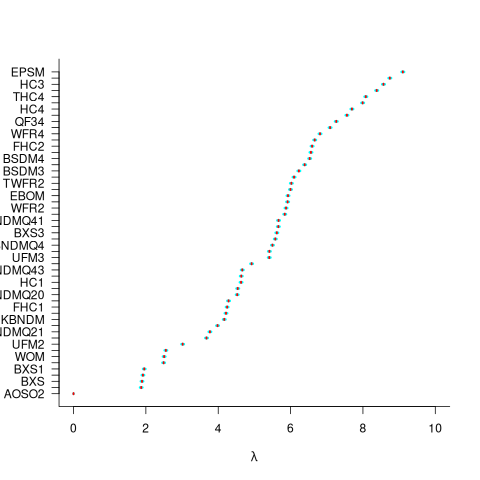
The EPSM algorithm makes use of the SSE and AVX instructions, supported by modern x86 processors, that can operate on up to 512 bits at a time.
The following table lists the fitted lambda values for the top eight ranked algorithm implementation:
Algorithm Lambda
EPSM 9.103007
THC3 8.743377
HC3 8.567715
FHC3 8.381220
THC4 8.079716
FHC4 7.991929
HC4 7.695787
TWFR4 7.557796 |
The likelihood that EPSM will rank higher than THC3 is } right 0.59") .
.
This is better than random, and reflects the variability in algorithm performance, i.e., there is no clear winner.
It might be possible to extract more information from the data.
Some algorithms use of the same technique for part of their search process. Information on the techniques shared by algorithms can be added to the model as covariates. Assuming that a suitable fit is obtained, the model coefficients would indicate the relative impact of each technique on performance. I don’t know enough to select the techniques, and Matt is thinking about it.
My 2024 in software engineering
Readers are unlikely to have noticed something that has not been happening during the last few years. The plot below shows, by year of publication, the number of papers cited (green) and datasets used (red) in my 2020 book Evidence-Based Software Engineering. The fitted red regression lines suggest that the 20s were going to be a period of abundant software engineering data; this has not (yet?) happened (the blue line is a local regression fit, i.e., loess). In 2020 COVID struck, and towards the end of 2022 Large Language Models appeared and sucked up all the attention in the software research ecosystem, and there is lots of funding; data gathering now looks worse than boring (code+data):
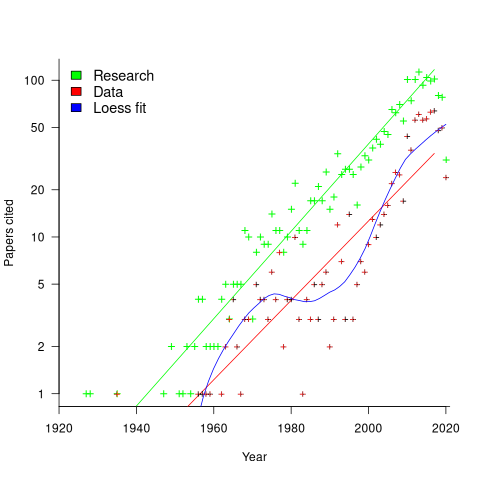
LLMs are showing great potential as research tools, but researchers are still playing with them in the sandpit.
How many AI startups are there in London? I thought maybe one/two hundred. A recruiter specializing in AI staffing told me that he would estimate around four hundred; this was around the middle of the year.
What did I learn/discover about software engineering this year?
Regular readers may have noticed a more than usual number of posts discussing papers/reports from the 1960s, 1970s and early 1980s. There is a night and day difference between software engineering papers from this start-up period and post mid-1980s papers. The start-up period papers address industry problems using sophisticated mathematical techniques, while post mid-1980s papers pay lip service to industrial interests, decorating papers with marketing speak, such as maintainability, readability, etc. Mathematical orgasms via the study of algorithms could be said to be the focus of post mid-1980s researchers. So-called software engineering departments ought to be renamed as Algorithms department.
Greg Wilson thinks that the shift happened in the 1980s because this was the decade during which the first generation of ‘trained in software’ people (i.e., emphasis on mathematics and abstract ideas) became influential academics. Prior generations had received a practical training in physics/engineering, and been taught the skills and problem-solving skills that those disciplines had refined over centuries.
My research is a continuation of the search for answers to the same industrial problems addressed by the start-up researchers.
In the second half of the year I discovered the mathematical abilities of LLMs, and started using them to work through the equations for various models I had in mind. Sometimes the final model turned out to be trivial, but at least going through the process cleared away the complications in my mind. According to reports, OpenAI’s next, as yet unreleased, model has super-power maths abilities. It will still need a human to specify the equations to solve, so I am not expecting to have nothing to blog about.
Analysis/data in the following blog posts, from the last 12-months, belongs in my book Evidence-Based Software Engineering, in some form or other:
Small business programs: A dataset in the research void
Putnam’s software equation debunked (the book is non-committal).
if statement conditions, some basic measurements
Number of statement sequences possible using N if-statements; perhaps.
A new NASA software dataset from the 1970s
A surprising retrospective task estimation dataset
Average lines added/deleted by commits across languages
Census of general purpose computers installed in the 1960s
Some information on story point estimates for 16 projects
Agile and Waterfall as community norms
Median system cpu clock frequency over last 15 years
The evidence-based software engineering Discord channel continues to tick over (invitation), with sporadic interesting exchanges.
Algorithms are now commodities
When I first started writing software, developers had to implement most of the algorithms they used; yes, hardware vendors provided libraries, but the culture was one of self-reliance (except for maths functions, which were technical and complicated).
Developers read Donald Knuth’s The Art of Computer Programming, it was the reliable source for step-by-step algorithms. I vividly remember seeing a library copy of one volume, where somebody had carefully hand-written, in very tiny letters, an update to one algorithm, and glued it to the page over the previous text.
Algorithms were important because computers were not yet fast enough to solve common problems at an acceptable rate; developers knew the time taken to execute common instructions and instruction timings were a topic of social chit-chat amongst developers (along with the number of registers available on a given cpu). Memory capacity was often measured in kilobytes, every byte counted.
This was the age of the algorithm.
Open source commoditized algorithms, and computers got a lot faster with memory measured in megabytes and then gigabytes.
When it comes to algorithm implementation, developers are now spoilt for choice; why waste time implementing the ‘low’ level stuff when there were plenty of other problems waiting to be implemented.
Algorithms are now like the bolts in a bridge: very important, but nobody talks about them. Today developers talk about story points, features, business logic, etc. Given a well-defined problem, many are now likely to search for an existing package, rather than write code from scratch (I certainly work this way).
New algorithms are still being invented, and researchers continue to look for improvements to existing algorithms. This is a niche activity.
There are companies where algorithms are not commodities. Google operates on a scale where what appears to others as small improvements, can save the company millions (purely because a small percentage of a huge amount can be a lot). Some company’s core competency may include an algorithmic component (whose non-commodity nature gives the company its edge over the competition), with the non-core competency treating algorithms as a commodity.
Knuth’s The Art of Computer Programming played an important role in making viable algorithms generally available; while the volumes are frequently cited, I suspect they are rarely read (I have not taken any of my three volumes off the shelf, to read, for years).
A few years ago, I suddenly realised that I was working on a book about software engineering that not only did not contain an algorithms chapter, and the 103 uses of the word algorithm all refer to it as a concept.
Today, we are in the age of the ecosystem.
Algorithms have not yet completed their journey to obscurity, which has to wait until people can tell computers what they want and not be concerned about the implementation details (or genetic algorithm programming gets a lot better).
The Algorithmic Accountability Act of 2019
The Algorithmic Accountability Act of 2019 has been introduced to the US congress for consideration.
The Act applies to “person, partnership, or corporation” with “greater than $50,000,000 … annual gross receipts”, or “possesses or controls personal information on more than— 1,000,000 consumers; or 1,000,000 consumer devices;”.
What does this Act have to say?
(1) AUTOMATED DECISION SYSTEM.—The term ‘‘automated decision system’’ means a computational process, including one derived from machine learning, statistics, or other data processing or artificial intelligence techniques, that makes a decision or facilitates human decision making, that impacts consumers.
That is all encompassing.
The following is what the Act is really all about, i.e., impact assessment.
(2) AUTOMATED DECISION SYSTEM IMPACT ASSESSMENT.—The term ‘‘automated decision system impact assessment’’ means a study evaluating an automated decision system and the automated decision system’s development process, including the design and training data of the automated decision system, for impacts on accuracy, fairness, bias, discrimination, privacy, and security that includes, at a minimum—
I think there is a typo in the following: “training, data” -> “training data”
(A) a detailed description of the automated decision system, its design, its training, data, and its purpose;
How many words are there in a “detailed description of the automated decision system”, and I’m guessing the wording has to be something a consumer might be expected to understand. It would take a book to describe most systems, but I suspect that a page or two is what the Act’s proposers have in mind.
(B) an assessment of the relative benefits and costs of the automated decision system in light of its purpose, taking into account relevant factors, including—
Whose “benefits and costs”? Is the Act requiring that companies do a cost benefit analysis of their own projects? What are the benefits to the customer, compared to a company not using such a computerized approach? The main one I can think of is that the customer gets offered a service that would probably be too expensive to offer if the analysis was done manually.
The potential costs to the customer are listed next:
(i) data minimization practices;
(ii) the duration for which personal information and the results of the automated decision system are stored;
(iii) what information about the automated decision system is available to consumers;
This act seems to be more about issues around data retention, privacy, and customers having the right to find out what data companies have about them
(iv) the extent to which consumers have access to the results of the automated decision system and may correct or object to its results; and
(v) the recipients of the results of the automated decision system;
What might the results be? Yes/No, on a load/job application decision, product recommendations are a few.
Some more potential costs to the customer:
(C) an assessment of the risks posed by the automated decision system to the privacy or security of personal information of consumers and the risks that the automated decision system may result in or contribute to inaccurate, unfair, biased, or discriminatory decisions impacting consumers; and
What is an “unfair” or “biased” decision? Machine learning finds patterns in data; when is a pattern in data considered to be unfair or biased?
In the UK, the sex discrimination act has resulted in car insurance companies not being able to offer women cheaper insurance than men (because women have less costly accidents). So the application form does not contain a gender question. But the applicants first name often provides a big clue, as to their gender. So a similar Act in the UK would require that computer-based insurance quote generation systems did not make use of information on the applicant’s first name. There is other, less reliable, information that could be used to estimate gender, e.g., height, plays sport, etc.
Lots of very hard questions to be answered here.
The age of the Algorithm is long gone
I date the age of the Algorithm from roughly the 1960s to the late 1980s.
During the age of the Algorithms, developers spent a lot of time figuring out the best algorithm to use and writing code to implement algorithms.
Knuth’s The Art of Computer Programming (TAOCP) was the book that everybody consulted to find an algorithm to solve their current problem (wafer thin paper, containing tiny handwritten corrections and updates, was glued into the library copies of TAOCP held by my undergraduate university; updates to Knuth was news).
Two developments caused the decline of the age of the Algorithm (and the rise of the age of the Ecosystem and the age of the Platform; topics for future posts).
- The rise of Open Source (it was not called this for a while), meant it became less and less necessary to spend lots of time dealing with algorithms; an implementation of something that was good enough, was available. TAOCP is something that developers suggest other people read, while they search for a package that does something close enough to what they want.
- Software systems kept getting larger, driving down the percentage of time developers spent working on algorithms (the bulk of the code in commercially viable systems deals with error handling and the user interface). Algorithms are still essential (like the bolts holding a bridge together), but don’t take up a lot of developer time.
Algorithms are still being invented, and some developers spend most of their time working with algorithms, but peak Algorithm is long gone.
Perhaps academic researchers in software engineering would do more relevant work if they did not spend so much time studying algorithms. But, as several researchers have told me, algorithms is what people in their own and other departments think computing related research is all about. They remain shackled to the past.
Teach children planning and problem solving not programming
When I first heard that children in secondary education (11-16 year olds) here in the UK were to be taught programming I thought it was another example of a poorly thought through fad ruining our education system. Schools already have enough trouble finding goos maths and science teachers, and the average school leavers knowledge of these subjects is not that great, now resources and time are being diverted to a specialist subject for which it is hard to find good teachers. After talking to a teacher about his experience teaching Scratch to 11-13 year olds I realised he was not teaching programming but teaching how to think through problems, breaking them down into subcomponents and cover all possibilities; a very worthwhile subject to teach.
As I see it the ‘writing code’ subject needs to be positioned as the teaching of planning and problem solving skills (ppss, p2s2, a suitable acronym is needed) rather than programming. Based on a few short conversations with those involved in teaching, the following are a few points I would make:
- Stay with one language (Scratch looks excellent).
- The more practice students get with a language the more fluent they become, giving them more time to spend solving the problem rather than figuring out how to use the language.
- Switching to a more ‘serious’ language because it is similar to what professional programmers use is a failure to understand the purpose of what is being taught and a misunderstanding of why professionals still use ‘text’ based languages (because computer input has historically been via a keyboard and not a touch sensitive screen; I expect professional programmers will slowly migrate over to touch screen programming languages).
- Give students large problems to solve (large as in requiring lots of code). Small programs are easy to hold in your head, where the size of small depends on intellectual capacity; the small program level of coding is all about logic. Large programs cannot be held in the head and this level of coding is all about structure and narrative (there are people who can hold very large programs in their head and never learn the importance of breaking things down so others can understand them), logic does not really appear at this level. Large problems can be revisited six months later; there is no better way of teaching the importance of making things easy for others to understand than getting a student to modify one of their own programs a long time after they originally wrote it (I’m sure many will start out denying ever having written the horrible code handed back to them).
- Problems should not be algorithms. Yes, technically all programs are algorithms but most are not mathematical algorithms in the sense that, say, sorting and searching are, real life problems are messy things that involve lots of simple checks for various conditions and ad-hoc approaches to solving a problem. Teachers should resist mapping computing problems to the Scratch domain, e.g., tree walking algorithms mapped to walking the branches of a graphical tree or visiting all parts of a maze.
Automatically improving code
Compared to 20 or 30 years ago we know a lot more about the properties of algorithms and better ways of doing things often exist (e.g., more accurate, faster, more reliable, etc). The problem with this knowledge is that it takes the form of lots and lots of small specific details, not the kind of thing that developers are likely to be interested in, or good at, remembering. Rather than involve developers in the decision-making process, perhaps the compiler could figure out when to substitute something better for what had actually been written.
While developers are likely to be very happy to see what they have written behaving as accurately and reliably as they had expected (ignorance is bliss), there is always the possibility that the ‘less better’ behavior of what they had actually written had really been intended. The following examples illustrate two relatively low level ‘improvement’ transformations:
- this case is probably a long-standing fault in many binary search and merge sort functions; the relevant block of developer written code goes something like the following:
while (low <= high) { int mid = (low + high) / 2; int midVal = data[mid]; if (midVal < key) low = mid + 1 else if (midVal > key) high = mid - 1; else return mid; }
The fault is in the expression
(low + high) / 2which overflows to a negative value, and returns a negative value, if the number of items being sorted is large enough. Alternatives that don’t overflow, and that a compiler might transform the code to, include:low + ((high - low) / 2)and(low + high) >>> 1. - the second involves summing a sequence of floating-point numbers. The typical implementation is a simple loop such as the following:
sum=0.0; for i=1 to array_len sum += array_of_double[i];
which for large arrays can result in
sumlosing a great deal of accuracy. The Kahan summation algorithm tries to take account of accuracy lost in one iteration of the loop by compensating on the next iteration. If floating-point numbers were represented to infinite precision the following loop could be simplified to the one above:sum=0.0; c=0.0; for i = 1 to array_len { y = array_of_double[i] - c; // try to adjust for previous lost accuracy t = sum + y; c = (t - sum) - y; // try and gets some information on lost accuracy sum = t; }
In this case the additional accuracy is bought at the price of a decrease in performance.
Compiler maintainers are just like other workers in that they want to carry on working at what they are doing. This means they need to keep finding ways of improving their product, or at least improving it from the point of view of those willing to pay for their services.
Many low level transformations such as the above two examples would be not be that hard to implement, and some developers would regard them as useful. In some cases the behavior of the code as written would be required, and its transformed behavior would be surprising to the author, while in other cases the transformed behavior is what the developer would prefer if they were aware of it. Doesn’t it make sense to perform the transformations in those cases where the as-written behavior is least likely to be wanted?
Compilers already do things that are surprising to developers (often because the developer does not fully understand the language, many of which continue to grow in complexity). Creating the potential for more surprises is not that big a deal in the overall scheme of things.
Christmas books for 2009
I thought it would be useful to list the books that gripped me one way or another this year (and may be last year since I don’t usually track such things closely); perhaps they will give you some ideas to add to your Christmas present wish list (please make your own suggestions in the Comments). Most of the books were published a few years ago, I maintain piles of books ordered by when I plan to read them and books migrate between piles until eventually read. Looking at the list I don’t seem to have read many good books this year, perhaps I am spending too much time reading blogs.
These books contain plenty of facts backed up by numbers and an analytic approach and are ordered by physical size.
The New Science of Strong Materials by J. E. Gordon. Ideal for train journeys since it is a small book that can be read in small chunks and is not too taxing. Offers lots of insight into those properties of various materials that are needed to build things (‘new’ here means postwar).
Europe at War 1939-1945 by Norman Davies. A fascinating analysis of the war from a numbers perspective. It is hard to escape the conclusion that in the grand scheme of things us plucky Brits made a rather small contribution, although subsequent Hollywood output has suggested otherwise. Also a contender for a train book.
Japanese English language and culture contact by James Stanlaw. If you are into Japanese culture you will love this, otherwise avoid.
Evolutionary Dynamics by Martin A. Nowak. For the more mathematical folk and plenty of thought power needed. Some very powerful general results from simple processes.
Analytic Combinatorics by Philippe Flajolet and Robert Sedgewick. Probably the toughest mathematical book I have kept at (yet to get close to the end) in a few years. If number sequences fascinate you then give it a try (a pdf is available).
Probability and Computing by Michael Mitzenmacher and Eli Upfal. For the more mathematical folk and plenty of thought power needed. Don’t let the density of Theorems put you off, the approach is broad brush. Plenty of interesting results with applications to solving problems using algorithms containing a randomizing component.
Network Algorithmics by George Varghese. A real hackers book. Not so much a book about algorithms used to solve networking problems but a book about making engineering trade-offs and using every ounce of computing functionality to solve problems having severe resource and real-time constraints.
Virtual Machines by James E. Smith and Ravi Nair. Everything you every wanted to know about virtual machines and more.
Biological Psychology by James W. Kalat. This might be a coffee table book for scientists. Great illustrations, concise explanations, the nuts and bolts of how our bodies runs at the protein/DNA level.
Recent Comments