Archive
Finding reports and papers on the web
What is the best way to locate a freely downloadable copy of a report or paper on the web? The process I follow is outlined below (if you are new to this, you should first ask yourself whether reading a scientific paper will produce the result you are expecting):
- Google search. For the last 20 years, my experience is that Google search is the best place to look first.
Search on the title enclosed in double-quotes; if no exact matches are returned, the title you have may be slightly incorrect (variations in the typos of citations have been used to construct researcher cut-and-paste genealogies, i.e., authors copying a citation from a paper into their own work, rather than constructing one from scratch or even reading the paper being cited). Searching without quotes may return the desired result, or lots of unrelated matched. In the unrelated matches case, quote substrings within the title or include the first author’s surname.
The search may return a link to a ResearchGate page without a download link. There may be a “Request full-text” link. Clicking this sends a request email to one of the authors (assuming ResearchGate has an address), who will often respond with a copy of the paper.
A search may not return any matches, or links to copies that are freely available. Move to the next stage,
- Google Scholar. This is a fantastic resource. This site may link to a freely downloadable copy, even though a Google search does not. It may also return a match, even though a Google search does not. Most of the time, it is not necessary to include the title in quotes.
If the title matches a paper without displaying a link to a downloaded pdf, click on the match’s “Cited by” link (assuming it has one). The author may have published a later version that is available for download. If the citation count is high, tick the “Search within citing articles” box and try narrowing the search. For papers more than about five years old, you can try a “Customer range…” to remove more recent citations.
No luck? Move to the next stage,
- If a freely downloadable copy is available on the web, why doesn’t Google link to it?
A website may have a robots.txt requesting that the site not be indexed, or access to report/paper titles may be kept in a site database that Google does not access.
Searches now either need to be indirect (e.g., using Google to find an author web page, which may contain the sought after file), or targeted at specific cases.
It’s now all special cases. Things to try:
- Author’s website. Personal web pages are common for computing-related academics (much less common for non-computing, especially business oriented), but often a year or two out of date. Academic websites usually show up on a Google search. For new (i.e., less than a year), when you don’t need to supply a public link to the paper, email the authors asking for a copy. Most are very happy that somebody is interested in their work, and will email a copy.
When an academic leaves a University, their website is quickly removed (MIT is one of the few that don’t do this). If you find a link to a dead site, the Wayback Machine is the first place to check (try less recent dates first). Next, the academic may have moved to a new University, so you need to find it (and hope that the move is not so new that they have not yet created a webpage),
- Older reports and books. The Internet Archive is a great resource,
- Journals from the 1950s/1960s, or computer manuals. bitsavers.org is the first place to look,
- Reports and conference proceedings from before around 2000. It might be worth spending a few £/$ at a second hand book store; I use Amazon, AbeBooks, and Biblio. Despite AbeBooks being owned by Amazon, availability/pricing can vary between the two,
- A PhD thesis? If you know the awarding university, Google search on ‘university-name “phd thesis”‘ to locate the appropriate library page. This page will probably include a search function; these search boxes sometimes supporting ‘odd’ syntax, and you might have to search on: surname date, keywords, etc. Some universities have digitized thesis going back to before 1900, others back to 2000, and others to 2010.
The British Library has copies of thesis awarded by UK universities, and they have digitized thesis going back before 2000,
- Accepted at a conference. A paper accepted at a conference that has not yet occurred, maybe available in preprint form; otherwise you are going to have to email the author (search on the author names to find their university/GitHub webpage and thence their email),
- Both CiteSeer and then Semantic Scholar were once great resources. These days, CiteSeer has all but disappeared, and Semantic Scholar seems to mostly link to publisher sites and sometimes to external sites.
Dead-tree search techniques are a topic for history books.
More search suggestions welcome.
Conference vs Journal publication
Today is the start of the 2023 International Conference on Software Engineering (the 45’th ICSE, pronounced ick-see), the top ranked software systems conference and publication venue; this is where every academic researcher in the field wants to have their papers appear. This is a bumper year, of the 796 papers submitted 209 were accepted (26%; all numbers a lot higher than previous years), and there are 3,821 people listed as speaking/committee member/chairing session. There are also nine co-hosted conferences (i.e., same time/place) and twenty-two co-hosted workshops.
For new/niche conferences, the benefit of being co-hosted with a much larger conference is attracting more speakers/attendees. For instance, the International Conference on Technical Debt has been running long enough for the organizers to know how hard it is to fill a two-day program. The submission deadline for TechDebt 2023 papers was 23 January, six-weeks after researchers found out whether their paper had been accepted at ICSE, i.e., long enough to rework and submit a paper not accepted at ICSE.
Software research differs from research in many other fields in that papers published in major conferences have a greater or equal status compared to papers published in most software journals.
The advantage that conferences have over journals is a shorter waiting time between submitting a paper, receiving the acceptance decision, and accepted papers appearing in print. For ICSE 2023 the yes/no acceptance decision wait was 3-months, with publication occurring 5-months later; a total of 8-months. For smaller conferences, the time-intervals can be shorter. With journals, it can take longer than 8-months to hear about acceptance, which might only be tentative, with one or more iterations of referee comments/corrections before a paper is finally accepted, and then a long delay before publication. Established academics always have a story to tell about the time and effort needed to get one particular paper published.
In a fast changing field, ‘rapid’ publication is needed. The downside of having only a few months to decide which papers to accept, is that there is not enough time to properly peer-review papers (even assuming that knowledgable reviewers are available). Brief peer-review is not a concern when conference papers are refined to eventually become journal papers, but researchers’ time is often more ‘productively’ spent writing the next conference paper (productive in the sense of papers published per unit of effort), this is particularly true given that work invested in a journal publication does not automatically have the benefit of greater status.
The downside of rapid publication without follow-up journal publication, is the proliferation of low quality papers, and a faster fashion cycle for research topics (novelty is an important criterion for judging the worthiness of submitted papers).
Conference attendance costs (e.g., registration fee+hotel+travel+etc) can be many thousands of pounds/dollars, and many universities/departments will only fund those who to need to attend to present a paper. Depending on employment status, the registration fee for just ICSE is $1k+, with fees for each co-located events sometimes approaching $1k.
Conferences have ‘solved’ this speaker only funding issue by increasing the opportunities to present a paper, by, for instance, sessions for short 7-minute talks, PhD students, and even undergraduates (which also aids the selection of those with an aptitude for the publish or perish treadmill).
The main attraction of attending a conference is the networking opportunities it provides. Sometimes the only people at a session are the speakers and their friends. Researchers on short-term contracts will be chatting to Principle Investigators whose grant applications were recently approved. Others will be chatting to existing or potential collaborators; and there is always lots of socialising. ICSE even offers childcare for those who can afford to fly their children to Australia, and the locals.
There is an industrial track, but these are often treated as second class citizens, e.g., if a schedule clash occurs they will be moved or cancelled. There is even a software engineering in practice track. Are the papers on other tracks expected to be unconnected with software engineering practice, or is this an academic rebranding of work related to industry? While academics offer lip-service to industrial relevance, connections with industry are treated as a sign of low status.
In general, for people working in industry, I don’t think it’s worth attending an academic conference. Larger companies treat conferences as staff recruiting opportunities.
Are people working in industry more likely to read conference papers than journal papers? Are people working in industry more likely to read ICSE papers than papers appearing at other conferences?
My book Evidence Based Software Engineering cites 2,035 papers, and is a sample of one, of people working in industry. The following table shows the percentage of papers appearing in each kind of publication venue (code+data):
Published %
Journal 42
Conference 18
Technical Report 13
Book 11
Phd Thesis 3
Masters Thesis 2
In Collection 2
Unpublished 2
Misc 2 |
The 450 conference papers appeared at 285 different conferences, with 26% of papers appearing at the top ten conferences. The 871 journal papers appeared in 389 different journals, with 24% of the papers appearing in the top ten journals.
Count Conference 27 International Conference on Software Engineering 15 International Conference on Mining Software Repositories 14 European Software Engineering Conference 13 Symposium on the Foundations of Software Engineering 10 International Conference on Automated Software Engineering 8 International Symposium on Software Reliability Engineering 8 International Symposium on Empirical Software Engineering and Measurement 8 International Conference on Software Maintenance 7 International Conference on Software Analysis, Evolution, and Reengineering 7 International Conference on Program Comprehension Count Journal 28 Transactions on Software Engineering 27 Empirical Software Engineering 25 Psychological Review 21 PLoS ONE 19 The Journal of Systems and Software 18 Communications of the ACM 17 Cognitive Psychology 15 Journal of Experimental Psychology: Learning, Memory, & Cognition 14 Memory & Cognition 13 Psychonomic Bulletin & Review 13 Psychological Bulletin |
Transactions on Software Engineering has the highest impact factor of any publication in the field, and it and The Journal of Systems and Software rank second and third on the h5-index, with ICSE ranked first (in the field of software systems).
After scanning paper titles, and searching for pdfs, I have a to-study collection of around 20 papers and 10 associated datasets from this year’s ICSE+co-hosted.
The difference is significant
A statement that invariably appears in the published results of empirical studies comparing some property of two or more sets of numbers is that the difference is significant (if the difference is not significant, the paper is unlikely to be published). Here, the use of the word significant is the shortened form of the term statistically significant.
It is possible that two sets of measurements just so happen to have, for instance, the same/different mean value. Statistical significance is an estimate of the likelihood that an observed result is unlikely to have occurred by chance. The mechanics of calculating a numeric value for statistical significance can be complicated; the commonly seen p-value applies to a particular kind of statistical significance.
The fact that a difference is unlikely to have occurred by chance does not mean that the magnitude of the difference is of any practical use, or of any theoretical interest.
How large must a difference be to make it of practical use?
When I was in the business of selling code optimization tools for microcomputer software, a speed/code size improvement of at least 10% was needed before a worthwhile number of people were likely to pay for the software (a few would pay for less, and a few wanted more improvements before they would pay). I would not be surprised to find that very different percentages were applicable in other developer ecosystems.
In software engineering research papers, presentation of the practical use of work is often nothing more than a marketing pitch by the authors, not a list of estimated usefulness for different software ecosystems.
These days the presentation of material in empirical software engineering papers is often organized around a series of research questions, e.g., “How does X vary across projects?”, “Does the presence of X significantly impact the issue resolution time?”. One or more of these research questions are pitched as having practical relevance, and the statistical significance of the results is presented as vindication of this claimed relevance. Getting a paper published requires that those asked to review agree that the questions it asks and answers are interesting.
This method of paper organization and presentation is not unique to researchers in software engineering. To attract funding, all researchers need to actively promote the value of their wares.
The problem I have with software engineering papers is the widespread use of simplistic techniques (e.g., a Wilcoxon signed-rank test to check the significance of the difference between the means of two samples), and reporting little more than p-value significance; yes, included plots may sometimes be visually appealing, but other times just confused.
If researchers fitted regression models to their data, it becomes possible to estimate the contribution made by each of the attributes measured to the observed behavior. Surprisingly often, the size of the contribution is relatively small, while still being statistically significant.
By not building regression models, software researchers are cluttering up the list of known statistically significant behaviors with findings about factors whose small actual contribution makes it unlikely that they will be of practical interest.
Academic recognition for creating and supporting software
A scientific paper is supposed to contain enough information that somebody skilled in the field can perform the experiment(s) described therein (issues around the money needed to obtain access to the necessary equipment tend to be side stepped). In addition to the skills generally taught within a field, every niche has its specific skill set, which for leading edge research may only be available in one lab.
Bespoke software has become an essential component of many research projects, and the ability to reimplement the necessary software is rarely considered to be a necessary skill. Some researchers consider software to be “just code” whose creation is not really a skill that is worth investing in acquiring.
There is a widespread belief in academic circles that the solution to the issues created by bespoke software is for researchers to release the source code of the software they create.
Experienced developers will laugh at the idea that once the source code is available, running it is straight forward. Figuring out how to run somebody else’s code can be a very time-consuming process, particularly when the person who wrote it is relatively inexperienced.
This post is about the social issues around the bespoke research code being made available, and not the technical issues likely to be encountered in building it on another researcher’s computer.
Lots of researchers do make their code available, without being asked, and some researchers actively promote the software they have written. In a few cases, active software ecosystems have sprung up around a research topic, e.g., Astropy and SunPy.
However, a lot of code never gets released. Based on my own experience of asking for code (in the last 10 years, most of my requests have been for data), reasons given by researchers for not making the code they have written available to others, include:
- not replying to email requests for the code,
- not sure that they still have the all code, which is taken as a reason for not sending what they have. This may also be a cover story for another reason they don’t want to admit to,
- they don’t want the hassle of supporting other users of the code. Having received some clueless requests for help on software I have released, I have sympathy for this position. Sometimes pointing out that I am an experienced developer who does not need support, works, other times it just changes the reason given,
- they think the code is poorly written, and that this poor of quality will make them look bad. Pointing out that research code is leading edge (rare true, it’s an attempt to stroke their ego), and not supposed to be polished, rarely works for me. Some people are just perfectionists, with a strong aversion to showing others anything that has not been polished to death,
- a large investment was made to create the software, and they want to reap all the benefits. I have a lot of sympathy with this position. Some research fields are very competitive, or sometimes the researcher just wants to believe that they really will get another grant to work on the subject.
Researchers who create and support research software complain that they don’t get any formal recognition for this work; which begs the question: why are you working on this software when you know that you are unlikely to receive any recognition?
How might researchers receive recognition for writing, supporting and releasing code?
Citations to published papers are a commonly used technique for measuring the worth of the work done by a researcher (this metric is used when evaluating people for promotion, awarding grants, and evaluating departments), and various organizations are promoting the use of citations for software.
Some software provides enough benefits that the authors can write a conventional paper about it, e.g., a paper on Astropy (which does not cite any of the third-party packages used in its own implementation). But a lot of research software does not have sufficient general appeal to warrant a paper.
Are citations for software a good idea?
An important characteristic of any evaluation metric is how hard it is to fake a good score.
Research papers are rated by the journal in which they are published, with each journal having its own rating (a short-term metric), and the number of times the paper is cited (a longer-term metric). Papers are reviewed, with many failing to be accepted (at least by the higher quality journals; there are so-called predatory journals that will publish anything for a fee).
While there are a few journals where source code may be an integral component of a paper, most research software is published on sites having minimal acceptance criteria, e.g., Github.
Will citations to software become as commonplace as citations to other papers?
I regularly read software papers that cites software packages, but this practice is a long way from being common.
Will those awarding job promotions and grants start to include software creation as having a status comparable to published papers? We will have to wait and see.
Will the lure of recognition via citations increase the quantity of source being released?
I don’t think it will have any impact until the benefits of software citations are seen to be worthwhile (which may be many years away).
First language taught to undergraduates in the 1990s
The average new graduate is likely to do more programming during the first month of a software engineering job, than they did during a year as an undergraduate. Programming courses for undergraduates is really about filtering out those who cannot code.
Long, long ago, when I had some connection to undergraduate hiring, around 70-80% of those interviewed for a programming job could not write a simple 10-20 line program; I’m told that this is still true today. Fluency in any language (computer or human) takes practice, and the typical undergraduate gets very little practice (there is no reason why they should, there are lots of activities on offer to students and programming fluency is not needed to get a degree).
There is lots of academic discussion around which language students should learn first, and what languages they should be exposed to. I have always been baffled by the idea that there was much to be gained by spending time teaching students multiple languages, when most of them barely grasp the primary course language. When I was at school the idea behind the trendy new maths curriculum was to teach concepts, rather than rote learning (such as algebra; yes, rote learning of the rules of algebra); the concept of number-base was considered to be a worthwhile concept and us kids were taught this concept by having the class convert values back and forth, such as base-10 numbers to base-5 (base-2 was rarely used in examples). Those of us who were good at maths instantly figured it out, while everybody else was completely confused (including some teachers).
My view is that there is no major teaching/learning impact on the choice of first language; it is all about academic fashion and marketing to students. Those who have the ability to program will just pick it up, and everybody else will flounder and do their best to stay away from it.
Richard Reid was interested in knowing which languages were being used to teach introductory programming to computer science and information systems majors. Starting in 1992, he contacted universities roughly twice a year, asking about the language(s) used to teach introductory programming. The Reid list (as it became known), was regularly updated until Reid retired in 1999 (the average number of universities included in the list was over 400); one of Reid’s ex-students, Frances VanScoy, took over until 2006.
The plot below is from 1992 to 2002, and shows languages in the top with more than 3% usage in any year (code+data):
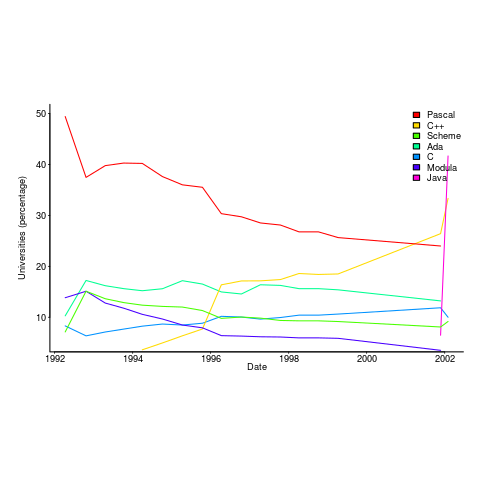
Looking at the list again reminded me how widespread Pascal was as a teaching language. Modula-2 was the language that Niklaus Wirth designed as the successor of Pascal, and Ada was intended to be the grown up Pascal.
While there is plenty of discussion about which language to teach first, doing this teaching is a low status activity (there is more fun to be had with the material taught to the final year students). One consequence is lack of any real incentive for spending time changing the course (e.g., using a new language). The Open University continued teaching Pascal for years, because material had been printed and had to be used up.
C++ took a while to take-off because of its association with C (which was very out of fashion in academia), and Java was still too new to risk exposing to impressionable first-years.
A count of the total number of languages listed, between 1992 and 2002, contains a few that might not be familiar to readers.
Ada Ada/Pascal Beta Blue C
1087 1 10 3 667
C/Java C/Scheme C++ C++/Pascal Eiffel
1 1 910 1 29
Fortran Haskell HyperTalk ISETL ISETL/C
133 12 2 30 1
Java Java/Haskell Miranda ML ML/Java
107 1 48 16 1
Modula-2 Modula-3 Oberon Oberon-2 ObjPascal
727 24 26 7 22
Orwell Pascal Pascal/C Prolog Scheme
12 2269 1 12 752
Scheme/ML Scheme/Turing Simula Smalltalk SML
1 1 14 33 88
Turing Visual-Basic
71 3 |
I had never heard of Orwell, a vanity language foisted on Oxford Mathematics and Computation students. It used to be common for someone in computing departments to foist their vanity language on students; it enabled them to claim the language was being used and stoked their ego. Is there some law that enables students to sue for damages?
The 1990s was still in the shadow of the 1980s fashion for functional programming (which came back into fashion a few years ago). Miranda was an attempt to commercialize a functional language compiler, with Haskell being an open source reaction.
I was surprised that Turing was so widely taught. More to do with the stature of where it came from (university of Toronto), than anything else.
Fortran was my first language, and is still widely used where high performance floating-point is required.
ISETL is a very interesting language from the 1960s that never really attracted much attention outside of New York. I suspect that Blue is BlueJ, a Java IDE targeting novices.
Want to be the coauthor of a prestigious book? Send me your bid
The corruption that pervades the academic publishing system has become more public.
There is now a website that makes use of an ingenious technique for helping people increase their paper count (as might be expected, the competitive China thought of it first). Want to be listed as the first author of a paper? Fees start at $500. The beauty of the scheme is that the papers have already been accepted by a journal for publication, so the buyer knows exactly what they are getting. Paying to be included as an author before the paper is accepted incurs the risk that the paper might not be accepted.
Measurement of academic performance is based on number of papers published, weighted by the impact factor of the journal in which they are published. Individuals seeking promotion and research funding need an appropriately high publication score; the ranking of university departments is based on the publications of its members. The phrase publish or perish aptly describes the process. As expected, with individual careers and departmental funding on the line, the system has become corrupt in all kinds of ways.
There are organizations who will publish your paper for a fee, 100% guaranteed, and you can even attend a scam conference (that’s not how the organizers describe them). Problem is, word gets around and the weighting given to publishing in such journals is very low (or it should be, not all of them get caught).
The horror being expressed at this practice is driven by the fact that money is changing hands. Adding a colleague as an author (on the basis that they will return the favor later) is accepted practice; tacking your supervisors name on to the end of the list of authors is standard practice, irrespective of any contribution that might have made (how else would a professor accumulate 100+ published papers).
I regularly receive emails from academics telling me they would like to work on this or that with me. If they look like proper researchers, I am respectful; if they look like an academic paper mill, my reply points out (subtly or otherwise) that their work is not of high enough standard to be relevant to industry. Perhaps I should send them a quote for having their name appear on a paper written by me (I don’t publish in academic journals, so such a paper is unlikely to have much value in the system they operate within); it sounds worth doing just for the shocked response.
I read lots of papers, and usually ignore the list of authors. If it looks like there is some interesting data associated with the work, I email the first author, and will only include the other authors in the email if I am looking to do a bit of marketing for my book or the paper is many years old (so the first author is less likely to have the data).
I continue to be amazed at the number of people who continue to strive to do proper research in this academic environment.
I wonder how much I might get by auctioning off the coauthoship of my software engineering book?
Altruistic innovation and the study of software economics
Recently, I have been reading rather a lot of papers that are ostensibly about the economics of markets where applications, licensed under an open source license, are readily available. I say ostensibly, because the authors have some very odd ideas about the activities of those involved in the production of open source.
Perhaps I am overly cynical, but I don’t think altruism is the primary motivation for developers writing open source. Yes, there is an altruistic component, but I would list enjoyment as the primary driver; developers enjoy solving problems that involve the production of software. On the commercial side, companies are involved with open source because of naked self-interest, e.g., commoditizing software that complements their products.
It may surprise you to learn that academic papers, written by economists, tend to be knee-deep in differential equations. As a physics/electronics undergraduate I got to spend lots of time studying various differential equations (each relating to some aspect of the workings of the Universe). Since graduating, I have rarely encountered them; that is, until I started reading economics papers (or at least trying to).
Using differential equations to model problems in economics sounds like a good idea, after all they have been used to do a really good job of modeling how the universe works. But the universe is governed by a few simple principles (or at least the bit we have access to is), and there is lots of experimental data about its behavior. Economic issues don’t appear to be governed by a few simple principles, and there is relatively little experimental data available.
Writing down a differential equation is easy, figuring out an analytic solution can be extremely difficult; the Navier-Stokes equations were written down 200-years ago, and we are still awaiting a general solution (solutions for a variety of special cases are known).
To keep their differential equations solvable, economists make lots of simplifying assumptions. Having obtained a solution to their equations, there is little or no evidence to compare it against. I cannot speak for economics in general, but those working on the economics of software are completely disconnected from reality.
What factors, other than altruism, do academic economists think are of major importance in open source? No, not constantly reinventing the wheel-barrow, but constantly innovating. Of course, everybody likes to think they are doing something new, but in practice it has probably been done before. Innovation is part of the business zeitgeist and academic economists are claiming to see it everywhere (and it does exist in their differential equations).
The economics of Linux vs. Microsoft Windows is a common comparison, i.e., open vs. close source; I have not seen any mention of other open source operating systems. How might an economic analysis of different open source operating systems be framed? How about: “An economic analysis of the relative enjoyment derived from writing an operating system, Linux vs BSD”? Or the joy of writing an editor, which must be lots of fun, given how many have text editors are available.
I have added the topics, altruism and innovation to my list of indicators of poor quality, used to judge whether its worth spending more than 10 seconds reading a paper.
Is it worth attending an academic conference or workshop?
If you work in industry, is it worth attending an academic conference or workshop?
The following observations are based on my attending around 50 software engineering and compiler related conferences/workshops, plus discussion with a few other people from industry who have attended such events.
Short answer: No.
Slightly longer answer: Perhaps, if you are looking to hire somebody knowledgeable in a particular domain.
Much longer answer: Academics go to conferences to network. They are looking for future collaborators, funding, jobs, and general gossip. What is the point of talking to somebody from industry? Academics will make small talk and be generally friendly, but they don’t know how to interact, at the professional level, with people from industry.
Why are academics generally hopeless at interacting, at the professional level, with people from industry?
Part of the problem is lack of practice, many academic researchers live in a world that rarely intersects with people from industry.
Impostor syndrome is another. I have noticed that academics often think that people in industry have a much better understanding of the realities of their field. Those who have had more contact with people from industry might have noticed that impostor syndrome is not limited to academia.
Talking of impostor syndrome, and feeling of being a fraud, academics don’t seem to know how to handle direct criticism. Again I think it is a matter of practice. Industry does not operate according to: I won’t laugh at your idea, if you don’t laugh at mine, which means people within industry are practiced at ‘robust’ discussion (this does not mean they like it, and being good at handling such discussions smooths the path into management).
At the other end of the impostor spectrum, some academics really do regard people working in industry as simpletons. I regularly have academics express surprise that somebody in industry, i.e., me, knows about this-that-or-the-other. My standard reply is to say that its because I paid more for my degree and did not have the usual labotomy before graduating. Not a reply guaranteed to improve industry/academic relations, but I enjoy the look on their faces (and I don’t expect they express that opinion again to anyone else from industry).
The other reason why I don’t recommend attending academic conferences/workshops, is that lots of background knowledge is needed to understand what is being said. There is no point attending ‘cold’, you will not understand what is being presented (academic presentations tend to be much better organized than those given by people in industry, so don’t blame the speaker). Lots of reading is required. The point of attending is to talk to people, which means knowing something about the current state of research in their area of interest. Attending simply to learn something about a new topic is a very poor use of time (unless the purpose is to burnish your c.v.).
Why do I continue to attend conferences/workshops?
If a conference/workshop looks like it will be attended by people who I will find interesting, and it’s not too much hassle to attend, then I’m willing to go in search of gold nuggets. One gold nugget per day is a good return on investment.
Unappreciated bubble research
Every now and again an academic journal dedicates a single issue to one topic. I laughed when I saw the topic of an upcoming special issue on “Enhancing Credibility of Empirical Software Engineering”.
If you work in industry, you probably have a completely different interpretation of the intent of this issue, compared to somebody working in academia, i.e., you think the topic is about getting academic researchers to work on stuff of interest to industry. In academia the issue is about getting industry to treat the research work being done in universities as relevant to their needs, i.e., industry just does not appreciate how useful the work being done in universities is to solving real world problems.
Yes fellow industrialists, the credibility problem is all down to us not appreciating the work of those hard-working academics (I was once at a university meeting and the Dean referred to the industrialists at the meeting, which confused me because I did not know any were present; sometime later the penny dropped and I realised he was talking abut me and another guy who was working in industry).
The real problem is that most research academics have little idea what goes on in industry and what research results might be of interest to industry. This is not surprising given that the academic career ladder keeps people within the confines of the university bubble.
I regularly have academics express surprise that somebody in industry, i.e., me, knows about this-that-or-the-other. This baffled me for a while, until I realised that many academics really do regard people working in industry as simpletons; I now reply that its because I paid more for my degree and did not have the usual labotomy before graduating. Now they are baffled.
The solution to the problem of industrial research relevance is for academics to be willing to move outside the university bubble, to go out and interact with people in industry. However, there are powerful incentives pushing academics away from talking to industry:
- academic performance is measured by papers published and the chances of getting a paper published are improved if it involves a fashionable topic (yes fellow industrialists, academics suffer from this problem too). Stuff that industry is interested in is not fashionable, at least not yet. I don’t see many researchers being willing to risk working on very unfashionable topics in the hope that their work might get published,
- contact with industry will open the eyes of many academics to the interesting work being done there and the much higher paying jobs available (at least for those who are any good). Heads’ of department don’t want to lose their good people and have every incentive to discourage researchers having any contact with industry. The senior staff are sufficiently embedded in the system that they can be trusted to talk to industry, rather like senior communist party members being allowed to visit the West during the cold war.
An alternative way for academic research to connect with industry is for the research to be done by people with a lot of industry experience. There are a surprising number of people working in industry who are bored and are contemplating doing a PhD for something interesting to do (e.g., a public proclamation).
Again there are powerful incentives pushing against industry contact. PhD students do the academic grunt work and so compliant people are needed, i.e., recent graduates who will accept that this is how things work, not independent people who know better (such as those with a decent amount of industry experience). Worries about industrialists not being willing to tow-the-line with respect to departmental thinking are probably groundless, plenty of this sort of thing goes on in industry.
I found out at the weekend that only one central London university offers a computing related part-time PhD program (Birkbeck; few people can afford to a significant drop in income); part-time students are not around to do the grunt work.
What is empirical software engineering?
Writing a book about empirical software engineering requires making decisions about which subjects to discuss and what to say about them.
The obvious answer to “which subjects” is to include everything that practicing software engineers do, when working on software systems; there are some obvious exclusions like traveling to work. To answer the question of what software engineers do, I have relied on personal experience, my own and what others have told me. Not ideal, but it’s the only source of information available to me.
The foundation of an empirical book is data, and I only talk about subjects for which public data is available. The data requirement is what makes writing this book practical; there is not a lot of data out there. This lack of data has allowed me to avoid answering some tricky questions about whether something is, or is not, part of software engineering.
What approach should be taken to discussing the various subjects? Economics, as in cost/benefit analysis, is the obvious answer.
In my case, I am a developer and the target audience is developers, so the economic perspective is from the vendor side, not the customer side (e.g., maximizing profit, not minimizing cost or faults). Most other books have a customer oriented focus, e.g., high reliability is important (with barely a mention of the costs involved); this focus on a customer oriented approach comes from the early days of computing where the US Department of Defense funded a lot of software research driven by their needs as a customer.
Again the lack of data curtails any in depth analysis of the economic issues involved in software development. The data is like a patchwork of islands, the connections between them are under water and have to be guessed at.
Yes, I am writing a book on empirical software engineering that contains the sketchiest of outlines on what empirical software engineering is all about. But if the necessary data was available, I would not live long enough to get close to completing the book.
What of the academic take on empirical software engineering? Unfortunately the academic incentive structure strongly biases against doing work of interest to industry; some of the younger generation do address industry problems, but they eventually leave or get absorbed into the system. Academics who spend time talking to people in industry, to find out what problems exist, tend to get offered jobs in industry; university managers don’t like loosing their good people and are incentivized to discourage junior staff fraternizing with industry. Writing software is not a productive way of generating papers (academics are judged by the number and community assessed quality of papers they produce), so academics spend most of their work time babbling in front of spotty teenagers; the result is some strange ideas about what industry might find useful.
Academic software engineering exists in its own self-supporting bubble. The monkeys type enough papers that it is always possible to find some connection between an industry problem and published ‘research’.
Recent Comments