Archive
How many ways of programming the same specification?
How many different ways are there of writing a program to implement a given specification? Non-trivial specifications probably have an enormous number of possible programming solutions. What about really simple specifications, say something based on the 3n+1 problem (write a programs that takes a list of integers and outputs their ‘3n+1’ length; ‘3n+1’ length algorithm: for integer  , if is even divide it by
, if is even divide it by  and assign the result to , otherwise is odd, multiply it by
and assign the result to , otherwise is odd, multiply it by  and add
and add  to give the new value of ; repeat the process, counting the number of iterations until reaches )?.
to give the new value of ; repeat the process, counting the number of iterations until reaches )?.
I can think of a dozen or so (slightly) different ways that I might write a program to solve this problem. If I really had to I could probably come up with a few hundred different solutions, but I think the source code of these programs would not look like something I would normally write. If I was to run a competition how many different answers might I get? If you twisted my arm I might have said 500. What do you think?
Meine van der Meulen studied the N-version programing for his PhD thesis (N groups independently write a program to the same specification, compare the output of the N programs and select the ‘best’ answer; cannot find a copy of the thesis online). This was empirical work and van der Meulen posted the above 3n+1 problem to a programming competition website and used the 95,497 submitted solutions for his analysis; he also kindly sent me a copy of the solutions (11,674 solutions were written in Pascal, the rest were in C).
Not all the solutions correctly solve the problem. I ignored this ‘detail’. There are also many duplicates (as in identical source code).
I am interested in differently coded solutions. I defined different as the sequence of operators/punctuators making up the program being different (or at least having a different MD5 checksum), so identifiers and comments are ignored. Should permutations in the order of independent adjacent statements really be counted as different? For the sack of keeping my life simple they current are. This definition of differently coded reduces the original 63,823 C programs down to 6,301. Wow, how are 6k+ different programs possible?
The original specification did not mention performance, but lots of developers did all sorts of weird and wonderful stuff to improve runtime performance. The most common optimization technique used (apart from some inventive ways of checking for odd/even) was to cache previous answers along with the solution for all the intermediate steps that were passed through on the way to 1 (the path from the starting value to 1 is very erratic and sometimes goes through values greater than the starting value) and check this cache to see whether it contains the current value of.
A common measure of program size is lines of code. What is the size distribution, in LOC, for these 6,301 programs? One program has been labeled an outlier and excluded from the analysis (most of its 8,345 lines were taken up with initializing a data structure with precomputed solutions).
The following plots lines of code against the number of programs containing that many lines (download code and data).
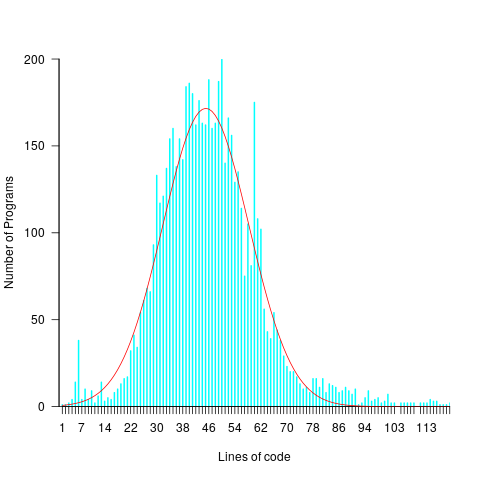
The mean program length is 46.3 lines, standard deviations 15.4. The red curve is a Normal distribution whose mean/sd has been tweaked to give a better visual fit (a Shapiro-Wilk test dispels any hope tht the distribution might be Normal). There is no reason to think that the data will be fitted by any known distribution and I’m not going to overfit on one data-point. If pushed I will wave my arms and describe the distribution as Normalish with added spikes and a fat right tail.
That spike around 60 lines is interesting. Is this group of solutions all doing the same thing but with different statement orderings? I have previously written about how gcc/llvm do a good job of turning the core of the algorithm into the same machine code. Perhaps a future version of these compilers will be able to tell us whether the programs clumping around 60 LOC are doing the same thing.
Compiler benchmarking for the 21st century
I would like to propose a new way of measuring the quality of a compiler’s code generator: The highest quality compiler is one that generates identical code for all programs that produce the same output, e.g., a compiler might spot programs that calculate pi and always generate code that uses the most rapidly converging method known. This is a very different approach to the traditional methods based on using (mostly) execution time or size (usually code but sometimes data) as a measure of quality.
Why is a new measurement method needed, and why choose this one? It is relatively easy for compiler vendors to tune their products to the commonly used benchmark and they seem to have lost their role as drivers for new optimization techniques. Different developers have different writing habits and companies should not have to waste time and money changing developer habits just to get the best quality code out of a compiler; compilers should handle differences in developer coding habits and not let it affect the quality of generated code. There are major savings to be had by optimizing the effect that developers are trying to achieve rather than what they have actually written (these days new optimizations targeting at what developers have written show very low percentage improvements).
Deducing that a function calculates pi requires a level of sophistication in whole program analysis that is unlikely to be available in production compilers for some years to come (ok, detecting 4*atan(1.0) is possible today). What is needed is a collection of compilable files containing source code that aims to achieve an outcome in lots of different ways. To get the ball rolling the “3n times 2” problem is presented as the first of this new breed of benchmarks.
The “3n times 2” problem is a variant on the 3n+1 problem that has been tweaked to create more optimization opportunities. One implementation of the “3n times 2” problem is:
if (is_odd(n)) n = 3*n+1; else n = 2*n; // this is n = n / 2; in the 3n+1 problem |
There are lots of ways of writing code that has the same effect, some of the statements I have seen for calculating n=3*n+1 include: n = n + n + n + 1, n = (n << 1) + n + 1 and n *= 3; n++, while some of the ways of checking if n is odd include: n & 1, (n / 2)*2 != n and n % 2.
I have created a list of different ways in which 3*n+1 might be calculated and is_odd(n) might be tested and written a script to generate a function containing all possible permutations (to reduce the number of combinations no variants were created for the least interesting case of n=2*n, which was always generated in this form). The following is a snippet of the generated code (download everything):
if (n & 1) n=(n << 2) - n +1; else n*=2; if (n & 1) n=3*n+1; else n*=2; if (n & 1) n += 2*n +1; else n*=2; if ((n / 2)*2 != n) { t=(n << 1); n=t+n+1; } else n*=2; if ((n / 2)*2 != n) { n*=3; n++; } else n*=2; |
Benchmarks need a means of summarizing the results and here I make a stab at doing that for gcc 4.6.1 and llvm 2.9, when executed using the -O3 option (output here and here). Both compilers generated a total of four different sequences for the 27 'different' statements (I'm not sure what to do about the inline function tests and have ignored them here) with none of the sequences being shared between compilers. The following lists the number of occurrences of each sequence, e.g., gcc generated one sequence 16 times, another 8 times and so on:
gcc 16 8 2 1 llvm 12 6 6 3
How might we turn these counts into a single number that enables compiler performance to be compared? One possibility is to award 1 point for each of the most common sequence, 1/2 point for each of the second most common, 1/4 for the third and so on. Using this scheme, gcc gets 20.625, and llvm gets 16.875. So gcc has greater consistency (I am loathed to use the much overused phrase higher quality).
Now for a closer look at the code generated.
Both compilers always generated code to test the least significant bit for the conditional expressions n & 1 and n % 2. For the test (n / 2)*2 != n gcc generated the not very clever right-shift/left-shift/compare while llvm and'ed out the bottom bit and then compared; so both compilers failed to handle what is a surprisingly common check for a number being odd.
The optimal code for n=3*n+1 on a modern x86 processor is (lots of register combinations are possible, let's assume rdx contains n) leal 1(%rdx,%rdx,2), %edx and this is what both compilers generated a lot of the time. This locally optimal code is not always generated because:
- gcc fails to detect that
(n << 2)-n+1is equivalent to(n << 1)+n+1and generates the sequenceleal 0(,%rax,4), %edx ; subl %eax, %edx ; addl $1, %edx(I pointed this out to a gcc maintainer sometime ago, and he suggested reporting it as a bug). This 'bug' occurs three times in total. - For some forms of the calculation llvm generates globally better code by taking the else arm into consideration. For instance, when the calculation is written as
n += (n << 1) +1llvm deduces that(n << 1)and the2*nin theelseare equivalent, evaluates this value into a register before performing the conditional test thus removing the need for an unconditional jump around the 'else' code:leal (%rax,%rax), %ecx testb $1, %al je .LBB0_8 # BB#7: orl $1, %ecx # deduced ecx is even, arithmetic unit not needed! addl %eax, %ecx .LBB0_8:
This more efficient sequence occurs nine times in total.
The most optimal sequence was generated by gcc:
testb $1, %dl leal (%rdx,%rdx), %eax je .L6 leal 1(%rdx,%rdx,2), %eax .L6: |
with llvm and pre 4.6 versions of gcc generating the more traditional form (above, gcc 4.6.1 assumes that the 'then' arm is the most likely to be executed and trades off a leal against a very slow jmp):
testb $1, %al je .LBB0_5 # BB#4: leal 1(%rax,%rax,2), %eax jmp .LBB0_6 .LBB0_5: addl %eax, %eax .LBB0_6: |
There is still room for improvement, perhaps by using the conditional move instruction (which gcc actually generates within the not-very-clever code sequence for (n / 2)*2 != n) or by using the fact that eax already holds 2*n (the potential saving would come through a reduction in complexity of the internal resources needed to execute the instruction).
llvm insists on storing the calculated value back into n at the end of every statement. I'm not sure if this is a bug or a feature designed to make runtime debugging easier (if so it ought to be switched off by default).
Missed optimization opportunities (not intended to be part of this benchmark and if encountered would require a restructuring of the test source) include noticing that if is odd then  is always even, creating the opportunity to perform the following multiply by 2 without an if test.
is always even, creating the opportunity to perform the following multiply by 2 without an if test.
Perhaps one day, compilers will figure out when a program is calculating pi and generate code that uses the best known algorithm. In the meantime, I am interested in hearing suggestions for additional different-algorithm-same-code benchmarks.
Searching for the source line implementing 3n+1
I have been doing some research on the variety of ways that different developers write code to implement the same specification and have been lucky enough to obtain the source code of approximately 6,000 implementations of a problem based on the 3n+1 algorithm. At some point this algorithm requires multiplying a value by three and adding one, e.g., n=3*n+1;.
While I expected some variation in the coding of many parts of the algorithm I did not expect to see much variation in the n=n*3+1;. I was in for a surprise, the following are some of the different implementations I have seen so far:
n = n + n + n + 1 ;
n += n + n + 1;
n = (n << 1) + n + 1;
n += (n << 1) + 1;
n *= 3; n++;
t = (n << 1) ; n = t + n + 1;
n = (n << 2) - n + 1;
I was already manually annotating the source and it was easy for me to locate the line implementing
I mentioned this search problem over drinks after a talk I gave at the Oxford branch of the ACCU last week and somebody (Huw ???) suggested that perhaps the code generated by gcc would be the same no matter how 3n+1 was implemented. I could see lots of reasons why this would not be the case, but the idea was interesting and worth investigation.
At the default optimization level the generated x86 code is different for different implemenetations, but optimizing at the “-O 3” level results in all but one of the above expressions generating the same evaluation code:
leal 1(%rax,%rax,2), %eax |
The exception is (n << 2) - n + 1 which results in shift/subtract/add. Perhaps I should report this as a bug in gcc :-)
I was surprised that gcc exhibited this characteristic and I plan to carry out more tests to trace out the envelope of this apparent "same generated code for equivalent expressions" behavior of gcc.
Recent Comments