Archive
Almost all published analysis of fault data is worthless
Faults are the subject of more published papers that any other subject in empirical software engineering. Unfortunately, over 98.5% of these fault related papers are at best worthless and at worst harmful, i.e., make recommendations whose impact may increase the number of faults.
The reason most fault papers are worthless is the data they use and the data they don’t to use.
The data used
Data on faults in programs used to be hard to obtain, a friend in a company that maintained a fault database was needed. Open source changed this. Now public fault tracking systems are available containing tens, or even hundreds, of thousands of reported faults. Anybody can report a fault, and unfortunately anybody does; there is a lot of noise mixed in with the signal. One study found 43% of reported faults were enhancement requests, the same underlying fault is reported multiple times (most eventually get marked as duplicate, at the cost of much wasted time) and …
Fault tracking systems don’t always contain all known faults. One study found that the really important faults are handled via email discussion lists, i.e., they are important enough to require involving people directly.
Other problems with fault data include: biased reported of problems, reported problem caused by a fault in a third-party library, and reported problem being intermittent or not reproducible.
Data cleaning is the essential first step that many of those who analyze fault data fail to perform.
The data not used
Users cause faults, i.e., if nobody ever used the software, no faults would be reported. This statement is as accurate as saying: “Source code causes faults”.
Reported faults are the result of software being used with a set of inputs that causes the execution of some sequence of tokens in the source code to have an effect that was not intended.
The number and kind of reported faults in a program depends on the variety of the input and the number of faults in the code.
Most fault related studies do not include any user related usage data in their analysis (the few that do really stand out from the crowd), which can lead to very wrong conclusions being drawn.
User usage data is very hard to obtain, but without it many kinds of evidence-based fault analysis are doomed to fail (giving completely misleading answers).
The first compiler was implemented in itself
I have been reading about the world’s first actual compiler (i.e., not a paper exercise), described in Corrado Böhm’s PhD thesis (French version from 1954, an English translation by Peter Sestoft). The thesis, submitted in 1951 to the Federal Technical University in Zurich, takes some untangling; when you are inventing a new field, ideas tend to be expressed using existing concepts and terminology, e.g., computer peripherals are called organs and registers are denoted by the symbol  .
.
Böhm had work with Konrad Zuse and must have known about his language, Plankalkül. The language also has a APL feel to it (but without the vector operations).
Böhm’s language does not have a name, his thesis is really about translating mathematical expressions to machine code; the expressions are organised by what we today call basic blocks (Böhm calls them groups). The compiler for the unnamed language (along with a loader) is written in itself; a Java implementation is being worked on.
Böhm’s work is discussed in Donald Knuth’s early development of programming languages, but there is nothing like reading the actual work (if only in translation) to get a feel for it.
Update (3 days later): Correspondence with Donald Knuth.
Update (3 days later): A January 1949 memo from Haskell Curry (he of Curry fame and more recently of Haskell association) also uses the term organ. Might we claim, based on two observations on different continents, that it was in general use?
The shadow of the input distribution
Two things need to occur for a user to experience a fault in a program:
- a fault has to exist in the code,
- the user has to provide input that causes program execution to include the faulty code in a way that exhibits the incorrect behavior.
Data on the distribution of user input values is extremely rare, and we are left having to look for the shadows that the input distribution creates.
Csmith is a well-known tool for generating random C source code. I spotted an interesting plot in a compiler fuzzing paper and Yang Chen kindly sent me a copy of the data. In compiler fuzzing, source code is automatically generated and fed to the compiler, various techniques are used to figure out when the compiler gets things wrong.
The plot below is a count of the number of times each fault in gcc has been triggered (code+data). Multiple occurrences of the same fault are experienced because the necessary input values occur multiple times in the generated source code (usually in different files).
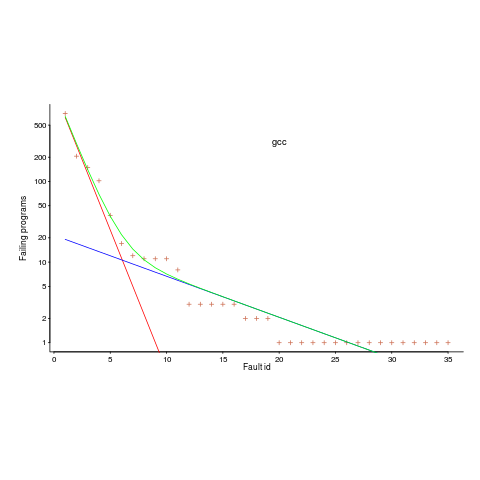
The green line is a fitted regression model, it’s a bi-exponential, i.e., the sum of two exponentials (the straight lines in red and blue).
The obvious explanation for this bi-exponential behavior (explanations invented after seeing the data can have the flavor of just-so stories, which is patently not true here 🙂 is that one exponential is driven by the presence of faults in the code and the other exponential is driven by the way in which Csmith meanders over the possible C source.
So, which exponential is generated by the faults and which by Csmith? I’m still trying to figure this out; suggestions welcome, along with alternative explanations.
Is the same pattern seen in duplicates of user reported faults? It does in the small amount of data I have; more data welcome.
Christmas books for 2017
Some suggestions for books this Christmas. As always, the timing of books I suggest is based on when they reach the top of my books-to-read pile, not when they were published.
“Life ascending: The ten great inventions of evolution” by Nick Lane. The latest thinking (as of 2010) on the major events in the evolution of life. Full of technical detail, very readable, and full of surprises (at least for me).
“How buildings learn” by Stewart Brand. Yes, I’m very late on this one. So building are just like software, people want to change them in ways not planned by their builders, they get put to all kinds of unexpected uses, some of them cannot keep up and get thrown away and rebuilt, while others age gracefully.
“Dead Man Working” by Cederström and Fleming is short and to the point (having an impact on me earlier in the year), while “No-Collar: The humane workplace and its hidden costs” by Andrew Ross is longer (first half is general, second a specific instance involving one company). Both have a coherent view work in the knowledge economy.
If you are into technical books on the knowledge economy, have a look at “Capitalism without capital” by Haskel and Westlake (the second half meanders off, covering alleged social consequences), and “Antitrust law in the new economy” by Mark R. Patterson (existing antitrust thinking is having a very hard time grappling with knowledge-based companies).
If you are into linguistics, then “Constraints on numerical expressions” by Chris Cummins (his PhD thesis is free) provides insight into implicit assumptions contained within numerical expressions (of the human conversation kind). A must read for anybody interested in automated fact checking.
ISO/IEC JTC 1/SC 42 Artificial intelligence
What has been preventing Artificial Intelligence being a success? Yes, you guessed it, until now ISO has not had an SC (Standards’ Committee) dealing with AI. Well, the votes are in and JTC 1/SC 42 Artificial intelligence is go.
Countries pay ISO to be members of an SC and the tax payers of: Austria, Canada, Finland, Germany, Ireland, Switzerland and United States have the pleasure of being founding member countries of SC42.
What standards/technical-reports are those attending SC42 meetings going to working on?
The two document titles I have seen so far are: “Artificial Intelligence Concepts and Terminology” and “Framework for Artificial Intelligence (AI) Systems Using Machine Learning (ML)”.
I hope the terminology document arrives in plenty of time, before the machines take over. The ISO Standard for Year 2000 terminology arrived in December 1999 (there was a flurry of emails desperately trying to row-back on this document).
Want to join up? Wael William Diab is the chairperson.
Recent Comments