Applied Software Measurement: shame about the made up numbers
“Applied Software Measurement” by Capers Jones (no relation) is widely cited, but I find it a very frustrating book; while the text is full of useful commentary the numbers in the tables are mostly made up or estimated from other numbers (some of which may be actual measurements).
This book’s many tables of numbers will catch the attention of anyone searching for software engineering data (which until recently was very hard to find). However, closer inspection of the numbers suggests that the real purpose of the empirical looking tables is to serve as eye-candy to impress casual readers.
Let’s take as an example the analysis of multiple implementations, in different languages, of software implementing telephone switching system functionality. The numbers are from the third edition of the book (the one I have; code+data, separate paper discussing the numbers).
Below are the numbers from Table 2-7: Function Point and Source Code Sizes for 10 Versions of the Same Project.
All those 1,500’s are a bit suspicious; the second paragraph under the table says “… the original sizes ranged from about 1,300 to 1,750 …”. Why has a gratuitous 1.5% error been introduced?
Where did the values for language level come from? I once wrote the semantics phase of a CHILL compiler in Pascal and would have put CHILL’s language level on a par with Ada83. Objective C at 11 is surely a joke. Language level is a number, so obviously we can take its average.
This table looks like it has one column of actual data. Oh, five pages before the table appears we are told that the Ada95 and Objective C results were modeled, i.e., made up. So there are really only eight real implementations, not ten.
Language Function pts Language level LOC/Func. Pt. Size in LOC Assembly 1,500 1 250 375,000 C 1,500 3 127 190,500 CHILL 1,500 3 105 157,500 PASCAL 1,500 4 91 136,500 PL/I 1,500 4 80 120,000 Ada83 1,500 5 71 106,500 C++ 1,500 6 55 82,500 Ada95 1,500 7 49 73,500 Objective C 1,500 11 29 43,500 Smalltalk 1,500 15 21 31,500 Average 1,500 6 88 131,700 |
Moving on to Table 2-6, see below: “Staff Months of Effort for 10 Versions of the Same Software Project”
The use of two decimal places of accuracy is an obvious red flag for wanting to impress via appearance of accuracy.
Is the requirements effort based on one known value, or is it estimated? Why the jump in design time when we get to C++? Does management time really have such a strong dependency on language used?
Language Require.. Design Code Test Document Management TOTAL Effort Assembly 13.64 60.00 300.00 277.78 40.54 89.95 781.91 C 13.64 60.00 152.40 141.11 40.54 53.00 460.69 CHILL 13.64 60.00 116.67 116.67 40.54 45.18 392.69 PASCAL 13.64 60.00 101.11 101.11 40.54 41.13 357.53 PL/I 13.64 60.00 88.89 88.89 40.54 37.95 329.91 Ada83 13.64 60.00 76.07 78.89 40.54 34.99 304.13 C++ 13.64 68.18 66.00 71.74 40.54 33.81 293.91 Ada95 13.64 68.18 52.50 63.91 40.54 31.04 269.81 Objective C 13.64 68.18 31.07 37.83 40.54 24.86 216.12 Smalltalk 13.64 68.18 22.50 27.39 40.54 22.39 194.64 |
The above table makes more sense when LOC is plotted against Total Effort (in man months), see below:
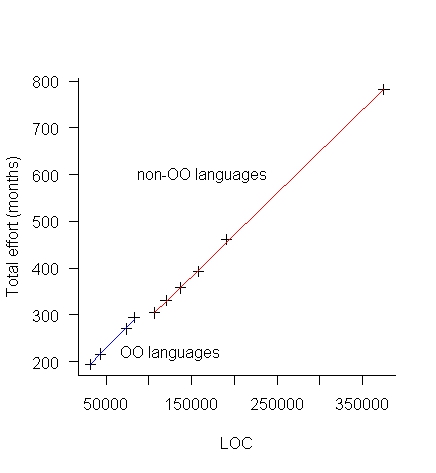
The blue line is for the object oriented languages (i.e., the last four rows of the table) and the red line everything else. Those two straight lines fit the data so well; I think that Total Effort was calculated from LOC and various rules of thumb used to create percentages for requirements, design, code, test, documentation and management.
There is no new data in the above table, it was all calculated from LOC and informed arm waving.
Table 2-9 and Table 2-11 list Total Effort (which has been estimated from LOC) and columns of values created by dividing or multiplying this by other estimated values.
Table 2-12, see below: “Defect Potentials for 10 Versions of the Same Software Project”
What is a Defect Potentials?
Again, a sudden jump in the design numbers at C++.
Language Require.. Design Code Document Bad Fix TOTAL Defects Assembly 1,500 1,875 7,500 900 1,060 12,835 C 1,500 1,875 3,810 900 728 8,813 CHILL 1,500 1,875 3,150 900 668 8,093 PASCAL 1,500 1,875 2,730 900 630 7,635 PL/I 1,500 1,875 2,400 900 601 7,276 Ada83 1,500 1,875 2,130 900 576 6,981 C++ 1,500 2,025 1,650 900 547 6,622 Ada95 1,500 2,025 1,470 900 531 6,426 Objective C 1,500 2,025 870 900 477 5,772 Smalltalk 1,500 2,025 630 900 455 5,510 |
Plotting total defects against LOC (below) suggests that “Defect Potentials” is a number calculated from LOC, i.e., no connection with actual defects found.
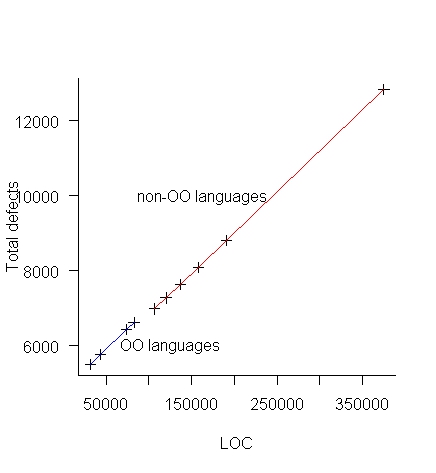
Table 2-13 lists Total Defects (which has been estimated from LOC) and columns of values created by dividing or multiplying this by other estimated values.
So the book contains six impressive looking tables whose numbers have been calculated in one way or another from lines of code. A very good description of the many other tables in the book.
Recent Comments