Word length lexical decision data
Well chosen identifier names can reduce the effort needed to understand the code containing them, compared to badly chosen identifiers.
An identifier might have a name that creates a semantic association in the mind of the reader about the role of the variable within a function definition (e.g., outer_counter) or an association with the information contained in the variable (e.g., max_fruit).
Code is not always read like prose text, developers might quickly scan through the source looking for something. In this case short identifier names are best because it reduces the number of characters that need to be scanned.
If you want to make life difficult for anyone who has to read your code, add a visually boring common prefix to every identifier, e.g., uacc. Readers start looking up a word in memory based in the first few characters while they process the remaining characters in a word, and eye tracking studies have found that that character sequence information is used to plan eye saccades (where to move the eyes next). A short bland sequence can really throw a spanner in the works of our over-learned reading skills.
I once researched a detailed analysis of the issues involved in a cost/benefit analysis of identifier selection. The good news is that I think I covered everything, the bad news is that the various kinds of data on human character sequence usage needed to perform the analysis was/is not available.
Today I got my hands on lots of performance data on the affect of word length on visual word recognition; thanks to Boris New (code and data)
The plot below shows the mean response time of 819 subjects performing a lexical decision task (respond yes/no on whether a character sequence is a word or nonword); each subject was tested on a subset of around 3,000 out of 33,608 words.
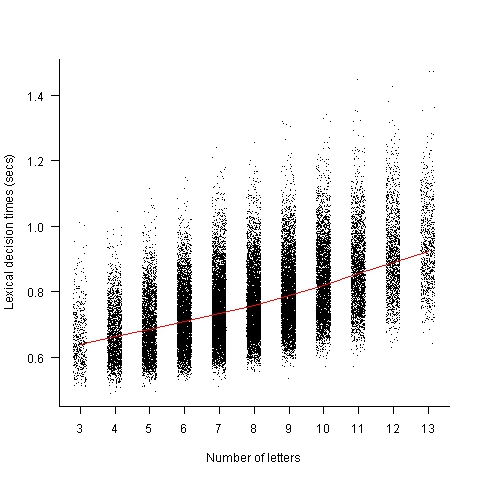
Note, this data is for single words. There are bound to be all sorts of interaction effects when two words/nonwords occur together in an identifier, e.g., semantic priming.
Word length is only one of several factors that have been found to effect people’s performance in processing words; others include the word frequency effect and age of acquisition (when the word was learned, which is correlated with word frequency).
Have fun with this.
Recent Comments