Extracting the original data from a heatmap image
The paper Analysis of the Linux Kernel Evolution Using Code Clone Coverage analysed 136 versions of Linux (from 1.0 to 2.6.18.3) and calculated the amount of source code that was shared, going forward, between each pair of these versions. When I saw the heatmap at the end of the paper (see below) I knew it had to appear in my book. The paper was published in 2007 and I knew from experience that the probability of seven year old data still being available was small, but looked so interesting I had to try. I emailed the authors (Simone Livieri, Yoshiki Higo, Makoto Matsushita and Katsuro Inoue) and received a reply from Makoto Matsushita saying that he had searched for the data and had been able to find the original images created for the paper, which he kindly sent me.
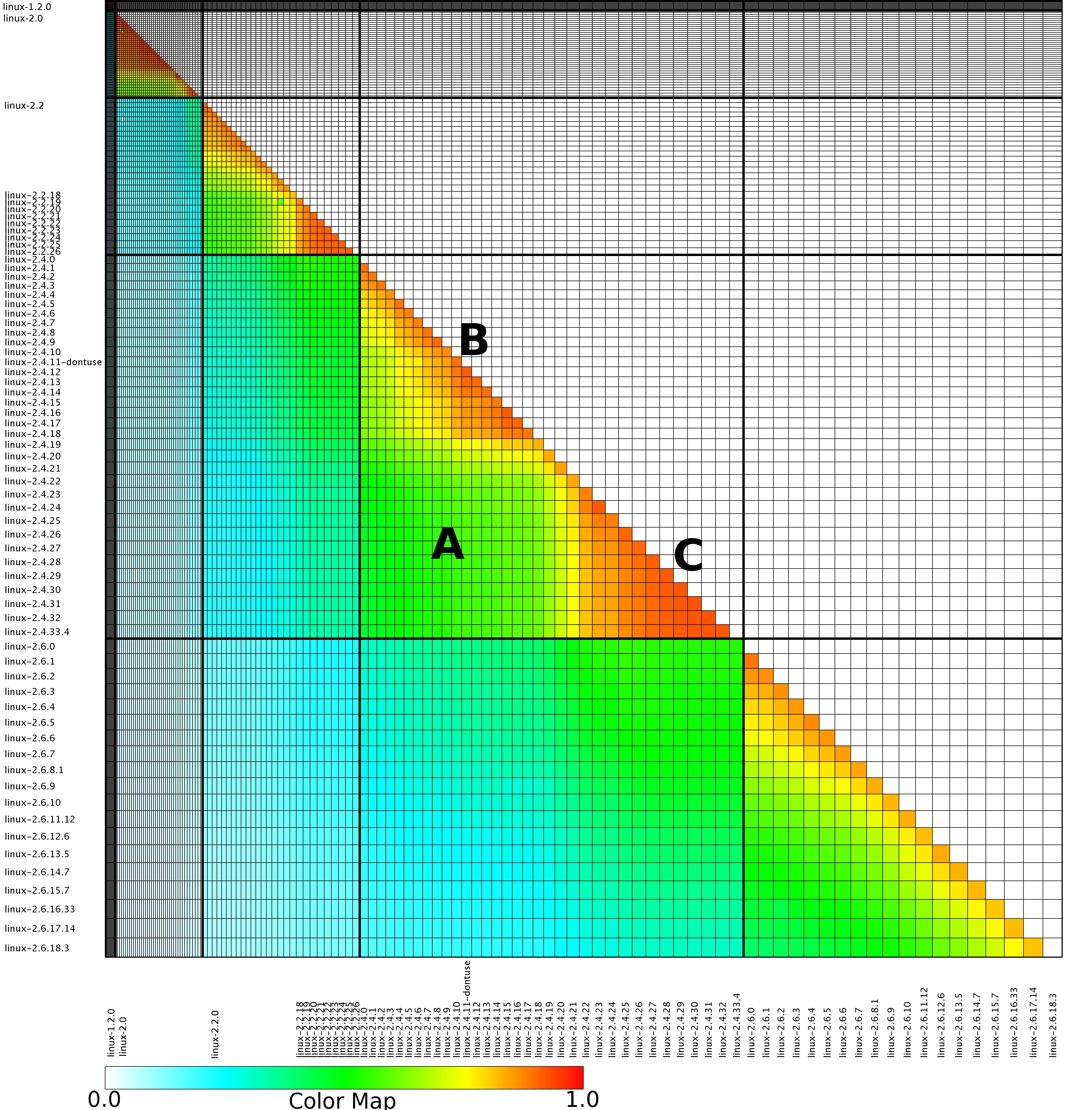
I was confident that I could reverse engineer the original values from the png image and that is what I have just done (I have previously reverse engineered the points in a pdf plot by interpreting the pdf commands to figure out relative page locations).
The idea I had was to find the x/y coordinates of the edge of the staircase running from top left to bottom right. Those black lines appear to complicate things, but the RGB representation of black follows the same pattern as white, i.e., all three components are equal (0 for black and 1 for white). All I had to do was locate the first pixel containing an RGB value whose three components had at least one different value, which proved to be remarkably easy to do using R’s vector operations.
After reducing duplicate sequences to a single item I now had the x/y coordinates of the colored rectangle for each version pair; extracting an RGB value for each pair of Linux releases was one R statement. Now I needed to map RGB values to the zero to one scale denoting the amount of shared Linux source. The color scale under the heatmap contains the information needed and with some trial and error I isolated a vector of RGB pixels from this scale. Passing the offset of each RGB value on this scale to mapvalues (in the plyr package) converted the extracted RGB values.
The extracted array has 130 rows/columns, which means information on 5 versions has been lost (no history is given for the last version). At the moment I am not too bothered, most of the data has been extracted.
Here is the result of calling the R function readPNG (from the png package) to read the original file, mapping the created array of RGB values to amount of Linux source in each version pair and calling the function image to display this array (I have gone for maximum color impact; the code has no for loops):
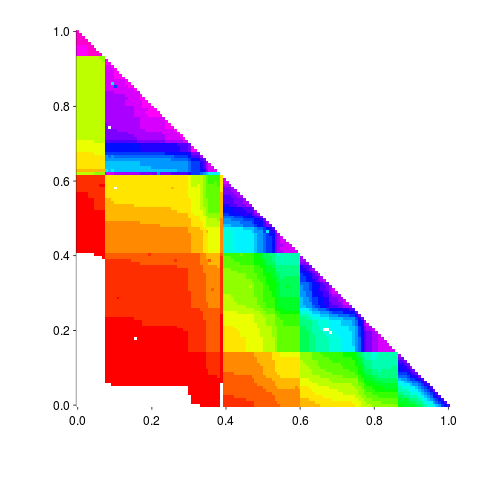
The original varied the width of the staircase, perhaps by some measure of the amount of source code. I have not done that.
Its suspicious that the letter A is not visible in some form. Its embedded in the original data and I would have expected a couple of hits on that black outline.
The above overview has not bored the reader with my stupidities that occurred along the way.
If you improve the code to handle other heatmap data extraction problems, please share the code.
Hi Derek, thank you for sharing your idea and code!
I noticed that the heat plot has several red and orange mixed blocks on the diagonal which indicate the highly correlated subjects. I’m wondering how did you make this plot. Did you sort the data in advance such that it can put the related subjects together?
@Meiling
The code that extracts the data and prints the image can be downloaded from a link in the article (I did no sorting).