How many ways of programming the same specification?
How many different ways are there of writing a program to implement a given specification? Non-trivial specifications probably have an enormous number of possible programming solutions. What about really simple specifications, say something based on the 3n+1 problem (write a programs that takes a list of integers and outputs their ‘3n+1’ length; ‘3n+1’ length algorithm: for integer  , if is even divide it by
, if is even divide it by  and assign the result to , otherwise is odd, multiply it by
and assign the result to , otherwise is odd, multiply it by  and add
and add  to give the new value of ; repeat the process, counting the number of iterations until reaches )?.
to give the new value of ; repeat the process, counting the number of iterations until reaches )?.
I can think of a dozen or so (slightly) different ways that I might write a program to solve this problem. If I really had to I could probably come up with a few hundred different solutions, but I think the source code of these programs would not look like something I would normally write. If I was to run a competition how many different answers might I get? If you twisted my arm I might have said 500. What do you think?
Meine van der Meulen studied the N-version programing for his PhD thesis (N groups independently write a program to the same specification, compare the output of the N programs and select the ‘best’ answer; cannot find a copy of the thesis online). This was empirical work and van der Meulen posted the above 3n+1 problem to a programming competition website and used the 95,497 submitted solutions for his analysis; he also kindly sent me a copy of the solutions (11,674 solutions were written in Pascal, the rest were in C).
Not all the solutions correctly solve the problem. I ignored this ‘detail’. There are also many duplicates (as in identical source code).
I am interested in differently coded solutions. I defined different as the sequence of operators/punctuators making up the program being different (or at least having a different MD5 checksum), so identifiers and comments are ignored. Should permutations in the order of independent adjacent statements really be counted as different? For the sack of keeping my life simple they current are. This definition of differently coded reduces the original 63,823 C programs down to 6,301. Wow, how are 6k+ different programs possible?
The original specification did not mention performance, but lots of developers did all sorts of weird and wonderful stuff to improve runtime performance. The most common optimization technique used (apart from some inventive ways of checking for odd/even) was to cache previous answers along with the solution for all the intermediate steps that were passed through on the way to 1 (the path from the starting value to 1 is very erratic and sometimes goes through values greater than the starting value) and check this cache to see whether it contains the current value of.
A common measure of program size is lines of code. What is the size distribution, in LOC, for these 6,301 programs? One program has been labeled an outlier and excluded from the analysis (most of its 8,345 lines were taken up with initializing a data structure with precomputed solutions).
The following plots lines of code against the number of programs containing that many lines (download code and data).
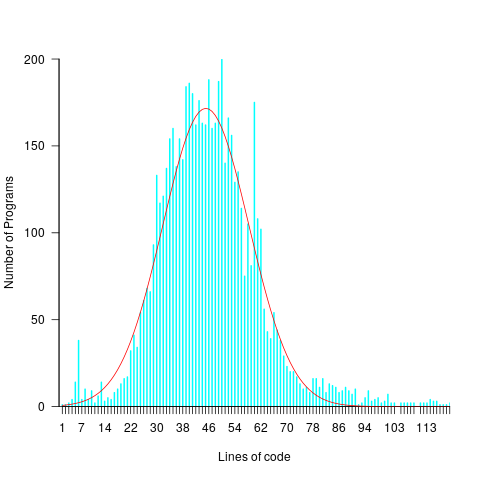
The mean program length is 46.3 lines, standard deviations 15.4. The red curve is a Normal distribution whose mean/sd has been tweaked to give a better visual fit (a Shapiro-Wilk test dispels any hope tht the distribution might be Normal). There is no reason to think that the data will be fitted by any known distribution and I’m not going to overfit on one data-point. If pushed I will wave my arms and describe the distribution as Normalish with added spikes and a fat right tail.
That spike around 60 lines is interesting. Is this group of solutions all doing the same thing but with different statement orderings? I have previously written about how gcc/llvm do a good job of turning the core of the algorithm into the same machine code. Perhaps a future version of these compilers will be able to tell us whether the programs clumping around 60 LOC are doing the same thing.
So how many different versions did the programmes reduce to when looking at the asm or LLVM listings? Would be interesting to compare this number between optimised and unoptimised compiles.
How was the input provided in van der Meulen’s specification? By I/O, or argv? Most of the differences in implementations would have been in handling the input if the former.
@Magnus
I would not be surprised if a few of the programs that differed at the source level were the same at the instruction sequence level. Any output from the
-Soption would need a quite a bit of post processing to remove the spurious noise.I/O was remarkably similar (i.e., use of
scanf,feof), common differences included how the code was broken up into functions, use offor/whileand#defineing various things.