Archive
Dead trees have been replaced by a paywall
Every now and again I see a reference to that looks like an interesting paper that was published before the Internet age (i.e., pre last 90’s and not available for free download). I keep a list of such references and when I am near a university with a good library I stop off to look them up; unless there is an urgent need this is very much a background task and before last week my last such visit was over three years ago.
Last week I dropped by Reading University, where I sourced much of the non-Internet available papers for my last book. The picture below illustrates what I found, periodicals are being removed to make way for desktop space, so students can sit typing away on keyboards.

I imagine the librarian is under pressure to maximise the efficient use of his large building and having row upon row of journals, many older than most of the students, just sitting there waiting for somebody like me wanting to look at perhaps a dozen or so of them cannot be said to be that efficient.
Everything is going digital, the library catalog was full of references to where journals could be found online. The problem is that the digital content is licensed to the University and only available to members of the University (e.g., students and lecturers). Without a logon id the journals are unavailable to non-academic users. Reading are continuing their open policy to external users by offering guest accounts (“where licence conditions permit”, I will find out what is available on my next visit).
Those readers who don’t have much interaction with the academic world may not be aware of the very high rates many publishers charge for access to published papers (that are provided to them free by academics) or the large profits made by these publishers.
Academics are starting to react against the high cost of journal subscription; I’m please to see that a boycott is gathering steam.
Boycotts are very well meaning, but I suspect that most academics will continue to keep their head down and go with existing practice (young academics need to get papers published in established to move up in their world).
We the tax payers are funding the research that discovers the information needed to write a paper and paying the salaries of academics to write the papers. Why are we the tax payers providing money to university libraries to subscribe to journals whose contents we have paid to create? If the research is tax payer funded we should not have to pay to see the results.
How do we remove the paywall that currently surrounds much published research? As I see it the simplest solution is to stop providing the funding that university libraries use to pay for journal subscriptions. Yes this will cause disruption, but the incentives are for most academics to continue with the current system and or course no company is ever willing to give up on a cash cow.
What can you do? If you are in the UK you can write to your MP to make him/her aware of your views. If readers have any other ideas please make use of the comments to tell others.
Prioritizing project stakeholders using social network metrics
Identifying project stakeholders and their requirements is a very important factor in the success of any project. Existing techniques tend to be very ad-hoc. In her PhD thesis Soo Ling Lim came up with a very interesting solution using social network analysis and what is more made her raw data available for download 🙂
I have analysed some of Soo Ling’s data below as another draft section from my book Empirical software engineering with R. As always comments and pointers to more data welcome. R code and data here.
A more detailed discussion and analysis is available in Soo Ling Lim’s thesis, which is very readable. Thanks to Soo Ling for answering my questions about her work.
Stakeholder roles and individuals
A stakeholder is a person who has an interest in what an application does. In a well organised development project the influential stakeholders are consulted before any contracts or budgets are agreed. Failure to identify the important stakeholders can result in missing or poorly prioritized requirements which can have a significant impact on the successful outcome of a project.
While many people might consider themselves to be stakeholders whose opinions should be considered, in practice the following groups are the most likely to have their opinions taken into account:
- people having an influence on project funding,
- customers, i.e., those people who are willing pay to use or obtain a copy of the application,
- domain experts, i.e., people with experience in the subject area who might suggest better ways to do something or problems to try and avoid,
- people who have influence over the success or failure over the actual implementation effort, e.g., software developers and business policy makers,
- end-users of the application (who on large projects are often far removed from those paying for it).
In the case of volunteer open source projects the only people having any influence are those willing to do the work. On open source projects made up of paid contributors and volunteers the situation is likely to be complicated.
Individuals have influence via the roles they have within the domain addressed by an application. For instance, the specification of a security card access system is of interest to the role of ‘being in charge of the library’ because the person holding that role needs to control access to various facilities provided within different parts of the library, while the role of ‘student representative’ might be interested in the privacy aspects of the information held by the application and the role of ‘criminal’ has an interest in how easy it is to circumvent the access control measures.
If an application is used by large numbers of people there are likely to be many stakeholders and roles, identifying all these and prioritizing them has, from experience, been found to be time consuming and difficult. Once stakeholders have been identified they then need to be persuaded to invest time learning about the proposed application and to provide their own views.
The RALIC study
A study by Lim <book Lim_10> was based on a University College London (UCL) project to combine different access control mechanisms into one, such as access to the library and fitness centre. The Replacement Access, Library and ID Card (RALIC) project had more than 60 stakeholders and 30,000 users, and has been deployed at UCL since 2007, two years before the study started. Lim created the StakeNet project with the aim of to identifying and prioritising stakeholders.
Because the RALIC project had been completed Lim had access to complete project documentation from start to finish. This documentation, along with interviews of those involved, were used to create what Lim called the Ground truth of project stakeholder role priority, stakeholder identification (85 people) and their rank within a role, requirements and their relative priorities; to quote Lim ‘The ground truth is the complete and prioritised list of stakeholders and requirements for the project obtained by analysing the stakeholders and requirements from the start of the project until after the system is deployed.’
The term salience is used to denote the level of a stakeholder’s influence.
Data
The data consists of three stakeholder related lists created as follows (all names have been made anonymous):
- the Ground truth list: derived from existing RALIC documentation. The following is an extract from this list (individual are ranked within each stakeholder role):
Role Rank, Stakeholder Role, Stakeholder Rank, Stakeholder 1, Security and Access Systems, 1, Mike Dawson 1, Security and Access Systems, 2, Jason Ortiz 1, Security and Access Systems, 3, Nick Kyle 1, Security and Access Systems, 4, Paul Haywood 2, Estates and Facilities Division,1, Richard Fuller
- the Open list: starting from an initial list of 22 names and 28 stakeholder roles, four iterations of [Snowball sampling] resulted in a total of 61 responses containing 127 stakeholder names+priorities and 70 stakeholder roles,
- the Closed list: a list of 50 possible stakeholders was created from the RALIC project documentation plus names of other UCL staff added as noise. The people on this list were asked to indicated which of those names on the list they considered to be stakeholders and to assign them a salience between 1 and 10, they were also given the option to suggest names of possible stakeholders. This process generated a list containing 76 stakeholders names+priorities and 39 stakeholder roles.
The following is an extract from the last two stakeholder lists:
stakeholder stakeholder role salience David Ainsley Ian More 1 David Ainsley Rachna Kaplan 6 David Ainsley Kathleen Niche 4 David Ainsley Art Waller 1 David Carne Mark Wesley 4 David Carne Lis Hands 4 David Carne Vincent Matthew 4 Keith Lyon Michael Wondor 1 Keith Lyon Marilyn Gallo 1 Kerstin Michel Greg Beech 1 Kerstin Michel Mike Dawson 6 |
Is the data believable?
The data was gathered after the project was completed and as such it is likely to contain some degree of hindsight bias.
The data cleaning process is described in detail by Lim and looks to be thorough.
Predictions made in advance
Lim drew a parallel between the stakeholder prioritisation problem and the various techniques used to rank the nodes in social network analysis, e.g., the Page Rank algorithm. The hypothesis is that there is a strong correlation exists between the rank ordering of stakeholder roles in the Grounded truth list and the rank of stakeholder roles calculated using various social network metrics.
Applicable techniques
How might a list of people and the salience they assign to other people be converted to a single salience for each person? Lim proposed that social network metrics be used. A variety of techniques for calculating social network node centrality metrics have been proposed and some of these, including most used by Lim, are calculated in the following analysis.
Lim compared the Grounded truth ranking of stakeholder roles against the stakeholder role ranking created using the following network metrics:
- betweenness centrality: for a given node it is a count of the number of shortest paths from all nodes in a graph to all other nodes in that graph that pass through the given node; the value is sometimes normalised,
- closeness centrality: for a given node closeness is the inverse of farness, which is the sum of that node’s distances to all other nodes in the graph; the value is sometimes normalised,
- degree centrality: in-degree centrality is a count of the number of edges referring to a node, out-degree centrality is the number of edges that a node refers to; the value is sometimes normalised,
- load centrality: this is a variant of betweenness centrality based on the fraction of shortest paths through a given node. Support for load centrality is not available in the
igraphpackage and so is not used here, this functionality is available in thestatnetpackage, - pagerank: the famous algorithm proposed by Page and Brin <book Page_98> for ranking web pages.
Eigenvector centrality is another commonly used network metric and is included in this analysis.
Results
The igraph package includes functions for computing many of the common social network metrics. Reading data and generating a graph (the mathematical term for a social network) from it is particularly easy, in this case the graph.data.frame function is used to create a representation of its graph from the contents of a file read by read.csv.
The figure below plots Pagerank values for each node in the network created from the Open and Closed stakeholder salience ratings (Pagerank was chosen for this example because it had one of the strongest correlations with the Ground truth ranking). There is an obvious difference in the shape of the curves: the Open saliences (green) is fitted by the equation  (black line), while the Closed saliences (blue) is piecewise fitted by
(black line), while the Closed saliences (blue) is piecewise fitted by  and
and  (red lines).
(red lines).
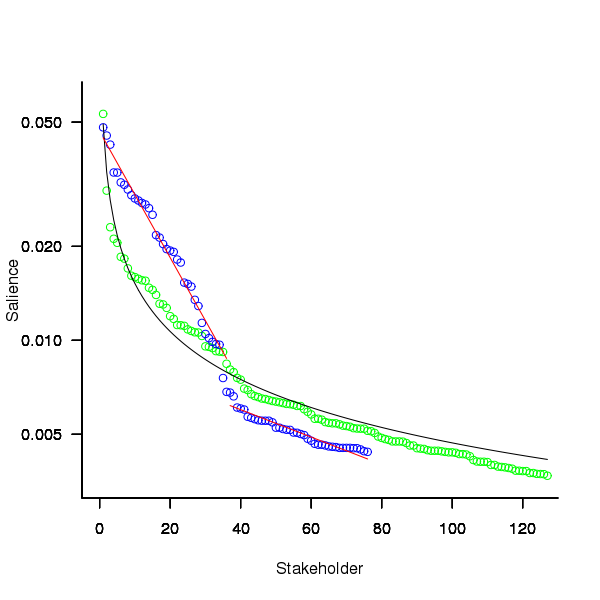
Figure 1. Plot of Pagerank of the stakeholder nodes in the network created from the Open (green) and Closed (blue) stakeholder responses (values for each have been sorted). See text for details of fitted curves.
To compare the ability of network centrality metrics to produce usable orderings of stakeholder roles a comparison has to be made against the Ground truth. The information in the Ground truth is a ranked list of stakeholder roles, not numeric values. The Stakeholder/centrality metric pairs need to be mapped to a ranked list of stakeholder roles. This mapping is achieved by associating a stakeholder role with each stakeholder name (this association was collected by Lim during the interview process), sorting stakeholder role/names by decreasing centrality metric and then ranking roles based on their first occurrence in the sorted list (see rexample[stakeholder]).
The Ground truth contains stakeholder roles not filled by any of the stakeholders in the Open or Closed data set, and vice versa. Before calculating role ranking correlation by roles not in both lists were removed.
The table below lists the Pearson correlation between the Ground truth ranking of stakeholder roles and for the ranking produced from calculating various network metrics from the Closed and Open stakeholder salience questionnaire data (when applied to ranks the Pearson correlation coefficient is equivalent to the Spearman rank correlation coefficient).
| betweenness | closeness | degree in | degree out | eigenvector | pagerank | |
|---|---|---|---|---|---|---|
|
Open
|
0.63
|
0.46
|
0.54
|
0.52
|
0.62
|
0.60
|
|
Weighted Open
|
0.66
|
0.49
|
0.62
|
0.50
|
0.68
|
0.67
|
|
Closed
|
0.51
|
0.53
|
0.67
|
0.60
|
0.69
|
0.71
|
|
Weighted Closed
|
0.50
|
0.50
|
0.63
|
0.54
|
0.68
|
0.72
|
The Open/Closed correlation calculation is based on a linear ranking. However, plotting Stakeholder salience, as in the plot above, shows a nonlinear distribution, with the some stakeholders having a lot more salience than less others. A correlation coefficient calculated by weighting the rankings may be more realistic. The “weighted” rows in the above are the correlations calculated using a weight based on the equations fitted in the Pagerank plot above; there is not a lot of difference.
Discussion
Network metrics are very new and applications making use of them still do so via a process of trial and error. For instance, the Pagerank algorithm was found to provide a good starting point for ranking web pages and many refinements have subsequently been added to the web ranking algorithms used by search engines.
When attempting to assign a priority to stakeholder roles and the people that fill them various network metric provide different ways of interpreting information about relationships between stakeholders. Lim’s work has shown that some network metrics can be used to produce ranks similar to those actually used (at least for one project).
One major factor not included in the above analysis is the financial contribution that each stakeholder role makes towards the implementation cost. Presumably those roles contributing a large percentage will want to be treated as having a higher priority than those contributing a smaller percentage.
The social network metrics calculated for stakeholder roles were only used to generate a ranking so that a comparison could be made against the ranked list available in the Ground truth. A rank ordering is a linear relationship between stakeholders; in real life differences in priority given to roles and stakeholders may not be linear. Perhaps the actual calculated network metric values are a better (often nonlinear) measure of relative difference, only experience will tell.
Summary of findings
Building a successful application is a very hard problem and being successful at it is something of a black art. There is nothing to say that a different Ground truth stakeholder role ranking would have lead to the RALIC project being just as successful. The relatively good correlation between the Ground truth ranking and the ranking created using some of the network metrics provides some confidence that these metrics might be of practical use.
Given that information on stakeholders’ rating of other stakeholders can be obtained relatively cheaply (Lim built a web site to collect this kind of information <book Lim_11>), for any large project a social network analysis appears to be a cost effect way of gathering and organizing information.
Spreadsheet errors: open source or survival of the fittest
There is a bit of a kerfuffle going on in the economics world at the moment over spreadsheet errors and data cherry-picking in an influential paper about the current economic crisis. I don’t know anything about economics and will leave commentary on the data cherry-picking to others, but I can claim to know something about coding errors.
Stories of companies loosing lots of money because of small mistakes in a spreadsheet are fairly common, this problem is not rare or unimportant. Academic research on spreadsheets seems to be slowly gathering steam, with PhDs appearing every now and again. Industry appears to be more active, with a variety of companies offering tools aimed at finding faults in spreadsheets.
Based on my somewhat limited experience of helping people fix spreadsheet problems, I suspect that no amount of research or tool availability from industry will solve the real problem that faces spreadsheet users, which is that they don’t appreciate their own fallibility.
Back when software development first started, people were very surprised to discover the existence of software faults. As every new programmer discovers, computers are merciless and will punish the slightest coding mistake. A large part of becoming a professional developer involves learning how to structure development to deal with personal fallibility, plus developing a mental attitude capable of handling the constant reminder of personal fallibility that computers provide to anybody writing code to tell them what to do (something that deters some people from becoming developers).
It rarely enters the head’s of people who are sporadic authors of code or spreadsheets that they may be making subtle mistakes that can have a significant impact on the results produced. Getting somebody with this frame of mind to perform testing on what they have written is well-nigh on impossible.
In a research context one very practical solution to the code reliability issue is to insist that code or/and spreadsheets be made freely available. Only when the spreadsheet used to create the results in the paper linked to above was made available to others were the mistakes it contained uncovered.
In a commercial context it is down to survival of the fittest, those companies who do not keep their spreadsheet errors below a recoverable level die.
Never too experienced to make a basic mistake
I was one of the 170 or so people at the Data Science hackathon in London over the weekend. As always this was well run by Carlos and his team who kept us fed, watered and connected to the Internet.
One of the three challenges involved a dataset containing pairs of Twitter users, A and B, where one of the pair had been ranked, by a person, as more influential than the other (the data was provided by PeerIndex, an event sponsor). The dataset contained 22 attributes, 11 for each user of the pair, plus 0/1 to indicate who was most influential; there was a training dataset of 5.5K pairs to learn against and a test dataset to make predictions against. The data was not messy or even sparse, how hard could it be?
Talks had been organized for the morning and afternoon. While Microsoft (one of the event sponsors) told us about Azure and F#, I sat at the back trying out various machine learning packages. Yes, the technical evangelists told us, Linux as well as Windows instances were available in Azure, support was available for the usual big data languages (e.g., Python and R; the Microsoft people seemed to be much more familiar with Python) plus dot net (this was the first time I had heard the use of dot net proposed as a big data solution for the Cloud).
Some members of Team Outliers from previous hackathons (Jonny, Bob and me) formed a team and after the talks had finished the Microsoft people+partners sat at our table (probably because our age distribution was similar to theirs, i.e., at the opposite end of the range to most teams; some of the Microsoft people got very involved in trying to produce a solution to the visualization challenge).
Integrating F# with bigdata seems to involve providing an interface to R packages (this is done by interfacing to the packages installed on a local R installation) and getting the IDE to know about the names of columns contained in data that has been read. Since I think the world needs new general purpose programming languages as much as it needs holes in the head I won’t say any more.
When in challenge solving mode I was using cross-validation to check the models being built and scoring around 0.76 (AUC, the metric used by the organizers). Looking at the leader board later in the afternoon showed several teams scoring over 0.85, a big difference; what technique were they using to get such a big improvement?
A note: even when trained on data that uses 0/1 predictor values machine learners don’t produce models that return zero or one, many return values in the range 0..1 (some use other ranges) and the usual technique is treat all values greater than 0.5 as a 1 (or TRUE or ‘yes’, etc) and all other values as a 0 (or FALSE or ‘no’, etc). This (x > 0.5) test had to be done to cross validate models using the training data and I was using the same technique for the test data. With an hour to go in the 24 hour hackathon we found out (change from ‘I’ to ‘we’ to spread the mistake around) that the required test data output was a probability in the range 0..1, not just a 0/1 value; the example answer had this behavior and this requirement was explained in the bottom right of the submission page! How many times have I told others to carefully read the problem requirements? Thankfully everybody was tired and Jonny&Bob did not have the energy to throw me out of the window for leading them so badly astray.
Having AUC as the metric should have raised a red flag, this does not make much sense for a 0/1 answer; using AUC makes sense for PeerIndex because they will want to trade off recall/precision. Also, its a good idea to remove ones ego when asked the question: are lots of people doing something clever or are you doing something stupid?
While we are on the subject of doing the wrong thing, one of the top three teams gave an excellent example of why sales/marketing don’t like technical people talking to clients. Having just won a prize donated by Microsoft for an app using Azure, the team proceeded to give a demo and explain how they had done everything using Google services and made it appear within a browser frame as if it were hosted on Azure. A couple of us sitting at the back were debating whether Microsoft would jump in and disqualify them.
What did I learn that I did not already know this weekend? There are some R machine learning packages on CRAN that don’t include a predict function (there should be a research-only subsection on CRAN for packages like this) and some ranking algorithms need more than 6G of memory to process 5.5K pairs.
There seemed to be a lot more people using Python, compared to R. Perhaps having the sample solution in Python pushed the fence sitters that way. There also seemed to be more women present, but that may have been because there were more people at this event than previous ones and I am responding to absolute numbers rather than percentage.
Push hard on a problem here and it might just pop up over there
One thing I have noticed when reading other peoples’ R code is that their functions are often a lot longer than mine. Writing overly long functions is a common novice programmer mistake, but the code I am reading does not look like it is written by novices (based on the wide variety of base functions they are using, something a novice is unlikely to do, and by extrapolating my knowledge of novice behavior in other languages to R). I have a possible explanation for these longer functions, R users’ cultural belief that use of global variables is taboo.
Where did this belief originate? I think it can be traced back to the designers of R being paid up members of the functional programming movement of the early 80’s. This movement sought to mathematically prove programs correct but had to deal with the limitation that existing mathematical techniques were not really up to handling programs that contained states (e.g., variables that were assigned different values at different points in their execution). The solution was to invent a class of programming languages, functional languages, that did not provide any mechanisms for creating states (i.e., no global or local variables) and using such languages was touted as the solution to buggy code. The first half of the 80’s was full of computing PhD students implementing functional languages that had been designed by their supervisor, with the single application written by nearly all these languages being their own compiler.
Having to use a purely functional language to solve nontrivial problems proved to be mindbogglingly hard and support for local variables crept in and reading/writing files (which hold state) and of course global variables (but you must not use them because that would generate a side-effect; pointing to a use of a global variable in some postgrad’s code would result in agitated arm waving and references to a technique described in so-and-so’s paper which justified this particular use).
The functional world has moved on, or to be exact mathematical formalisms not exist that are capable of handling programs that have state. Modern users of functional languages don’t have any hangup about using global variables. The R community is something of a colonial outpost hanging on to views from a homeland of many years ago.
Isn’t the use of global variables recommended against in other languages? Yes and No. Many languages have different kinds of global variables, such as private and public (terms vary between languages); it is the use of public globals that may raise eyebrows, it may be ok to use them in certain ways but not others. The discussion in other languages revolves around higher level issues like information hiding and controlled access, ideas that R does not really have the language constructs to support (because R programs tend to be short there is rarely a need for such constructs).
Lets reformulate the question: “Is the use of global variables in R bad practice?”
The real question is: Given two programs, having identical external behavior, one that uses global variables and one that does not use global variables, which one will have the lowest economic cost? Economic cost here includes the time needed to figure out how to write the code and time to fix any bugs.
I am not aware of any empirical evidence, in any language, that answers this question (if you know of any please let me know). Any analysis of this question requires enumerating those problems where a solution involving a global variable might be thought to be worthwhile and comparing the global/nonglobal code; I know of a few snippets of such analysis in other languages.
Coming back to these long R functions, they often contain several for loops. Why are developers using for loops rather than the *ply functions? Is it because the *aply solution might require the use of a global variable, a cultural taboo that can be avoided by having everything in one function and using a for loop?
Next time somebody tells you that using global variables is bad practice you should ask for some evidence that backs that statement up.
I’m not saying that the use of global variables is good or bad, but that the issue is a complicated one. Enforcing a ‘no globals’ policy might just be moving the problem it was intended to solve to another place (inside long functions).
Recent Comments