Archive
More men than women are incompetent/very competent
Womens’ rights campaigners are always making a big fuss about the huge impact equal rights/sex discrimination laws have had on increasing the career opportunities for very capable women to break the ‘glass ceiling’. The very capable end of the ability scale has always been sparsely populated and any significant impact is more likely to be noticeable in the less capable bands of the scale.
When I started out working in software development, if there was a women working on a team the chances were that she would be towards the very competent end of the scale (male/female ratio back then was what, 10/1?). These days, based on my limited experience, women are less likely to be competent but still a lot less likely, than men, to be completely incompetent.
Based on my experience+talking to others it would appear that women are still underrepresented at the very competent/incompetent ends of the scale in software development. Why might this be (apart from being a sample size issue)? While the average value of male/female intelligence are the same (IQ tests are constructed to make them equal), the variance in IQ between the sexes is very different. The following is taken from Population sex differences in IQ at age 11: the Scottish mental survey 1932
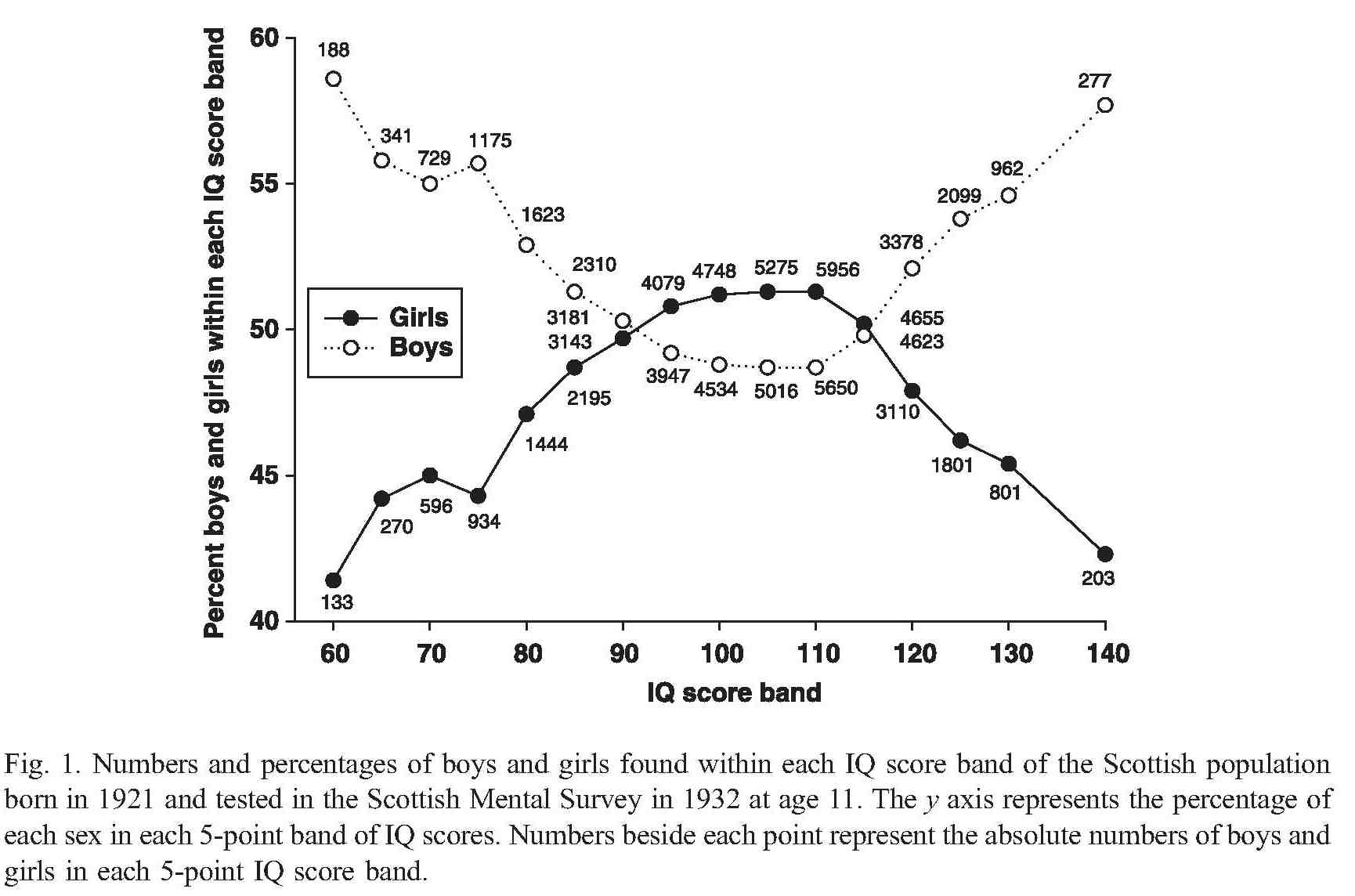
The above plot provides a possible explanation for the prevalence of men at the very competent/incompetent ends of the scale and suggests that women should outnumber men in the middle, competent, band.
In practice there are still far fewer women than men working in software engineering, so a comparison using absolute counts is not possible; good luck running a survey covering software developer competence.
If the above IQ distribution carries over to competencies then it seems to me that those seeking to attract more women into software engineering, and engineering in general, should be targeting the more populous middle competence band and not the high fliers. Companies make a big fuss about wanting high fliers but in practice are often willing to take on people who are likely to be competent if they are the safer choice (that guy who appeared rather unusual during the interview may turn out to be flop rather than a rock star).
R needs some bureaucracy
Writing a program in R is almost bureaucracy free: variables don’t need to be declared, the language does a reasonable job of guessing the type a value might need to be automatically be converted to, there is no need to create a function having a special name that gets called at program startup, the commonly used library functions are ready and waiting to be called and so on.
Not having a bureaucracy is all well and good when programs are small or short lived. Large programs need a bureaucracy to provide compartmentalization (most changes to X need to be prevented from having an impact outside of X, doing this without appropriate language support eventually burns out anybody juggling it all in their head) and long lived programs need a bureaucracy to provide version control (because R and its third-party libraries change over time).
Automatically installing a package from CRAN always fetches the latest version. This is all well and good during initial program development. But will the code still work in six months time? Perhaps the author of one of the packages used in the program submits a new version of that package to CRAN and this new version behaves slightly differently, breaking the previously working program. Once the problem is located the developer has either to update their code or manually install the older version of the package. Life would be easier if it was possible to specify the required package version number in the call to the library function.
Discovering that my code depends on a particular version of a CRAN package is an irritation. Discovering that two packages I use each have a dependency on different versions of the same package is a nightmare. Having to square this circle is known in the Microsoft Windows world as DLL hell.
There is a new paper out proposing a system of dependency versioning for package management. The author proposes adding a version parameter to the library function, plus lots of other potentially useful functionality.
Apart from changing the behavior of functions a program calls, what else can a package author do to break developer code? They can create new functions and variables. The following is some code that worked last week:
library("foo") # The function get_question is in this package library("bar") # The function give_answer_42 is in this package (the_question=get_question()) give_answer_42(the_question) |
between last week and today the author of package foo (or perhaps the author of one of the packages that foo has a dependency on) has added support for the function solve_problem_42 and it is this function that will now get called by this code (unless the ordering of the calls to library are switched). What developers need to be able to write is:
library("foo", import=c("the_question")) # The function get_question is in this package library("bar", import=c("give_answer_42")) # The function give_answer_42 is in this package (the_question=get_question()) give_answer_42(the_question) |
to stop this happening.
The import parameter enables developers to introduce some compartmentalization into my programs. Yes, R does have namespace management for packages, and I’m pleased to see that its use will be mandatory in R version 3.0.0, but this does not protect programs from functions the package author intends to export.
I’m not sure whether this import suggestion will connect with R users (who look very laissez faire to me), but I get very twitchy watching a call to library go off and install lots of other stuff and generate warnings about this and that being masked.
Verified compilers and soap powder advertising
There’s a new paper out claiming to be about a formally-verified C compiler, it even states a Theorem about its abilities! If this paper appeared as part of a Soap powder advert the Advertising Standards Authority would probably require clarification of the claims. What clarifications might appear in the small print tucked away at the bottom of the ad?
- C source code is not verified directly, it is first translated to the formal notations used by the verification system; the software that performs this translation is assumed to be correct.
- The CompCert system may successfully translate programs containing undefined behavior. Any proof statements made about such programs may not be valid.
- The support tools are assumed to be correct; primarily the Coq proof assistant, which is written in OCaml.
- The CompCert system makes decisions about implementation dependent behaviors and any proofs only apply in the context of these decisions.
- The CompCert system makes decisions about unspecified behaviors and any proofs only apply in the context of these decisions.
Some notes on the small print:
The C source translator used by CompCert rarely gets mentioned in any of the published papers; what was done to check its accuracy (I have previously discussed some options)? Presumably the developers who wrote it tried very hard to make sure they did a good job, just like the authors of f2c, a Fortran to C translator, did. Connecting f2c as a front-end of the CompCert system gives us a verified Fortran compiler! I think the f2c translator is much more likely to be correct than the CompCert C source translator, it has been used by a lot more people, processed a lot more source and maintained over a longer period.
When they encounter undefined behavior in source code production C compilers sometimes generate code that has very unexpected behavior. Using the CompCert system will not avoid unexpected behavior in these situations; CompCert simply washes its hands for this kind of code and says all bets are off.
Proving the support tools correct would simply move the assumption of correctness to a different set of tools. I am not aware of any major effort to test whether the Coq system behaves as intended, but have not read all the papers describing it (the list of reported faults is does not appear to be publicly available); bugs have been found in the OCaml implementation.
Like all compilers that generate code, CompCert has to make implementation dependent decisions and select one of the possible unspecified behaviors. The C-Semantics tool generates all unspecified behaviors, rather than just one.
The most worthwhile R coding guidelines I know
Since my post questioning whether native R usage exists (e.g., a common set of R coding patterns) several people have asked about coding/style guidelines for R. My approach to style/coding guidelines is economic, adhering to a guideline involves paying a cost now for some future benefit. Obviously to be worthwhile the benefit must be greater than the cost, there is also the issue of who pays the cost and who reaps the benefit (why would anybody pay the cost if somebody else reaps the benefit?). The following three topics are probably where the biggest benefits are to be had and only the third is specific to R (and given the state of my R knowledge may be wrong).
Comment your code. Investing 5-10 seconds per few lines of code now could save substantially more time at some future date. Effective commenting is a skill that has to be learned, start learning now. Think of commenting as sending a text message or tweet to the person you will be in 6 months time (i.e., the person who can hum the tune but has forgotten the details).
Consistently use variable names that mean something to you. This should be a sub 2-second decision that is probably going to save you no more than 5-10 seconds, but in many cases you reap the benefit soon after the investment, without having to wait many months. Names evoke associations in your mind, take advantage of this associative lookup to reduce the cognitive load of working with your code. Effective naming is a skill that has to be learned, start learning now. There are people who ignore the evidence that different people’s linguistic preferences and associations can be very different and insist that everybody adhere to one particular naming convention; ignore them.
Code organization and structure. Experience shows that there are ways of organizing and structuring +1,000 line programs that have a significant impact on the effort needed to actively work on the code, the more code there is the greater the impact. R programs tend to be short, say around 100 lines (I dare say much longer ones exist). Apart from recommending that code be broken up into separate functions, I cannot think of any organizational/structural issue that is worth recommending for 100 lines of code (if you don’t appreciate the advantage of using separate functions you need some hands on training, not words in a blog post).
Is that it, are there no other worthwhile recommendations? There might be, I just don’t have enough experience using R to know. Does anybody else have enough experience to know? I suspect not; where would they have gotten the information needed to do the cost/benefit analysis? Even in the rare case where a detailed analysis is made for a language the results are rather thin on the ground and somewhat inconclusive.
What is the reason behind those R style guides/coding guideline documents that have been written? The following are some possibilities:
and no, I don’t have any empirical data to backup my guidelines 🙁