Archive
Distribution of uptimes for high-performance computing systems
Computers break down every now and again and this is a serious problem when an application needs runs on thousands of individual computers (nodes) plugged together; lots more hardware creates lots more opportunity for a failure that renders any subsequent calculations by working nodes possible wrong. The solution is checkpointing; saving the state of each node every now and again, and rolling back to that point when a failure occurs. Picking the optimal interval between checkpoints requires knowledge the distribution of node uptimes, what is it?
Short answer: Node uptimes have a negative binomial distribution, or at least five systems at the Los Alamos National Laboratory do.
The longer answer is below as another draft section from my book Empirical software engineering with R. As always comments and pointers to more data welcome. R code and data here.
Distribution of uptimes for high-performance computing systems
Today’s high-performance computing systems are created by connecting together lots of cpus. There is a hierarchy to the connection in that many cpus may populate a single board, several boards may be fitted into a rack unit, several rack units into a cabinet, lots of cabinets lined up in a row within a room and more than one room in a facility. A common operating unit is the node, effectively a computer on which an operating system is running (the actual hardware involved may be a single or multi processor cpu). A high-performance system is built from thousands of nodes and an application program may run on compute nodes from more than one facility.
With so many components, failures occur on a regular basis and long running applications need to recover from such failures if they are to stand a reasonable chance of ever completing.
Applications running on the systems installed at the Los Alamos National Laboratory create checkpoints at regular intervals, writing data needed to do a full restore to storage. When a failure occurs an application is restarted from its most recent checkpoint, one node failure causes all nodes to be rolled back to their most recent checkpoint (all nodes create their checkpoints at the same time).
A tradeoff has to be made between frequently creating checkpoints, which takes resources away from completing execution of the application but reduces the amount of lost calculation, and infrequent checkpoints, which diverts less resources but incurs greater losses when a fault occurs. Calculating the optimum checkpoint interval requires knowing the distribution of node uptimes and the following analysis attempts to find this distribution.
Data
The data comes from 23 different systems installed at the Los Alamos National Laboratory (LANL) between 1996 and 2005. The total failure count for most of the systems is of the order of a few hundred; there are five systems (systems 2, 16, 18, 19 and 20) that each have several thousand failures and these are the ones analysed here.
The data consists of failure records for every node in a system. A failure record includes information such as system id, node number, failure time, restored to service time, various hardware characteristics and possible root causes for the failure. Schroeder and Gibson <book Schroeder_06> performed the first analysis of the dataset and provide more background details.
Is the data believable?
Failure records are created by operations staff when they are notified by the automated monitoring system that a failure has been detected. Given that several people are involved in the process <book LANL_data_06> it seems unlikely that failures will go unreported.
Some of the failure reports have start times before the given node was returned into service from the previous failure; across the five systems this varied between 0.4% and 2.5%. It is possible that these overlapping failures are caused by an incorrectly attempt to fix the first failure, or perhaps they are data entry errors. This error rate is comparable with human error rates for low stress/non-critical work
The failure reports do not include any information about the application software running on the node when it failed; the majority of the programs executed are large-scale scientific simulations, such as simulations of nuclear stockpile stability. Thus it is not possible to accurately calculate the node MTBF for an executing application. LANL say <book LANL_data_06> that the applications “… perform long periods (often months) of CPU computation, interrupted every few hours by a few minutes of I/O for check-pointing.”
Predictions made in advance
The purpose of this analysis is to find the distribution that best fits the node uptime data, i.e., the time interval between failures of the same node.
Your author is not aware of any empirically based theory that predicts the uptime of high performance computing systems. The Poisson and exponential distributions are both frequently encountered in the analysis of hardware failures and it is always comforting to fit in with existing expectations.
Applicable techniques
A [Cullen and Frey test] matches a dataset’s skew and kurtosis against known distributions (in the case of the descdist function in the fitdistrplus package this is a handful of commonly encountered distributions); the fitdist function in the same package can be used to fit the data to a specified distribution.
Results
The table below lists some basic properties of each of the systems analysed. The large difference in mean/median uptimes between some systems is caused by very fat tails in the uptime distribution of some systems, see [LANL-node-uptime-binned].
| System | Nodes | Failures | Mean | Median |
|---|---|---|---|---|
|
2
|
49
|
6997
|
133
|
377
|
|
16
|
16
|
2595
|
89
|
229
|
|
18
|
823
|
3014
|
2336
|
4147
|
|
19
|
738
|
2344
|
2376
|
4069
|
|
20
|
323
|
2063
|
653
|
2544
|
If there are any significant changes in failure rate over time or across different nodes in a given system it could have a significant impact on the distribution of uptime intervals. So we first check to large differences in failure rates.
Do systems experience any significant changes in failure rate over time?
The plot below shows the total number of failures, binned using 30-day periods, for the five systems. Two patterns that stand out are system 20 which experienced many failures during the first few months and then settled down, and system 2’s sudden spike in failures around month 23 before settling down again. This analysis is intended to be broad brush and does not get involved with details of specific systems, but these changes in failure frequency suggest that the exact form of any fitted distribution may change over time in turn potentially leading to a change of checkpoint interval.
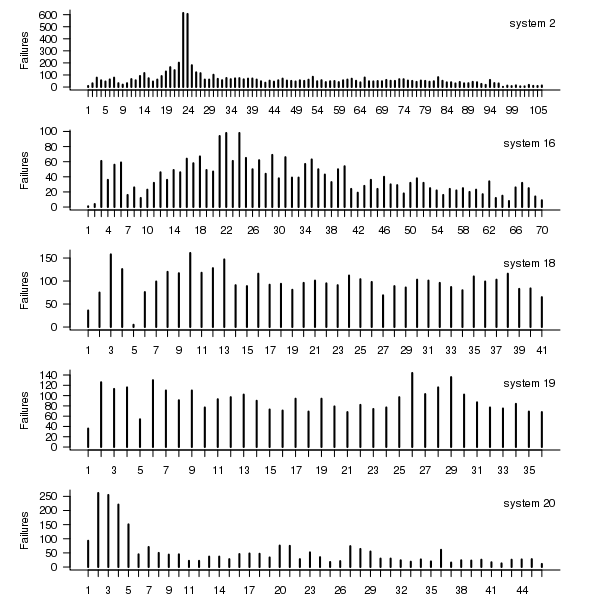
Figure 1. Total number of failures per 30-day interval for each LANL system.
Do some nodes failure more often than others?
The plot below shows the total number of failures for each node in the given system. Node 0 has many more failures than the other nodes (for node 0 of system 2 most of the failure data appears to be missing, so node 1 has the most failures). The distribution suggested by the analysis below is not changed if Node 0 is removed from the dataset.
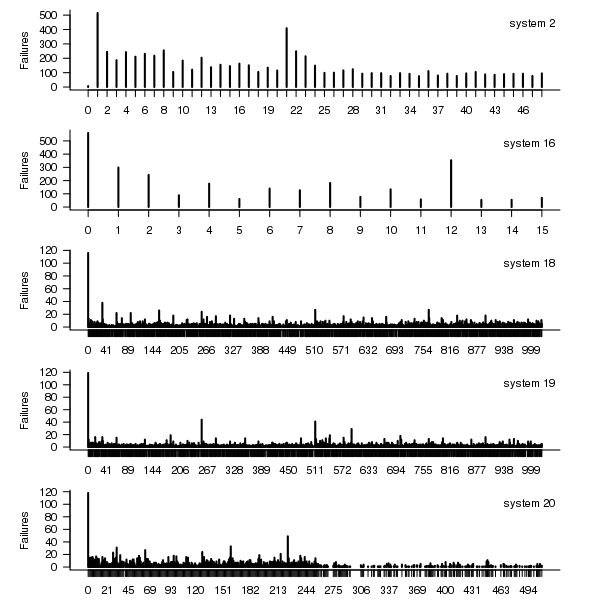
Figure 2. Total number of failures for each node in the given LANL system.
Fitting node uptimes
When plotted in units of 1 hour there is a lot of variability and so uptimes are binned into 10 hour units to help smooth the data. The number of uptimes in each 10-hour bin forms a discrete distribution and a [Cullen and Frey test] suggests that the negative binomial distribution might provide the best fit to the data; the Scroeder and Gibson analysis did not try the negative binomial distribution and of those they tried found the Weilbull distribution gave the best fit; the R functions were not able to fit this distribution to the data.
The plot below shows the 10-hour binned data fitted to a negative binomial distribution for systems 2 and 18. Visually the negative binomial distribution provides the better fit and the Akaiki Information Criterion values confirm this (see code for details and for the results on the other systems, which follow one of the two patterns seen in this plot).
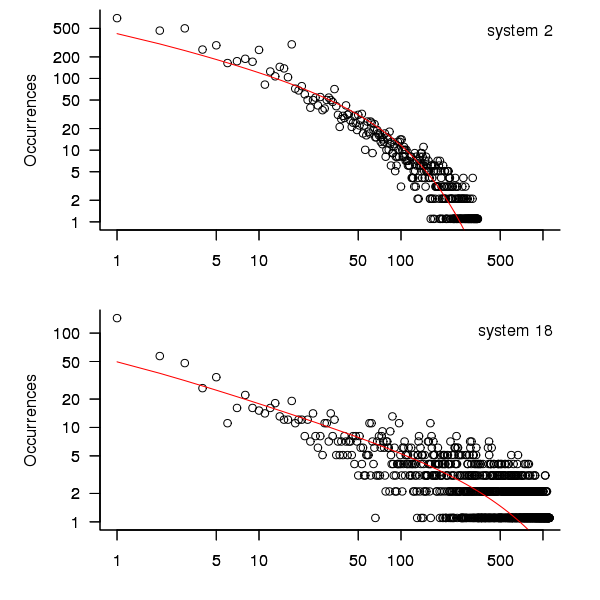
Figure 3. For systems 2 and 18, number of uptime intervals, binned into 10 hour interval, red line is fitted negative binomial distribution.
The negative binomial distribution is also the best fit for the uptime of the systems 16, 19 and 20.
The Poisson distribution often crops up in failure analysis. The quality of fit of a Poisson distribution to this dataset was an order of worse for all systems (as measured by AIC) than the negative binomial distribution.
Discussion
This analysis only compares how well commonly encountered distributions fit the data. The variability present in the datasets for all systems means that the quality of all fitted distributions will be poor and there is no theoretical justification for testing other, non-common, distributions. Given that the analysis is looking for the best fit from a chosen set of distributions no attempt was made to tune the fit (e.g., by forming a zero-truncated distribution).
Of the distributions fitted the negative binomial distribution has the lowest AIC and best fit visually.
As discussed in the section on [properties of distributions] the negative binomial distribution can be generated by a mixture of [Poisson distribution]s whose means have a [Gamma distribution]. Perhaps the many components in a node that can fail have a Poisson distribution and combined together the result is the negative binomial distribution seen in the uptime intervals.
The Weilbull distribution is often encountered with datasets involving some form of time between events but was not seen to be a good fit (for a continuous distribution) by a Cullen and Frey test and could not be fitted by the R functions used.
The characteristics of node uptime for two systems (i.e., 2 and 16) follows what might be thought of as a typical distribution of measurements, with some fattening in the tail, while two systems (i.e., 18 and 19) have very fat tails with indeed and system 20 sits between these two patterns. One system characteristic that matches this pattern is the number of nodes contained within it (with systems 2 and 16 having under 50, 18 and 19 having over 1,000 and 20 having around 500). The significantly difference in the size of the tails is reflected in the mean uptimes for the systems, given in the table above.
Summary of findings
The negative binomial distribution, of the commonly encountered distributions, gives the best fit to node uptime intervals for all systems.
There is over an order of magnitude variation in the mean uptime across some systems.
Proposal for a change of approach to programming language teaching
In a previous post I explained why I think developers don’t really know any computer language, and in this post I want to outline how I think we should adapt to this reality and radically change the approach taken to teaching students about using a computer language. First, a couple of points:
- The programming community needs to change its attitude towards language knowledge from being an end in itself to being something that is ok to acquire on an as needed basis. Developers don’t need to know much about the programming language they use in order to get their job done, get over it. Spending time learning the ins and outs of a language’s semantics rarely provides a worthwhile return on investment compared to time spent learning something else, such as the application domain or customer requirements,
- designing a new, ‘simpler’ programming language is not a solution; the existing languages in common use are not going away anytime soon and creating a new general purpose language is only going to overload developers with more stuff to learn and yet another runtime system to interface to,
- we need to concentrate on suggestions about what students and developers should be doing and not what they should not be doing. This is not only a good teaching principle it avoids the problem of having to come up with a good list of things not to do (coding standard recommendations are very rarely based on any evidence apart from the proposers own point of view and even the ones that make it through peer review are little more than group think or a waste of time).
The response to the existing state of affairs should be to approach the teaching of programming languages as an exercise in teaching students only what they need to know to do useful work, rather than acting on the belief that students should strive to be experts in the language they use and burdening them with lots of pointless language details. The exact minimum-set of knowledge could vary across different industries and application domains, so the set might need to be a bit larger than the minimum to be on the safe side.
Invariably some developers will need to know more than the minimum-set, so we also need to figure out what ‘template’ knowledge (or whatever term is used, an alternative is behavior patterns or patterns of behavior) should be included in the next level of language knowledge, this can be documented and made available to anybody who wants to read it; there may or may not be more levels before a developer is told to go and read a reference book or the language reference manual to figure out what they need to know.
This is minimum-set approach, with the opportunity to progress to successively more detailed levels, is often used for learning human languages, computer languages are not any different.
I would expect there to be some variation in the minimum-set between different languages, and would resist the temptation to try and create a ‘common minimum’ until some experience had been gained in teaching single languages.
How would the minimum-set of language knowledge be chosen? Simple. Students need to learn those construct they are likely to use most of the time, and that question can be answered by measuring a large amount of existing source code. Results from measurements that have been made typically show a small number of constructs are used a large percentage of the time. For instance, measurements of C source find that the 33.2% of for-loops have the form: for (assignment ; identifier < identifier ; identifier++), where identifier might be two or more different identifiers; allowing the central test to have the form identifier < expression takes the percentage to over 50%. I would expect the same pattern of usage to occur in source written in other languages but don't have any number to back up that assertion.
Perhaps the most important pattern of (developer) behavior is what its discoverer, Jorma Sajaniemi, calls the roles of variables (each variable is used to hold a particular kind of information, e.g., most wanted holder, stepper, container, etc).
One pattern of behavior that I am more or less completely in the dark about is class/package usage. There is the famous book on design patterns which the authors did a good job of promoting, but I have yet to see any empirical evidence showing the claimed benefits. The analysis of class/package behavioral usage is non-trivial, but it can be done.
Would I insist that developers only use constructs list in the suggested minimum-set (plus possible extras)? No. The purpose of this proposal is to help students and developers learn what they need to know to get a job done. Figuring out what language constructs, if any, should be avoided at all costs is a very tough problem which at the end of the day might not be worth solving.
A minimum-set knowledge of the language being used does not imply poor quality code. Most code is simple anyway, the complicated stuff invariably revolves around the algorithms that need to be used, and a skillful developer is one who uses straightforward language constructs to create easy to maintain code, not one who writes code that relies on detailed knowledge of some language feature.
I expect this proposal to adopt a minimum-set approach to language teaching will draw an angry reaction from the cottage industry that makes its living from writing and giving seminars on the latest trends in language-X. Don't panic guys, managers are well aware that this kind of knowledge rarely has any impact of developer performance and the actual motivation for sending employees on such seminars is to keep them happy (it can be a much more effective way of keeping staff than simply giving them a pay rise).
Most developers don’t really know any computer language
What does it mean to know a language? I can count to ten in half a dozen human languages, say please and thank you, tell people I’m English and a few other phrases that will probably help me get by; I don’t think anybody would claim that I knew any of these languages.
It is my experience that most developers’ knowledge of the programming languages they use is essentially template based; they know how to write a basic instances of the various language constructs such as loops, if-statements, assignments, etc and how to define identifiers to have a small handful of properties, and they know a bit about how to glue these together.
There are many developers who can skilfully weave together useful programs from the hodgepodge of coding knowledge they happen to know (proving that little programming knowledge is needed to write useful programs).
The purpose of this post is not to complain about developers’ lack of knowledge of the programming languages they use; I appreciate that time spent learning about the application domain often gives a better return on investment compared to learning more about a language. The purpose is to suggest that the programming language community (e.g., teachers and tool producers) acknowledge how languages are primarily used and go with the flow rather than maintaining the fiction that developers know anything much about the languages they use and that they should acquire this knowledge to expert level; students should be taught the commonly encountered templates, not the general language rules, developers should be encouraged to use just the common templates (this will also have the side effect of reducing the effort needed to follow other peoples code since the patterns of usage will be familiar to many).
I suspect that many readers will disagree with the statement in this post’s title, and I need to provide more evidence before proposing (in another post) how we might adapt to the reality to be found in development teams.
The only evidence I can offer is my own experience; not a very satisfactory situation; a possible measurement approach discussed below. So what is this experience based evidence (I only claim to ‘know’ the handful of language I have written compiler front ends for, with other languages my usage follows the template form just like everybody else)?
- discussions with developers: individuals and development groups invariably have their own terminology for programming language constructs (my use of terminology appearing in the language definition usually draws blank stares and I have to make a stab at guessing what the local terms mean and using them if I want to be listened to); asking about identifier scoping or type compatibility rules (assuming that either of the terms ‘scope’ or ‘type compatibility’ is understood) usually results in a vague description of specific instances (invariably the commonly encountered situations),
- books that claim to teach a language often provide superficial coverage of the language semantics and concentrate on usage examples (because that is what is useful to their readers). Those books claiming to give insight into the depths of a language often contains many mistakes; perhaps the most well known example is Herbert Schildt’s “The Annotated ANSI C Standard”, Clive Feather’s review of the 1995 edition and Peter Seebach’s review of later versions,
- the word ‘Advanced’ has to appear in programming courses for professional developers with 3–10 years of experience because potential customers think they have reached an advanced level. In practice, such courses teach the basics and get away with it because most of the attendees don’t know them. My own experiences of teaching such courses is that outside of the walking people through the slides, the real teaching is about trying to undo some of the bad habits and misconceptions individuals have picked up over the years.
Recent graduate think they are an expert in the language used on their course because they probably have not met anybody who knows a lot more; some professional developers think they are language experts because the have lots of years of experience, in practice they tend to have spent those years essentially using what they originally learned and are now very adept with that small subset.
How might we measure the program language knowledge of the general developer population?
Software development question/answer sites such as Stack Overflow contain a wealth of information. I think I could write a function that did a reasonably good job of deducing the programming language, if any, being used in the question. Given the language definition (in some cases this might not exist, e.g., Perl and PHP) and the answers to the question of how do I figure out the language expertise of the person who wrote the answer?
First, we need to filter out those questions that are application related, with code being incidental. Latent Semantic Indexing could be used to locate the strongest connections between parts of the language specification and the non-source code answer text. If strong connections are found, the question would be assumed to be programming language related.
Developers only need surface knowledge to sprinkle any answer with phrases related to the language referred to; more in depth analysis is needed.
One idea is to process any code in the question/answer with a compiler capable of generating references to those parts of the language definition used during its semantic processing (ideally ‘part’ would be the sentence level, but I would settle for paragraph level or perhaps couple of paragraph level). A non-trivial overlap between the ‘parts’ references returned by the two searches would be a good indicator of programming language question. The big problem with this idea is complete lack of compilers supporting this language reference functionality (somebody please prove me wrong).
I am currently stumped for a practical technique for a non-superficial way of measuring developer language expertise. The 2013 Mining Software Repositories challenge is based on a dump of the questions/answers from Stack Overflow, I’m looking forward to seeing what useful information researchers extract from it.
Superoptimizers are back in vogue
There has always been the need for a few developers with in-depth knowledge of a particular cpu architecture to sit down and think very hard about how best to implement a snippet of code performing some operation in assembly language, e.g., library implementors wanting the tightest code for a critical inner loop or compiler writers who need to map from intermediate code to machine code.
In 1987 Massalin published his now famous paper that introduced the term Superoptimizer; a program that enumerates all possible combinations of instruction sequences until the shortest/fastest one producing the desired output from the given input is found (various heuristics were used to prune the search space e.g., only considering 15 or so opcodes, and the longest sequence it ever generated contained 12 instructions).
While the idea was widely talked about, it never caught on in practice (a special purpose branch eliminator was produced for GCC; Hacker’s Delight also includes a stand-alone system). Perhaps the guild of mindbogglingly-obtuse-but-fast-instruction-sequences black-balled it (apprentices have to spend several years doing nothing but writing assembly code for their chosen architecture, thinking about how to make it go faster and/or be shorter and only talk to other apprentices/members and communicate with non-converts exclusively about their latest neat sequence), or perhaps it was just a case of not invented here (writing machine code used to be something that even run-of-the-mill developers got to do every now and again), or perhaps it was not considered cost-effective to build a superoptimizer for a given project (I don’t know of anyone offering a generic tool that could be tailored for specific cases) or perhaps developers were happy to just ride the wave of continually faster processors.
It was not until 2008 with Bansal’s thesis that superoptimizer research started to take off (as in paper publication rate increased from once every five years to more than one a year). Bansal found a new market, binary translation i.e., translating the binary of a program built to run on one kind of cpu to run on a different kind of cpu, for instance the Mac 68K emulator.
Bansal and other researchers’ work was oriented towards relatively short instruction sequences. To be really useful, some way of handling longer sequences was needed.
A few days ago Stochastic Superoptimization arrived on the scene (or rather a paper describing it became available for download). Schkufza, Sharma and Aiken use Markov chain Monte Carlo methods to sample the possible instruction sequences rather than generating all of them. The paper gives a 116 instruction example from which the author’s tool removed 16 lines to produce code that went 1.6 times faster (only 30 ‘core’ instructions were given in paper); what is also very interesting is that the tool operates on compiler generated output (gcc/llvm), suggesting the usage build program, profile it and then stochastic superoptimize the hot spots.
Markov chains and Monte Carlo methods are trendy topics that researchers like to write about, so we will certainly see more papers in this area.
These days few developers have had hands-on experience with machine code, so the depth of expertise that was once easy to find is now rare, processors have many more weird and wonderful instructions often interacting with older instructions in obscure ways, and the cpu architecture landscape continues to change regularly. The time may have arrived for superoptimizers to be widely used by industry.
Of course, superoptimizers can work at any level of abstraction, including expression trees built directly from some complicated floating-point calculation that needs to be optimized for accuracy or speed.
Recent Comments