Archive
Transition probabilities when adjacent sequence items must be different
Generating a random sequence from a fixed set of items is a common requirement, e.g., given the items A, B and C we might generate the sequence BACABCCBABC. Often the randomness is tempered by requirements such as each item having each item appear a given number of times in a sequence of a given length, e.g., in a random sequence of 100 items A appears 20 times, B 40 times and C 40 times. If there are rules about what pairs of items may appear in the sequence (e.g., no identical items adjacent to each other), then sequence generation starts to get a bit complicated.
Let’s say we want our sequence to contain: A 6 times, B 12 times and C 12 times, and no same item pairs to appear (i.e., no AA, BB or CC). The obvious solution is to use a transition matrix containing the probability of generating the next item to be added to the end of the sequence based on knowing the item currently at the end of the sequence.
My thinking goes as follows:
- given A was last generated there is an equal probability of it being followed by B or C,
- given B was last generated there is a 6/(6+12) probability of it being followed by A and a 12/(6+12) probability of it being followed by C,
- given C was last generated there is a 6/(6+12) probability of it being followed by A and a 12/(6+12) probability of it being followed by B.
giving the following transition matrix (this row by row approach having the obvious generalization to more items):
Second item
A B C
A 0 .5 .5
First
item B .33 0 .67
C .33 .67 0 |
Having read Generating constrained randomized sequences: Item frequency matters by Robert M. French and Pierre Perruchet (from whom I take these examples and algorithm on which the R code is based), I now know this algorithm for generating transition matrices is wrong. Before reading any further you might like to try and figure out why.
The key insight is that the number of XY pairs (reading the sequence left to right) must equal the number of YX pairs (reading right to left) where X and Y are different items from the fixed set (and sequence edge effects are ignored).
If we take the above matrix and multiply it by the number of each item we get the following (if A occurs 6 times it will be followed by B 3 times and C 3 times, if B occurs 12 times it will be followed by A 4 times and C 8 times, etc):
Second item
A B C
A 0 3 3
First
item B 4 0 8
C 4 8 0 |
which implies the sequence will contain AB 3 times when counted forward and BA 4 times when counted backwards (and similarly for AC/CA). This cannot happen, the matrix is not internally consistent.
The correct numbers are:
Second item
A B C
A 0 3 3
First
item B 3 0 9
C 3 9 0 |
giving the probability transition matrix:
Second item
A B C
A 0 .5 .5
First
item B .25 0 .75
C .25 .75 0 |
This kind of sequence generation occurs in testing and I wonder how many people have made the same mistake as me and scratched their heads over small deviations from the expected results.
The R code to calculate the transition matrix is straight forward but obscure unless you have the article to hand:
# Calculate expression (3) from: # Generating constrained randomized sequences: Item frequency matters # Robert M. French and Pierre Perruchet transition_count=function(item_count) { N_total=sum(item_count) # expected number of transitions ni_nj=(item_count %*% t(item_count))/(N_total-1) diag(ni_nj) = 0 # expected number of repeats d_k=item_count*(item_count-1)/(N_total-1) # Now juggle stuff around to put the repeats someplace else n=sum(ni_nj) n_k=rowSums(ni_nj) s_k=n - 2*n_k R_i=d_k / s_k R=sum(R_i) new_ij=ni_nj*(1-R) + (n_k %*% t(R_i)) + (R_i %*% t(n_k)) diag(new_ij)=0 return(new_ij) } transition_prob=function(item_count) { tc=transition_count(item_count) tp=tc / rowSums(tc) # relies on recycling return(tp) } |
the following calls:
transition_count(c(6, 12, 12)) transition_prob(c(6, 12, 12)) |
return the expected results.
French and Perruchet provide an Excel spreadsheet (note this contains a bug, the formula in cell F20 should start with F5 rather than F6).
Impact of compiler optimization level on recovery from a hardware error
I have previously written about cosmic-ray induced faults in cpus and some of the compiler research being done to recover from such hardware faults. If your program is executing in an environment where radiation may cause hardware bit-flips to occur and you don’t have access to a research compiler providing some level of recovery, is it better to compile with high or low levels of optimization?
Short answer: Using gcc with optimization options O2 or O3 reduces the probability that a bit-flip will change the external behavior of a program, compared to option O0.
The longer answer is below as another draft section from my book Empirical software engineering with R book. As always comments welcome.
Software masking of hardware faults
Like all hardware cpus are subject to intermittent faults, these faults may flip the value of a bit in a program visible register, a bit in an executable instruction or some internal processor state (causes include cosmic rays, and electrical wear of the material from which circuits are built).
If a bit-flip randomly occurs at some point during a program’s execution, is it less likely to effect external program behavior when the code has been built with high levels of compiler optimization or built with optimization disabled or at a low level?
- many optimizations reduce the number of instructions executed (reducing execution time reduces the probability of encountering a bit-flip) and makes more efficient use of registers (e.g., keeping needed values in registers over longer periods of time and reducing the time intervals when a registers is not in use; which increases the probability that a bit-flip will propagate to external behavior),
- fewer compiler optimizations is likely to result in an increased number of instructions executed (increasing the probability that a bit-flip will occur during program execution) and results in lower register usage efficiency (e.g., longer periods of time between the last use of register contents and a new value being loaded; increasing the probability that a bit-flip will modify a value that is never used again).
A study by Cook and Zilles flipped one bit in an executing program (100 evenly distributed points in the program were chosen and 100 instructions from each of those points were used as fault injection points, giving a total of 10,000 individual tests to be run) and monitored the impact on subsequent execution; this process was repeated between 32 and 244 times for each injection point, once for every bit in the 32-bit instruction, zero, one or two of its 64-bit input registers and one possible 64-bit output result register (i.e., the bit-flip only involved the current instruction and its input/output, not the contents of any other register or main memory).
The monitoring process consisted of two parallel executions containing the modified processor state and the unmodified processor state. The behavior of the two executions were compared to see if the fault did not propagate (a passing trial, e.g., a bit-wise AND of a register with 0xff when a bit-flip has been applied to one of the top 24 bits of the register, also the values in a branch not-equal are usually not-equal and a bit-flip is likely to maintain that state), caused a failure (either due to a compulsory event caused by a hardware trap such as an invalid instruction or an incorrectly aligned memory access, or what was called an error model event such as a control flow mismatch or writing a different value to storage), or is inconclusive (pass/fail did not occur within 10,000 executed instructions of the fault injection point).
Data
The available data consists of the normalised number of program executions having one of the behaviors pass, fail (compulsory), fail (error model, broken down into control flow and store related cases) or inconclusive for nine programs from the SPEC2000 integer benchmark compiled using gcc version 4.0.2 and the DEC C compiler (henceforth called O0, O2 and O3, for osf the O4 option was used.
There are nine measurements for each of the nine SPEC programs, repeated at 3 optimization levels for gcc and once for osf (the osf data is not analysed here).
Is the data believable?
Injecting bit-flip faults at all points in a program and monitoring for subsequence changes in external behavior would be an enormous task, sets of 100 instructions starting from 100 locations appears to be an unbiased sample.
The error model used checks for changes of control flow and different values being stored to memory, it does not check for actual changes in external program behavior. This model biases the measurements in favour of more bit-flips being counted as generating an error than would occur in practice.
Predictions made in advance
Does compiler optimization level change the probability that a bit-flip will cause a change in external program behavior?
No hypothesis is proposed suggesting that compiler optimization level will increase, decrease or have no effect on the probability of a bit-flip effecting external program behavior.
Applicable techniques
The data was originally a count of the number of instances and this has been normalised to a value between 0 and 100. The same number of programs were executed at all optimization levels.
Non-parametric techniques have to be used because nothing is known about the distribution of values.
The [Wilcoxon signed-rank test] is a test for two dependent samples while the [Mann-Whitney U test] is a test for two independent samples. To what extent does running gcc at different optimization levels make it a different compiler? Given that we are testing for the possibility that compiler optimizations do effect the results then it is necessary to treat the samples as being independent.
The function wilcox.test will perform a Mann-Whitney test if the parameter paired is FALSE (the default) and will generate a confidence interval if the parameter conf.int is TRUE (the default is FALSE).
Results
The Mann-Whitney test of the various measurements obtained using the O2 and O3 options finds no worthwhile difference between them. There are interesting differences in the values obtained using both of two options and the O0 option, as follows:
- Pass
-
Comparing percentage of pass behaviors for
O0andO2we see: p-values = 0.005 and 0.005
> wilcox.test(gcc.o0$pass.masked, gcc.o2$pass.masked, conf.int=TRUE)
Wilcoxon rank sum test with continuity correction
data: gcc.o0$pass.masked and gcc.o2$pass.masked
W = 8, p-value = 0.004697
alternative hypothesis: true location shift is not equal to 0
95 percent confidence interval:
-15.449995 -2.020001
sample estimates:
difference in location
-7.480088
The wilcox.test function returns an estimate of the difference between the two means and a negative value occurs if the second argument (the higher optimization level in this case) has a greater mean than the first argument (which is always the O0 option in these results).
O0/O3 95% confidence interval: -15.579959 -1.909965, mean: -4.780058
- Fail (compulsory)
-
-
Memory protection fault: pvalues = 0.002 and 0.005
O0/O295%: 2.1 7.5, mean: 4.9
O0/O395%: 1.9 7.3, mean: 4.1 -
Invalid instruction: p-values = 0.045 and 0.053
O0/O295%: -8.0e-01 -4.9e-08, mean: -0.5
O0/O395%: -6.4e-01 5.1e-06, mean: -0.3
-
Memory protection fault: pvalues = 0.002 and 0.005
- Fail (error model)
-
-
Control flow: p-values = 0.0008 and 0.002
O0/O295%: -10.8 -3.8, mean: -7.0
O0/O395%: -10.5 -3.7, mean: -6.8 -
Store related: p-values = 0.002 and 0.003
O0/O295%: 4.78 22.02, mean: 11.24
O0/O395%: 4.93 18.78, mean: 10.51
-
Control flow: p-values = 0.0008 and 0.002
Discussion
O2 and O3 options differences
The issue of optimization performance differences between the gcc O2 and O3 options is covered in [another section] of this book. That analysis found that the only difference between the two options was an increase in code size with O3, probably because of function inlining.
If there is no significant difference in the code generated by the O2/O3 options then no difference in bit-flip behavior is expected, and none was seen.
Changes in failure rates
The results show a decrease in store related errors at high optimization levels and an increase in control flow related errors. Why is this?
Optimizing register usage is a very important optimization and one of its consequences is a reduction in the number of stores to memory and loads having a corrupted address triggering a protection fault . A reduction in the number of memory related instructions executed will feed through into a reduction in the number of failures classified as store related or memory protection faults and this is seen in the shift in mean value of fails between high and low optimization levels.
Keeping a value containing an injected bit-flip in a register for a longer period of program execution (rather than being stored to memory and loaded back later) provides the opportunity for it to work its way through subsequent instructions and either disappear (being counted as a pass) or cause a control flow failure. It is likely that some of the change stored values flagged by the error model do not an impact on external program behavior and the pass count at low optimization levels is lower than would occur in practice.
Changes in pass rate
The additional optimizations of register usage enabled by the O2/O3 options reduces memory accesses which leads to a reduction in memory protection errors, an unrecoverable fault under all circumstances. The numbers suggest that while this is a major factor in the increased pass rate, contributions are made by other sources, e.g., bit-flips not contributing to the result calculated by an instruction; the data is not sufficiently detailed to enable a reliable estimate of this contribution to be made.
The pass rate is likely to be an underestimate because the error model classifies storing a different value as a failure, however the different value might not result in a change of external program behavior, e.g., the value stored might never be used again. Some of the stores classified as errors for the O0 option have no lasting affect in practice (and being kept in registers for O2/O3 had the opportunity to be masked out). No data is available for enable an estimate to be made for the percentage of these bit-flips have no lasting affect.
The average pass rate for gcc using the O0 option was 28% and this increased to around 36% when the O2/O3 options were used.
Other processors
How likely is it that the bit-flip pass rates seen on the Alpha (average of 36% for high optimization, 28% for low) would also occur on other processors?
The Alpha registers contain 64-bit and instructions operating on just 32 or 16 of those bits are supported. A study by Loh of the Alpha running SPEC2000 programs found that 48% of executed instructions operated on 64-bits, 24% on 32-bits and 28% on 16-bits. Based on these numbers 33% of single bit-flips of a 64-bit register would not be expected to affect the result of an instruction (the table below gives the percentages measured by Cook et al).
| injection site | O3 | O2 | O0 |
|---|---|---|---|
|
instruction
|
28.2
|
29.2
|
21.3
|
|
input register1
|
49.0
|
50.0
|
40.5
|
|
input register2
|
26.5
|
28.5
|
17.9
|
|
output register
|
39.6
|
41.9
|
34.7
|
A lot of software is based on using 32-bit integers and it might be expected that a much lower percentage of register bit-flips would result in pass behavior, compared to a 64-bit processor (where most operations that access 64 bits involve addresses). However, 32-bit processors usually contain instructions for operating on just 8-bits of a register and use of these instructions creates more opportunities for bit-flips to have no lasting consequences.
The measurements of Cook and Zilles have shown how interrelated instruction set interactions are. Without measurements from 32-bit processors it is not possible to estimate the extent to which bit-flips will impact external program behavior.
Conclusion
Compiling source using high levels of compiler optimization reduces the likelihood that a randomly occurring bit-flip during program execution will effect external program behavior. For processors that perform memory access checks the largest decrease in bit-flip induced faults is a reduction in memory protection faults.
Optimization generally reduces the number of instructions executed by a program, reducing the probability that a bit-flip will occur between the start and end of execution, further increasing the advantage of optimized code over non-optimized.
Teach children planning and problem solving not programming
When I first heard that children in secondary education (11-16 year olds) here in the UK were to be taught programming I thought it was another example of a poorly thought through fad ruining our education system. Schools already have enough trouble finding goos maths and science teachers, and the average school leavers knowledge of these subjects is not that great, now resources and time are being diverted to a specialist subject for which it is hard to find good teachers. After talking to a teacher about his experience teaching Scratch to 11-13 year olds I realised he was not teaching programming but teaching how to think through problems, breaking them down into subcomponents and cover all possibilities; a very worthwhile subject to teach.
As I see it the ‘writing code’ subject needs to be positioned as the teaching of planning and problem solving skills (ppss, p2s2, a suitable acronym is needed) rather than programming. Based on a few short conversations with those involved in teaching, the following are a few points I would make:
- Stay with one language (Scratch looks excellent).
- The more practice students get with a language the more fluent they become, giving them more time to spend solving the problem rather than figuring out how to use the language.
- Switching to a more ‘serious’ language because it is similar to what professional programmers use is a failure to understand the purpose of what is being taught and a misunderstanding of why professionals still use ‘text’ based languages (because computer input has historically been via a keyboard and not a touch sensitive screen; I expect professional programmers will slowly migrate over to touch screen programming languages).
- Give students large problems to solve (large as in requiring lots of code). Small programs are easy to hold in your head, where the size of small depends on intellectual capacity; the small program level of coding is all about logic. Large programs cannot be held in the head and this level of coding is all about structure and narrative (there are people who can hold very large programs in their head and never learn the importance of breaking things down so others can understand them), logic does not really appear at this level. Large problems can be revisited six months later; there is no better way of teaching the importance of making things easy for others to understand than getting a student to modify one of their own programs a long time after they originally wrote it (I’m sure many will start out denying ever having written the horrible code handed back to them).
- Problems should not be algorithms. Yes, technically all programs are algorithms but most are not mathematical algorithms in the sense that, say, sorting and searching are, real life problems are messy things that involve lots of simple checks for various conditions and ad-hoc approaches to solving a problem. Teachers should resist mapping computing problems to the Scratch domain, e.g., tree walking algorithms mapped to walking the branches of a graphical tree or visiting all parts of a maze.
Changes in optimization performance of gcc over time
The SPEC benchmarks came out a year after the first release of gcc (in fact gcc was and still is one of the programs included in the benchmark). Compiling the SPEC programs using the gcc option -O2 (sometimes -O3) has always been the way to measure gcc performance, but after 25 years does this way of doing things tell us anything useful?
The short answer: No
The longer answer is below as another draft section from my book Empirical software engineering with R book. As always comments welcome.
Changes in optimization performance of gcc over time
The GNU Compiler Collection <book gcc-man_12> (GCC) is under active development with its most well known component, the C compiler gcc, now over 25 years old. After such a long period of development is the quality of code generated by gcc still improving and if so at what rate? The method typically used to measure compiler performance is to compile the [SPEC] benchmarks with a small set of optimization options switched on (e.g., the O2 or O3 options) and this approach is used for the analysis performed here.
Data
Vladimir N. Makarow measured the performance of 9 releases of gcc, occurring between 2003 and 2010, on the same computer using the same benchmark suite (SPEC2000); this data is used in the following analysis.
The data contains the [SPEC number] (i.e., runtime performance) and code size measurements on 12 integer programs (11 in C and one in C+\+) from SPEC2000 compiled with gcc versions 3.2.3, 3.3.6, 3.4.6, 4.0.4, 4.1.2, 4.2.4, 4.3.1, 4.4.0 and 4.5.0 at optimization levels O2 and O3 (the mtune=pentium4 option was also used) 32-bit for the Intel Pentium 4 processor.
The same integer programs and 14 floating-point programs (10 in Fortran and 4 in C) were compiled for 64-bits, again with the O2 and O3 options (the mpc64 floating-point option was also used), using gcc versions 4.0.4, 4.1.2, 4.2.4, 4.3.1, 4.4.0 and 4.5.0.
Is the data believable?
The following are two fitness-for-purpose issues associated with using programs from SPEC2000 for these measurements:
-
the benchmark is designed for measuring processor performance not
compiler performance, -
many of its programs have been used for compiler benchmarking for
many years and it is likely that gcc has already been tuned to do
well on this benchmark.
The runtime performance measurements were obtained by running each programs once, SPEC requires that each program be run three times and the middle one chosen. Multiple measurements of each program would have increased confidence in their accuracy.
Predictions made in advance
Developers continue to make improvements to gcc and it is hoped that its optimization performance is increasing, knowing that performance is at a steady state or decreasing performance is also of interest.
No hypothesis is proposed for how optimization performance, as measured by the O2 and O3 options, might change between releases of gcc over the period 2003 to 2010.
The gcc documentation says that using the O3 option causes more optimizations to be performed than when the O2 option is used and therefore we would expect better performance for programs compiled with O3.
Applicable techniques
Modelling individual O2 and O3 option performance
One technique for modelling changes in optimization performance is to build a linear model that fits the gcc version (i.e., version is the predictor variable) to the average performance of the code it generate, calculating the averaged performance over each of the programs measured with the corresponding version of gcc. The problem with this approach is that by calculating an average it is throwing away information that is available about the variation in performance across different programs.
Building a [mixed-effects] model would make use of all the data when fitting a relationship between two quantities where there is a recurring random component (i.e., the SPEC program used). The optimizations made are likely to vary between different SPEC programs, we could treat the performance variations caused by difference in optimization as being random and having an impact on the mean performance value of all programs.
Programs differ in the magnitude of their SPEC number and code size, the measurements were converted to the percentage change compared against the values obtained using the earliest version of gcc in the measurement set.
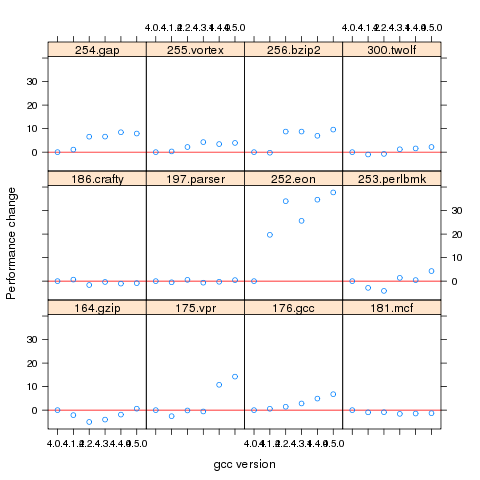
Figure 1. Percentage change in SPEC number (relative to version 4.0.4) for 12 programs compiled using 6 different versions of gcc (compiling to 64-bits with the O3 option).
Fitting a linear model requires at least two sets of [interval data]. The gcc version numbers are [ordinal values] and the following are two possible ways of mapping them to interval values:
-
there have been over 150 different released versions of gcc and a
particular version could be mapped to its place in this sequence. -
the date of release of a version can be mapped to the number of
days since the first release.
If version releases are organized around new functionality added then it makes sense to use version sequence number. If the performance of a new optimization was proportional to the amount of effort (e.g., man days) that went into its implementation then it would make sense to use days between releases.
The versions tested by Makarow were each from a different secondary release within a given primary version line and at roughly yearly intervals (two years separated the first pair and one month another pair).
There have been approximately 25 secondary releases in the 25 year project and using a release version sequence number starting at 20 seems like a reasonable choice.
Internally a compiler optimizer performs many different kinds of optimizations (gcc has over 160 different options for controlling machine independent optimization behavior). While the implementation of a new optimization is a gradual process involving many days of work, from the external user perspective it either exists and does its job when a given optimization level is supported or it does not exist.
What is the shape of the performance/release-version relationship? In the first few years of a compilers development it is to be expected that all the known major (i.e., big impact) optimization will be implemented and thereafter newly added optimizations have a progressively smaller impact on overall performance. Given gcc’s maturity it looks reasonable to assume that new releases contain a few additional improvement that have an incremental impact, i.e., the performance/release-version relationship is assumed to be linear (no other relationship springs out of a plot of the data).
A mixed-effects model can be created by calling the R function lme from the package nlme. The only difference between the following call to lme and a call to lm is the third argument specifying the random component.
t.lme=lme(value ~ variable, data=lme.O2, random = ~ 1 | Name) |
The argument random = ~ 1 | Name specifies that the random component effects the mean value of the result (when building a model this translates to an effect on the value of the intercept of the fitted equation) and that Name (of the program) is the grouped variable.
To specify that the random effect applies to the slope of the equation rather than its intercept the call is as follows:
t.lme=lme(value ~ variable, data=lme.O2, random = ~ variable -1 | Name) |
To specify that both the slope and the intercept are effected the -1 is omitted (for this gcc data the calculation fails to converge when both can be effected).
Since the measurements are about different versions of gcc it is to be expected that the data format has a separate column for each version of gcc (the format that would be used to pass data lm) as follows:
Name v3.2.3 v3.3.6 v3.4.6 v4.0.4 v4.1.2 v4.2.4 v4.3.1 v4.4.0 v4.5.0 1 164.gzip 933 932 957 922 933 939 917 969 955 2 175.vpr 562 561 577 576 586 585 576 589 588 3 176.gcc 1087 1084 1159 1135 1133 1102 1146 1189 1211 |
The relationship between the three variables in the call to lme is more complicated and the data needs to be reorganize so that one column contains all of the values, one the gcc version numbers and another column the program names. The function melt from package reshape2 can be used to restructure the data to look like:
Name variable value 11 256.bzip2 v3.2.3 0.000000 12 300.twolf v3.2.3 0.000000 13 SPECint2000 v3.2.3 0.000000 14 164.gzip v3.3.6 -0.107181 15 175.vpr v3.3.6 -0.177936 16 176.gcc v3.3.6 -0.275989 17 181.mcf v3.3.6 0.148810 |
Comparing O2 and O3 option performance
When comparing two samples the [Wilcoxon signed-rank test] and the [Mann-Whitney U test] spring to mind. However, some of the expected characteristics of the data violate some of the properties that these tests assume hold (e.g., every release include new/updated optimizations which is likely to result in the performance of each release having a different mean and variance).
The difference in performance between the two optimization levels could be treated as a set of values that could be modelled using the same techniques applied above. If the resulting model have a line than ran parallel with the x-axis and was within the appropriate confidence bounds we could claim that there was no measurable difference between the two options.
Results
The following is the output produced by summary for a mixed-effect model, with the random variation assumed to effect the value of intercept, created from the SPEC numbers for the integer programs compiled for 64-bit code at optimization level O2:
Linear mixed-effects model fit by REML
Data: lme.O2
AIC BIC logLik
453.4221 462.4161 -222.7111
Random effects:
Formula: ~1 | Name
(Intercept) Residual
StdDev: 7.075923 4.358671
Fixed effects: value ~ variable
Value Std.Error DF t-value p-value
(Intercept) -29.746927 7.375398 59 -4.033264 2e-04
variable 1.412632 0.300777 59 4.696612 0e+00
Correlation:
(Intr)
variable -0.958
Standardized Within-Group Residuals:
Min Q1 Med Q3 Max
-4.68930170 -0.45549280 -0.03469526 0.31439727 2.45898648
Number of Observations: 72
Number of Groups: 12
|
and the following summary output is from a linear model built from an average of the data used above.
Call:
lm(formula = value ~ variable, data = lmO2)
Residuals:
13 26 39 52 65 78
0.16961 -0.32719 0.47820 -0.47819 -0.01751 0.17508
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -28.29676 2.22483 -12.72 0.000220 ***
variable 1.33939 0.09442 14.19 0.000143 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.395 on 4 degrees of freedom
Multiple R-squared: 0.9805, Adjusted R-squared: 0.9756
F-statistic: 201.2 on 1 and 4 DF, p-value: 0.0001434
|
The biggest difference is that the fitted values for the Intercept and slope (the column name, variable, gives this value) have a standard error that is 3+ times greater for the mixed-effects model compared to the linear model based on using average values (a similar result is obtained if the mixed-effects random variation is assumed to effect the slope and the calculation fails to converge if the variation is on both intercept and slope). One consequence of building a linear model based on averaged values is that some of the variations present in the data are smoothed out. The mixed-effects model is more accurate in that it takes all variations present in the data into account.
For integer programs compiled for 32-bits there is much less difference between the mixed-effects models and linear models than is seen for 64-bit code.
-
For SPEC performance the created models show:
-
for the integer programs a rate of increase of around 0.6% (sd
0.2) per release forO2andO3options on 32-bit code
and an increase of 1.4% (sd 0.3) for 64-bit code, -
for floating-point, C programs only, a rate of increase per
release of 12% (sd 5) at 32-bits and 1.4% (sd 0.7) at 64-bits, with
very little difference between theO2andO3options.
-
for the integer programs a rate of increase of around 0.6% (sd
-
For size of generated code the created models show:
-
for integer programs 32-bit code built using
O2size is
decreasing at the rate of 0.6% (sd 0.1) per release, while for both
64-bit code andO3the size is increasing at between 0.7% (sd
0.2) and 2.5% (sd 0.4) per release, -
for floating-point, C programs only, 32-bit code built using
O2had an unacceptable p-value, while for both 64-bit code
andO3the size is increasing at between 1.6% (sd 0.3) and
9.3 (sd 1.1) per release.
-
for integer programs 32-bit code built using
Comparing O2 and O3 option performance
The intercept and slope values for the models built for the SPEC integer performance difference had p-values way too large to be of interest (a ballpark estimate of the values would suggest very little performance difference between the two options).
The program size change models showed O3 increasing, relative to O2, at 1.4% to 1.7% per release.
Discussion
The average rate of increase in SPEC number is very low and does not appear to be worth bothering about, possible reasons for this include:
-
a lot of effort has already been invested in making sure that gcc
performs well on the SPEC programs and the optimizations now being
added to gcc are aimed at programs having other kinds of
characteristics, -
gcc is a mature compiler that has implemented all of the worthwhile
optimizations and there are no more major improvements left to be
made, -
measurements based on just setting the
O2orO3
options might not provide a reliable guide to gcc optimization
performance. The command
gcc -c -Q -O2 --help=optimizers
shows that for gcc version 4.5.0 theO2option enables 91 of
the possible 174 optimization options and theO3option
enables 7 more. Performing some optimizations together sometimes
results in poorer quality code than if a subset of those
optimizations had been applied (genetic programming is being
researched as one technique for selecting the best optimizations
options to use for a given program and up to 13% improvements have
been obtained over gcc’s -O options <book Bashkansky_07>). The
percentage performance change figure above shows
that for some programs performance decreases on some releases.Whole program optimization is a major optimization area that has been addressed in recent versions of gcc, this optimizations is not enabled by the
Ooptions.
The percentage differences in SPEC integer performance between the O2 and O3 options were very small, but varied too much to be able to build a reliable linear model from the values.
For SPEC program code size there is a significant different between the O2 and O3 options. This is probably explained by function inlining being one of the seven additional optimization enabled by O3 (inlining multiple calls to the same function often increases code size <book inlining> and changes to the inlining optimization over releases could result in more functions being inlined).
Conclusion
Either the optimizations added to gcc between 2003 and 2010 have not made any significant difference to the performance of the generated code or the established method of measuring gcc optimization performance (i.e., the SPEC benchmarks and the O2 or O3 compiler options) is no longer a reliable indicator.
Descriptive statistics of some Agile feature characteristics
The purpose of software engineering research is to figure out how software development works so that the software industry can improve its quality/timeliness (i.e., lower costs and improved customer satisfaction). Research is hampered by the fact that companies are not usually willing to make public good quality data about the details of their software development processes.
In mid July a post on the ACCU general mailing list caught my eye and I followed a link to a very interesting report, went to visit 7digital a few weeks later, told them about my empirical software engineering with R book and how I wanted to make all the data I used available to readers and they agreed to make the data public! The data arrived at the start of August and I spent the rest of the month analyzing it (the R code I used to analyse it).
Below is a draft of what will eventually appear in the book. As always comments welcome, particularly if you can extract more information from the 7digital data (the mapping of material to WordPress blog format might still be flaky in places).
Agile feature characteristics
Traditionally software development projects work towards releasing product updates on prespecified dates, often with a release cycle of between once or twice a year and with many updates included in each release. In contrast to this approach development groups following an Agile method <book ???> make frequent releases with each containing a small incremental update (Agile is an umbrella term applied to a variety of iterative and incremental software development methodologies).
Rationale for the Agile approach includes getting rapid feedback from customers on the direction of developments and maximizing return on software investment by getting newly implemented features into customers hand almost immediately.
The large number of releases (compared to other approaches) has the potential to provide enough data for meaningful statistical analysis of questions such as how often new features are released and the number of features under development at any time.
7digital<book 7Digital_12> is a digital media delivery company that operates an international on-line digital music store (www.7digital.com) and provides business to business digital media services via an open API platform. At 7digital software development is done using an Agile process and since April 2009 various items of information have been recorded <book Bowley_12>; 7digital are open about there process and have made this information publicly available and it is analysed here.
Data
The data consists of information on the 3,238 features implemented by the 7digital team between April 2009 and July 2012; this information consists of three dates (Prioritised/Start Development/Done), a classification of the feature as one of nine possible internal types (i.e.,
During the recording period the number of developers grew from 14 to 35.
The start/done dates represent an elapsed time period, a wide variety of factors can cause work on the implementation of a feature to be stalled for a period of time, i.e., the time difference need not represent total development time.
The Agile process gives a great deal of flexibility to developers about which projects they chose to work on. Information on the number of developers working on the implementation of individual features was not recorded.
Is the data believable?
As discussed elsewhere [checking data quality] measurements involving people are likely to be subject more external influences than measurements of inanimate objects such as source code, they are also more difficult to replicate and are open to those being measured influencing the results in their favor.
The following is what is known about the 7digital measurement process.
The data recording was done by whoever ran the Agile stand-up session at the start of the day.
What unit of time measurement is appropriate for analysing an Agile process? While fine grained measurements are the ideal they have the potential to require nontrivial effort from those reporting the values, are open to individual interpretation (e.g., when exactly did work start/stop on this feature?) and subject to human error (e.g., forgetting to note the event when it happened and having to recall it later). The day was chosen as the basic unit of time measurement; in light of the time needed to implement most features this may seem too large, but this choice has the advantage of being the natural unit of measurement in that developers meet together every morning to discuss progress and that days work and being so broad makes it more likely that start/end times will be consistently applied as well as less prone to inaccurate recall later.
Goodhart’s law (it is really an observation of human behavior rather than a law) says “Any observed statistical regularity will tend to collapse once pressure is placed on it for control purposes.” If the measurements collected were actively used to control or evaluate the development team then the developers would be motivated to move the measurements in the direction that was favorable to them. 7digital do not attempt to use the measurements for control or evaluation or developers and developers have no motive change their behavior based on being measured.
I find the data believable in that the measurement process is not so expensive or cumbersome that developers are unwilling to attempt to report accurate data and not being directly effected by the results means they have no motive for changing their behavior to influence the measurements.
Believable data does not mean the data is error free. The following is a count of the days of the week on which feature implementations were recorded as being Done. Monday is day 0 and the counts for Saturday/Sunday should be zero; assuming that Friday/Monday had been intended the non-zero values suggest a 2-4% error rate, comparable with human error rates for low stress/non-critical work.
> table(Done.day[(Done.day <= 650)] %% 7) 0 1 2 3 4 5 6 227 225 214 243 177 8 7 > table(Done.day[(Done.day > 650)] %% 7) 0 1 2 3 4 5 6 443 483 455 473 270 4 9 |
Predictions made in advance
Your author is not aware of any empirically based theory of Agile feature development capable of making predictions about development time related questions.
The analysis described here is purely descriptive; there is no attempt to build predictive models or compare the data against any existing theory.
The results from this data analysis (and all analysis in this book) are to provide information that will help software developers do a better job. What information can be extracted that would be useful to 7digital? This has proved to be a something of a chicken-and-egg question because people are interested in seeing the results before deciding whether they are useful. The following issues are of general interest:
- characteristics of the time taken to implement new features,
- variations in the number of different kinds of features (e.g., bug/non-bug) over time,
Applicable techniques
Overview of data
The data consists of start/finish times for the implementations of features and the overview information that springs to mind is average number of features implementation starts per time interval and average time taken to implement a feature. The figure below is a good enough approximation to this information to get a rough idea of its characteristics (e.g., the effect of weekends and holidays have not been taken into account and a 30 day rolling mean has been applied to smooth out daily fluctuations).
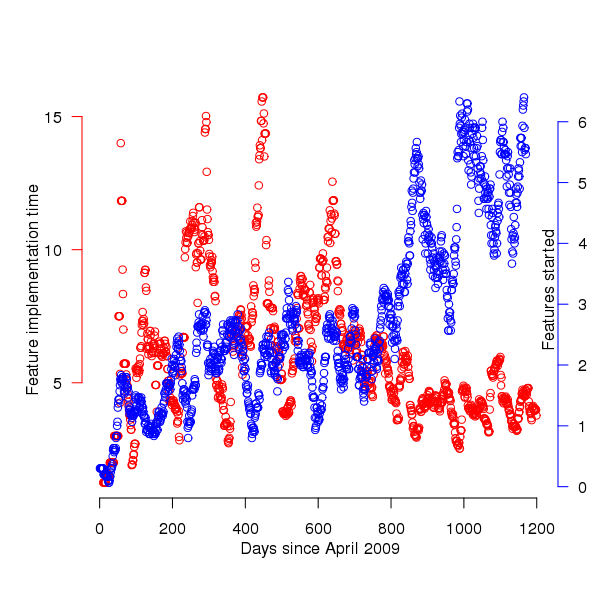
Figure 1. Average number of feature implementations started (blue) and their average duration (red); a 30 day rolling mean has been applied to both. Data courtesy of 7digital.
The plot appears to have two parts, before and after day 650 (or thereabouts). After day 650 the oscillations in feature implementation time die down substantially and the rate at which new feature implementations are started steadily increases. Possible reasons for the larger variations in the first 650 days include less expertise in organizing features into smaller work items and larger features being needed during the earlier stages of product development.
Obviously shorter implementation times make it possible to start work on more new features, however new feature starts continues to increase while implementation time stabilises around a lower value. Possible causes for the continuing increase in new feature starts include an increase in the number of developers and/or existing developers becoming more skilled in breaking work down into smaller features (i.e., feature implementation time stays about the same because fewer developers are working on each feature, making developers available to start on new features).
Software product development is a complicated business and a wide variety of different events and processes are likely to have contributed to the patterns of behavior seen in the data. While developers write the software it is customers who report most of the bugs and one of the goals of following an Agile methodology is rapid response to customer feedback (e.g., deciding which features need to be implemented and which left out). Customer information is not present in the dataset.
Are the same processes generating the apparent two phase behavior?
Any pattern of behavior is generated by a set of processes and when a pattern of behavior changes it is worthwhile asking how the processes driving the behavior changed.
Fitting a statistical distribution to a dataset is useful in that many distributions are known to be generated by processes having specified behaviors. Being able to fit the same distribution to both the pre and post 650 day datasets suggests that the phase change seen was not a fundamental change but akin to turning the volume knob of the distribution parameters one way or the other. If the datasets are best fitted by different distributions then the processes generating the two patterns of behavior are potentially very different.
Of the two characteristics plotted the feature implementation time appears to undergo the largest change of behavior and so the distribution of implementation times for the two phases is analysed here.
| Moment | Initial 650 days | After 650 days |
|---|---|---|
|
Median
|
3
|
3
|
|
Mean
|
7.6
|
4.6
|
|
Variance
|
116.4
|
35.0
|
|
Skewness
|
3.3
|
4.9
|
|
Kurtosis
|
19.2
|
30.4
|
A quick look at the data shows that many features are implemented in a single day and only a few take more than a week, one distribution having this pattern of behavior is the power-law. The table above shows that the variance is much larger than the mean and the distribution has a large positive skew, properties shared by the [negative binomial distribution]. The figure below is a plot of the number of features requiring a given number of elapsed working days for their implementation (top first 650 days, all features finished after 650 days), along with two power-law and a negative binomial distribution fit to the data.
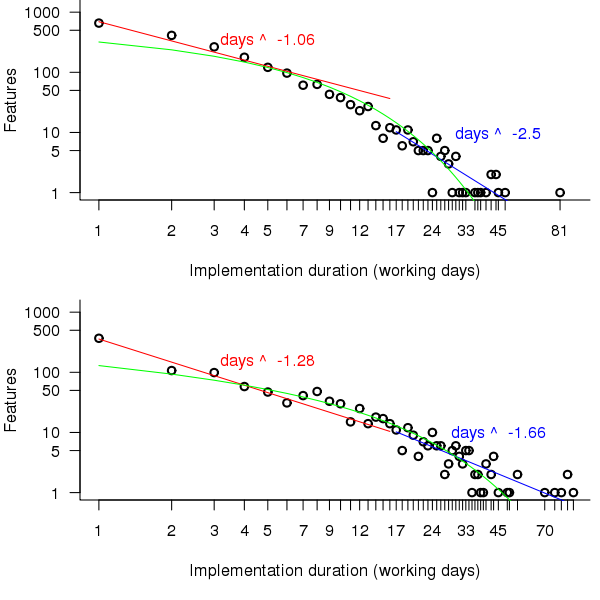
Figure 2. Number of features whose implementation took a given number of elapsed workdays. Top first 650 days, bottom after 650 days. Green line is the fitted negative binomial distribution. Data courtesy of 7digital.
The power-law fits were obtained by splitting the data into two parts, shorter/longer than 16 days (after noticing that visually the combined dataset seemed to have this form, less noticeable in the two subsets) and performing nonlinear regression using nls to find good fits for the parameters a and b (whose initial starting values converged without needing manual tuning).
pow_equ=nls(num.features ~ a*days^b, start=list(a=1200, b =-2)) y=predict(pow_equ, days) lines(days, y) |
While the power-law fits are not very good overall one of them does provide an easy to remember seat of the pants method for approximating the probability of a project taking a small number of days to complete (e.g., for  it is
it is 
[sum(1/(1:16)) is 3.38]). The approximation is also a reasonable fit for subsets of the features (e.g., different kinds of bugs).
The R package fitdistrplus contains functions for matching and fitting a dataset against known commonly occurring distribution. The Cullen and Frey graph produced by a call to descdist suggests that a negative binomial distribution is the best fitting of those tested (agreeing with the ad-hoc conclusion jumped to above).
descdist(p\$Cycle.Time, discrete=TRUE, boot=100) |
The function fitdist returns values for the parameters providing the appropriate fit to the specified dataset and distribution.
fd=fitdist(p\$Cycle.Time, "nbinom", method="mle") # Fit to a negative binomial distribution size.ct=fd\$estimate[1] mu.ct=fd\$estimate[2] # Plot distribution using fitted parameters plot(dnbinom(1:93, size=size.ct, mu=mu.ct)*length(p\$Cycle.Time), xlim=c(1,90), ylim=c(1,1200), log="xy") |
The figure above shows that the negative binomial distribution could be a reasonable fit if the percentage of single day features was not so high. Two possibilities spring to mind:
- the data does not include any counts for zero days which is one of the possible values supported by the negative binomial distribution (obviously feature implementations cannot take zero days),
- measurement quantization introduces significant uncertainty for shorter implementations, if the minimum unit of measurement were less than 1 day the fit might be much better because some feature implementations take half-a-day while others take a whole day.
It is possible to adjust the negative binomial equation to move the lower bound from zero to one. The package gamlss supports what is known as zero-truncation and the figure below shows the zero-truncated negative binomial distribution fitted to the pre/post 650 day counts.
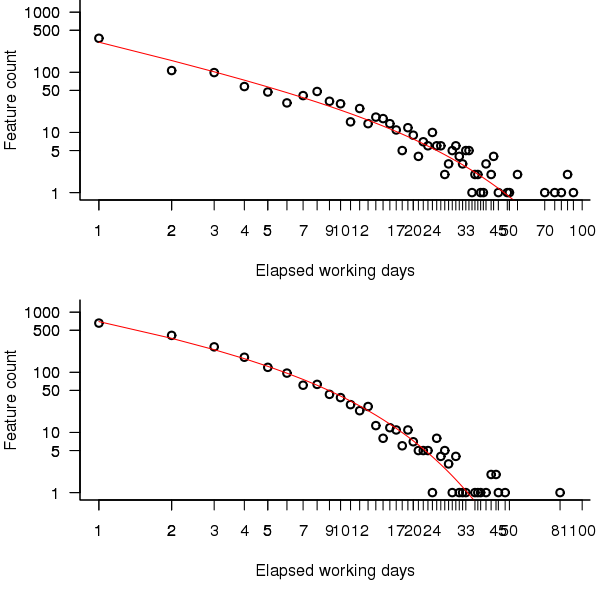
Figure 3. A zero-truncated negative binomial distribution fitted to the number of features whose implementation took a given number of elapsed workdays; top first 650 days, bottom after 650 days. Data courtesy of 7digital.
The quality of fit is much better for the pre 650 day data compared to the post 650 data.
> qual.pre650 AIC log.likelihood 6109.225 -3052.612 > qual.post650 AIC log.likelihood 9923.509 -4959.754 |
Modifying the negative binomial distribution to handle a dataset not containing zeroes improves the fit, can the fit be further improved by adjusting for measurement quantization?
One possibility is to simulate measuring feature implementation in units smaller than a day; the following code multiplies the implementation time by two and randomly decides whether to subtract one, i.e., maps measurements made in days to a possible set of measurements made in half days.
num.features=length(cycle.time) dither=as.integer(runif(num.features, 0, 1) > 0.33) return(2*cycle.time-dither) |
Fitting 1,000 randomly modified half-day measurements and averaging over all results shows that the fit is slightly worse than the original data (as measured by various goodness of fit criteria):
> fit.quality(p\$Cycle.Time[Done.day < 650]) loglikelihood AIC BIC -3438.284 6880.567 6890.575 > rowMeans(replicate(1000, fit.quality(sub.divide(p\$Cycle.Time[Done.day < 650])))) loglikelihood AIC BIC -4072.721 8149.442 8159.450 |
As discussed in the section on [properties of distributions] the negative binomial distribution can be generated by a mixture of [Poisson distribution]s whose means have a [Gamma distribution]. There are other distributions that can be generated through a mixture of Poisson distributions, are any of them a better fit of the data? The Delaporte distribution <book ???> sometimes fits very slightly better and sometimes slightly worse (see chapter source code for details); the difference is not large enough to warrant switching from a relatively well known distribution to one that is rarely covered in text books or supported in software; if data from other projects is best fitted by a Delaporte distribution then a switch may well be worthwhile.
The data subset corresponding to p$Type == "Production Bug" fits significantly better than the complete dataset (i.e., AIC = 3729) while the fit for the subset p$Type == "MMF" is comparable to the complete dataset (i.e., AIC of 7251).
Both datsets appear to follow the same distribution, the negative binomial distribution (with zero-truncation), with the initial 650 days having a greater mean and variance than post 650 days. The Poisson distribution is often encountered in processes involving events in time and one can imagine it applying to the various processes involved in the implementation of a feature; why the means of these Poisson distributions might follow a Gamma distribution is harder to fathom and is left for another day (it implies that both the Poisson means are decreasing and that the variance of the means is decreasing)
Do any other equations fit the data? Given enough optional parameters it is always possible to find an equation that is a good fit to the data. The following call to nls shows that the equation  fits the complete dataset rather well.
fits the complete dataset rather well.
exp_mod=nls(num.features ~ a*exp(b*days^c), start=list(a=10000, b=-2.0, c=0.4)) |
This equation is unappealing because of its lack of similarity with equations seen in many other areas of research, an exponential whose exponent has the form of  raised to a fractional power is rarely encountered. There is a great deal of uncertainty when analysing data for the first time and being able to fit a form of equation used by other researchers provides a big comfort factor.
raised to a fractional power is rarely encountered. There is a great deal of uncertainty when analysing data for the first time and being able to fit a form of equation used by other researchers provides a big comfort factor.
How many new feature implementations are started on each day?
The table below give the probability of a given number of new feature implementations starting on any day. There are sufficient multi-day implementations that on almost 20% of days no new feature implementations are started. An exponential equation is the commonly encountered form that provides an approximate fit to these values (i.e.,  ).
).
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
|
0.18
|
0.12
|
0.15
|
0.1
|
0.099
|
0.081
|
0.076
|
0.043
|
0.033
|
0.029
|
Time dependent patterns in the data
7digital is a growing company and we would expect that the rate of creation of features would increase over time, also as the size of the code base and the customer base increases the rate at which bugs are accepted for fixing is likely to increase.
The number of features developments started per day is one way of comparing different types of features. Plotting this information (see top left) shows that there is a great deal of variation over very short periods of time. This variation can be smoothed using a [rolling mean] to bring out the trends (the rollmean function in package zoo); the other plots show 20, 50 and 120 day rolling means for bugs (red) and non-bugs (blue) and the non-bug/bug feature ratio (black).
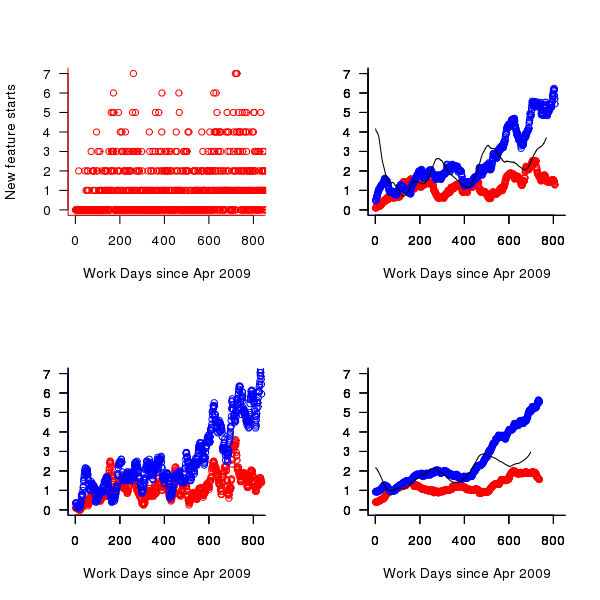
Figure 4. Number of feature developments started on a given work day (red bug fixes, blue non-bug work, black ratio of two values; 20 day rolling mean bottom left, 50 day top right, 120 day bottom right).
Both the number of bugs and non-bug features has trended upwards, as has the ratio between them. While it is tempting to suggest that this increase has been generated by the significant increase in number of developers over the time period, it is also possible the group has become better at dividing work into smaller feature work items or that having implemented the basic core of the products less work is now needed to create new features. The information present in the data is not sufficient to attempt to provide believable explanations for the upward trend.
Time series analysis
A preliminary data analysis technique for time data is to plot the current values against their lagged values for various lags. The output from the R function lag.plot for the number of in-progress features is shown below; apart from clustering the plots do not show any noticeable relationships in the data.
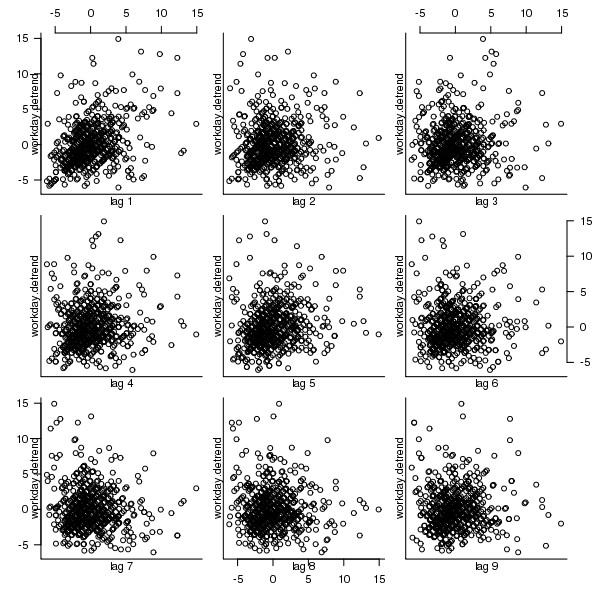
Figure 5. Scatterplot of number of features currently in-progress against various time lags (in working days).
Over longer timescales do the number of in-progress feature implementations have noticeable seasonal variations (e.g., greater in summer and Christmas/year year when developers are likely to be away)?
[Autocorrelation] is the cross-correlation of a time varying signal with itself, i.e., the correlation between a measurement occurring at time  and another one occurring at time
and another one occurring at time  ; changes in correlation as
; changes in correlation as  increases can be used to infer information about periodic changes over time.
increases can be used to infer information about periodic changes over time.
The number of in-progress features appears to be increasing over time (top left of figure below) and this trend away from zero needs to be adjusted for before an autocorrelation is calculated. The feature implementation recording process did not happen over night and took a while before it covered all work performed; comparing a linear fit of all data (pink line of top left of figure below) and all data from January 2010 (red line) shows that this startup period does not significantly bias the growth trend. However, it is possible that patterns of behavior present in the total set of work items over a period are not reflected in the first 250 days of recording (roughly 180 working days) and so these are excluded from this particular analysis. From feature duration measurements we know that over 70% of features take longer than a day to implement, so the data contains a lot of serial dependence which may affect the accuracy of the results.
trend=lm(day.totals ~ time(day.totals)) plot(day.totals, xlab="Days since Apr 2009", ylab="Features in-progress") abline(trend) day.detrend=day.totals - predict(trend) # Subtract out any global trend |
The bottom left of the figure below shows the variation of in-progress features about the trend line. The top right shows the autocorrelation function for this plot, the regular spikes are caused by weekends (when no work took place). Removing weekends from the analysis results in the autocorrelation shown in the bottom right.
Apart from some correlation having a one day lag the autocorrelation drops to zero almost immediately followed by what appear to be small random spikes. These small spikes do not look important enough to follow up. A very similar pattern is seen in the autocorrelation of the two 650-day phases (the initial 650 days has a larger correlation for lags of 2-5 days). It is possible that a seasonal oscillation in feature work exists but is not seen because the data is so noisy (i.e., contains significant variation between adjacent days).
Summing daily values to create weekly totals, which of provides some smoothing, and performing the above analysis again produces essentially the same results.
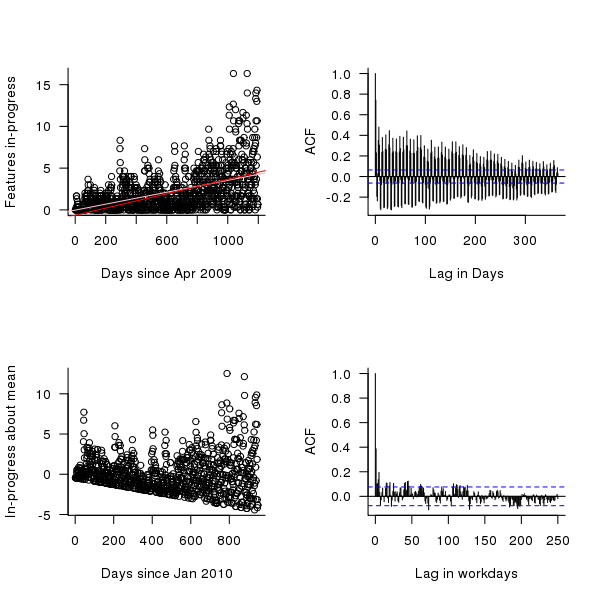
Figure 6. The number of features currently in-production on a given day since April 2009 (top left, pink line is a linear fit of all data, red line a linear fit of the data after day 250), the variation in this number about a linear trend line, excluding the first 250 days (bottom left), the autocorrelation function (top right) and the autocorrelation function with weekends removed from the data (bottom right).
Do reported bugs correlate with new feature releases?
When a feature is released the probability of a new bug being reported increases. Whether different bug probabilities should be assigned to bugfix releases and non-bugfix releases is discussed below. Based on this expectation we would expect to see a [cross correlation] between releases and number of bugs accepted for fixing. The more code a feature contains the more likely it is to contain a bug; however, no information on feature code size is provided so number of implementation work days is used as a measure of feature size.
The data does not specify which bugs belong to which features. It is to be expected that over time the probability of a bug being reported against a feature will decrease, reasons for this behavior include bugfixing, customers no longer using a feature and features being superseded by newer ones.
The figure below is the cross correlation between the ‘size’ of all features recorded as Done on a given day and all bugs recorded as Prioritised on a given date; the top plot is for all non-bugfix feature releases while the bottom plot is for all feature releases.
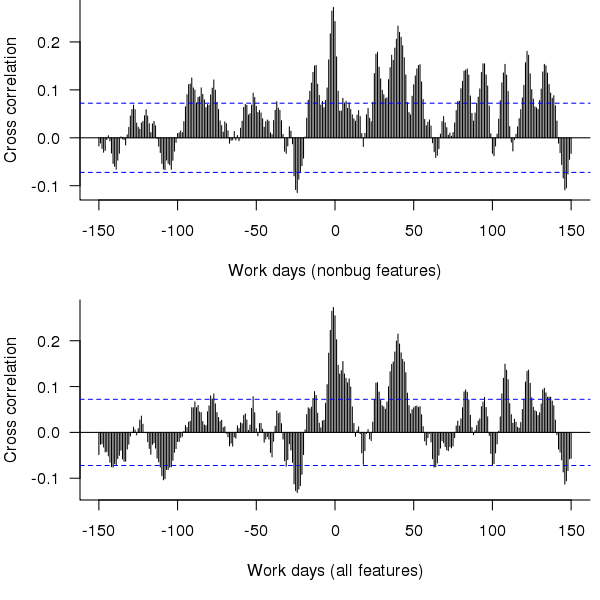
Figure 7. Cross correlation of feature release ‘size’ (top non-bugfix releases, bottom all releases) and date when bugs are prioritised.
The feature/bug cross correlation in the figure above should be zero for negative lags (i.e., no bugs can be reported for features that have not yet been released). One way of interpreting the pattern of correlation is that there some bugs are reported immediately after the release (perhaps by early adopters) followed by more bugs some 20 to 50 working days after release; other interpretations include there being a small amount of signal just visible behind lots of noise in the data or that the approximation used to estimate feature size is too crude.
Using weekly totals produces essentially the same result.
Summary of findings
The distribution of feature implementation times appears to follow a negative binomial distribution (with zero-truncation), with the values for the initial 650 days having a greater mean and variability (i.e., variance) than the following days.
There appears to be too much noise in the data for any time series signal involving mean values or a relationship between releases and bugs to be reliably extracted.
Acknowledgements
Thanks to 7digital for making the data available and being willing to make it public and to Rob Bowley for helping me to understand 7digital’s development environment.
Recent Comments