Archive
Correlation between risk attitude and willingness to refer back
What is the connection between a software developer’s risk attitude and the faults they insert in code they write or fail to detect in code they review? This is a very complicated question and in an experiment performed at the 2011 ACCU conference I investigated one particular instance; the connection between risk attitude and recall of previously seen information.
The experiment consisted of a series of problems having the same format (the identifiers used varied between problems). Each problem involved remembering information on four assignment statements of the form:
p = 6 ; b = 4 ; r = 9 ; k = 8 ; |
performing some other unrelated task for a short time (hopefully long enough for them to forget some of the information they had previously seen) and then having to recognize the variables they had previously seen within a list containing five identifiers and recall the numeric value assigned to each variable.
When reading code developers have the option of referring back to previously read code and this option was provided to subject. Next to each identifier listed in the recall part of the problem was space to write the numeric value previously seen and a “would refer back” box. Subjects were told to tick the “would refer back” box if, in real life” they would refer back to the previously seen assignment statements rather than rely on their memory.
As originally conceived this experimental format is investigating the impact of human short term memory on recall of previously seen code. Every time I ran this kind of experiment there was a small number of subjects who gave a much higher percentage of “would refer back” answers than the other subjects. One explanation was that these subjects had a smaller short term memory capacity than other subjects (STM capacity does vary between people), another explanation is that these subjects are much more risk averse than the other subjects.
The 2011 ACCU experiment was designed to test the hypothesis that there was a correlation between a subject’s risk attitude and the percentage of “would refer back” answers they gave. The Domain-Specific Risk-Taking (DOSPERT) questionnaire was used to measure subject’s risk attitude. This questionnaire and the experimental findings behind it have been published and are freely available for others to use. DOSPERT measures risk attitude in six domains: social, recreation, gambling, investing health and ethical.
The following scatter plot shows each (of 30) subject’s risk attitude in the six domains (x-axis) plotted against percentage of “would refer back” answers (y-axis).
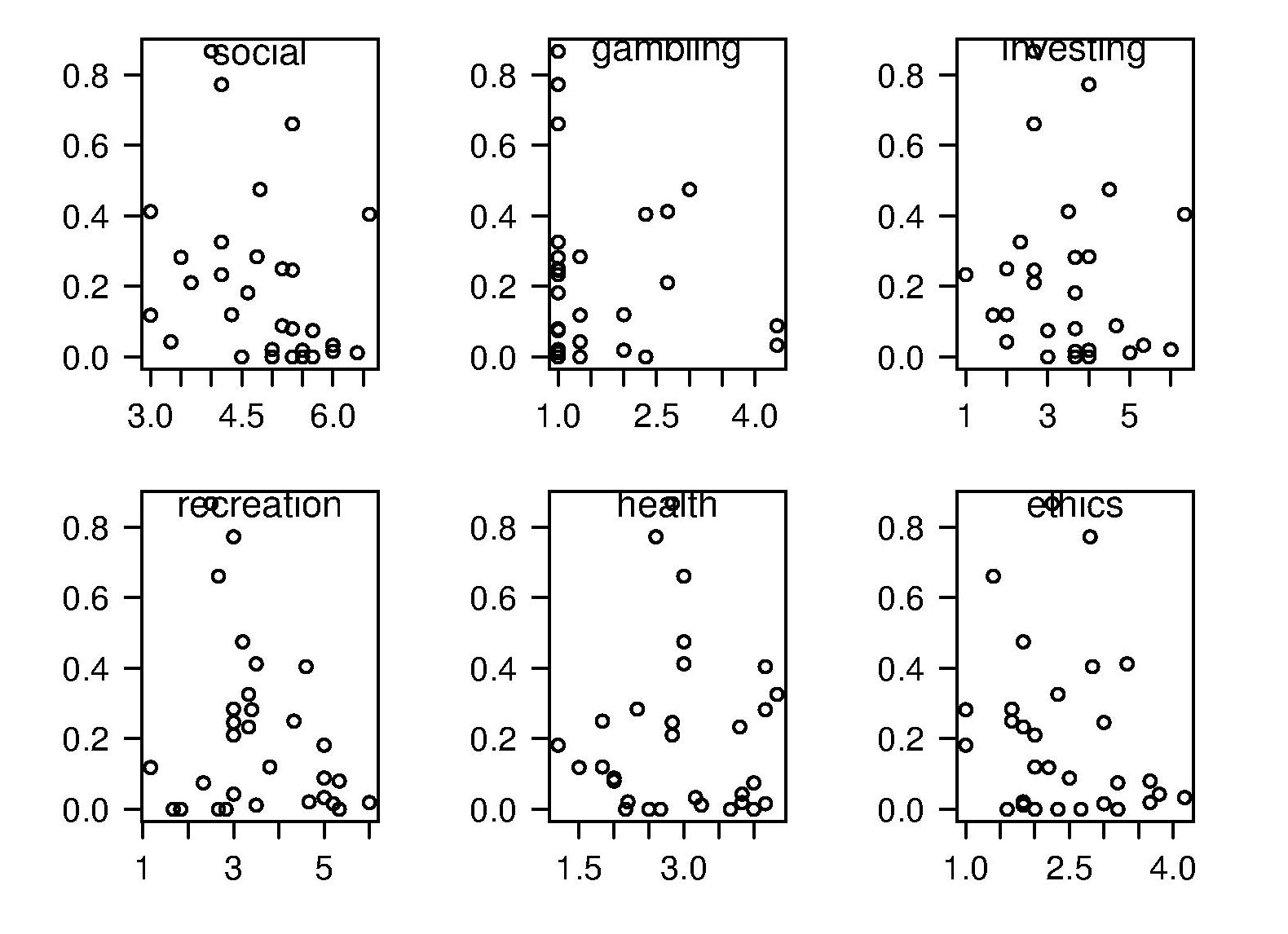
A Spearman rank correlation test confirms what is visibly apparent, there is no correlation between the two quantities. Scatter plots using percentage of correct answers and total number of questions answers show a similar lack of correlation.
The results suggest that risk attitude (at least as measured by DOSPERT) is not a measurable factor in subject recall performance. Perhaps the subjects that originally caught my attention (there were three in 2011) really do have a smaller STM capacity compared to other subjects. The organization of the experiment (one hour during a one lunchtime of the conference) does not allow for a more extensive testing of subject cognitive characteristics.
Relative spacing of operands affects perception of operator precedence
What I found most intriguing about Google Code Search (shutdown Nov 2011) was how quickly searches involving regular expressions returned matches. A few days ago Russ Cox, the implementor of Code Search not only explained how it worked but also released the source and some precompiled binaries. Google’s database of source code did not include the source of R, so I decided to install CodeSearch on my local machine and run some of my previous searches against the latest (v2.14.1) R source.
In 2007 I ran an experiment that showed developers made use of variable names when making binary operator precedence decisions. At about the same time two cognitive psychologists, David Landy and Robert Goldstone, were investigating the impact of spacing on operator precedence decisions (they found that readers showed a tendency to pair together the operands that were visibly closer to each other, e.g., a with b in a+b * c rather than b with c).
As somebody very interested in finding faults in code the psychologists research findings on spacing immediately suggested to me the possibility that ‘incorrectly’ spaced expressions were a sign of failure to write code that had the intended behavior. Feeding some rather complicated regular expressions into Google’s CodeSearch threw up a number of ‘incorrectly’ spaced expressions. However, this finding went no further than an interesting email exchange with Landy and Goldstone.
Time to find out whether there are any ‘incorrectly’ spaced expressions in the R source. cindex (the tool that builds the database used by csearch) took 3 seconds on a not very fast machine to process all of the R source (56M byte) and build the search database (10M byte; the Linux database is a factor of 5.5 smaller than the sources).
The search:
csearch "w(+|-)w +(*|/) +w" |
returned a few interesting matches:
... modules/internet/nanohttp.c: used += tv_save.tv_sec + 1e-6 * tv_save.tv_usec; modules/lapack/dlapack0.f: $ ( T*( ONE+SQRT( ONE+S / T ) ) ) ) modules/lapack/dlapack2.f: S = Z( 3 )*( Z( 2 ) / ( T*( ONE+SQRT( ONE+S / T ) ) ) ) modules/lapack/dlapack4.f: $ ( T*( ONE+SQRT( ONE+S / T ) ) ) ) |
There were around 15 matches of code like 1e-6 * var (because the pattern w is for alphanumeric sequences and that is not a superset of the syntax of floating-point literals).
The subexpression ONE+S / T is just the sort of thing I was looking for. The three instances all involved code that processed tridiagonal matrices in various special cases. Google search combined with my knowledge of numerical analysis was not up to the task of figuring out whether the intended usage was (ONE+S)/T or ONE+(S/T).
Searches based on various other combination of operator pairs failed to match anything that looked suspicious.
There was an order of magnitude performance difference for csearch vs. grep -R -e (real 0m0.167s vs. real 0m2.208s). A very worthwhile improvement when searching much larger code bases with more complicated patterns.
Recent Comments