Archive
Simple generator for compiler stress testing source
Since writing my C book I have been interested in the problem of generating source that has the syntactic and semantic statistical characteristics of human written code.
Generating code that obeys a language’s syntax is straight forward. Take a specification of the syntax (say is some yacc-like form) and ‘generate’ each of the terminals/nonterminals on the right-hand-side of the start symbol. Nonterminals will lead to rules having right-hand-sides that in turn need to be ‘generated’, a random selection being made when a nonterminal has more than one possible rhs rule. Output occurs when a terminal is ‘generated’.
For the code to mimic human written code it is necessary to bias the random selection process; a numeric value at the start of each rhs rule can be used to specify the percentage probability of that rule being chosen for the corresponding nonterminal.
The following example generates a subset of C expressions; nonterminals in lowercase, terminals in uppercase and implemented as a call to a function having that name:
%grammar first_rule : def_ident " = " expr " ;n" END_EXPR_STMT ; def_ident : MK_IDENT ; constant : MK_CONSTANT ; identifier : KNOWN_IDENT ; primary_expr : 30 constant | 60 identifier | 10 " (" expr ") " ; multiplicative_expr : 50 primary_expr | 40 multiplicative_expr " * " primary_expr | 10 multiplicative_expr " / " primary_expr ; additive_expr : 50 multiplicative_expr | 25 additive_expr " + " multiplicative_expr | 25 additive_expr " - " multiplicative_expr ; expr : START_EXPR additive_expr FINISH_EXPR ; |
A 250 line awk program (awk only because I use it often enough for simply text processing that it is second nature) translates this into two Python lists:
productions = [ [0], [ 1, 1, 1, # first_rule 0, 5, [2, 1001, 3, 1002, 1003, ], ], [ 2, 1, 1, # def_ident 0, 1, [1004, ], ], [ 4, 1, 1, # constant 0, 1, [1005, ], ], [ 5, 1, 1, # identifier 0, 1, [1006, ], ], [ 6, 3, 0, # primary_expr 30, 1, [4, ], 60, 1, [5, ], 10, 3, [1007, 3, 1008, ], ], [ 7, 3, 0, # multiplicative_expr 50, 1, [6, ], 40, 3, [7, 1009, 6, ], 10, 3, [7, 1010, 6, ], ], [ 8, 3, 0, # additive_expr 50, 1, [7, ], 25, 3, [8, 1011, 7, ], 25, 3, [8, 1012, 7, ], ], [ 3, 1, 1, # expr 0, 3, [1013, 8, 1014, ], ], ] terminal = [ [0], [ STR_TERM, " = "], [ STR_TERM, " ;n"], [ FUNC_TERM, END_EXPR_STMT], [ FUNC_TERM, MK_IDENT], [ FUNC_TERM, MK_CONSTANT], [ FUNC_TERM, KNOWN_IDENT], [ STR_TERM, " ("], [ STR_TERM, ") "], [ STR_TERM, " * "], [ STR_TERM, " / "], [ STR_TERM, " + "], [ STR_TERM, " - "], [ FUNC_TERM, START_EXPR], [ FUNC_TERM, FINISH_EXPR], ] |
which can be executed by a simply interpreter:
def exec_rule(some_rule) : rule_len=len(some_rule) cur_action=0 while (cur_action < rule_len) : if (some_rule[cur_action] > term_start_base) : gen_terminal(some_rule[cur_action]-term_start_base) else : exec_rule(select_rule(productions[some_rule[cur_action]])) cur_action+=1 productions.sort() start_code() ns=0 while (ns < 2000) : # Loop generating lots of test cases exec_rule(select_rule(productions[1])) ns+=1 end_code() |
Naive syntax-directed generation results in a lot of code that violates one or more fundamental semantic constraints. For instance the assignment (1+1)=3 is syntactically valid in many languages, which invariably specify a semantic constraint on the lhs of an assignment operator being some kind of modifiable storage location. The simplest solution to this problem is to change the syntax to limit the kinds of constructs that can be generated on the lhs of an assignment.
The hardest semantic association to get right is the connection between variable declarations and references to those variables in expressions. One solution is to mimic how I think many developers write code, that is to generate the statements first and then generate the required definitions for the appropriate variables.
A whole host of minor semantic issues require the syntax generated code to be tweaked, e.g., division by zero occurs more often in untweaked generated code than human code. There are also statistical patterns within the semantics of human written code, e.g., frequency of use of local variables, that need to be addressed.
A few weeks ago the source of Csmith, a C source generator designed to stress the code generation phase of a compiler, was released. Over the years various people have written C compiler stress testers, most recently NPL implemented one in Java, but this is the first time that the source has been released. Imagine my disappointment on discovering that Csmith contained around 40 KLOC of code, only a bit smaller than a C compiler I had once help write. I decided to see if my ‘human characteristics’ generator could be used to create a compiler code generator stress tester.
The idea behind compiler code generator stress testing is to generate a program containing some complicated sequence of code, compile and run it, comparing the value produced against the value that is supposed to be produced.
I modified the human characteristics generator to produce pairs of statements like the following:
i = i_3 * i_6 & i_2 << i_7 ; chk_result(i, 3 * 6 & 2 << 7, __LINE__); |
the second argument to chk_result is the value that i should contain (while generating the expression to assign to i the corresponding constant expression with the variables replaced by their known values is also created).
Having the compiler evaluate the constant expression simplifies the stress tester and provides another check that the compiler gets things right (or gets two different things wrong in the same way, in which case we probably don’t get to see any failure message). The first gcc bug I found concerned this constant expression (in fact this same compiler bug crops up with alarming regularity in the generated code).
As previously mentioned connecting variables in expressions to a corresponding definition is a lot of work. I simplified this problem by assuming that an integer variable i would be predefined in the surrounding support code and that this would be the only variable ever assigned to in the generated code.
There is some simple house-keeping that wraps everything within a program and provides the appropriate variable definitions.
The grammar used to generate full C expressions is 228 lines, the awk translator 252 lines and the Python interpreter 55 lines; just over 1% of Csmith in LOC and it is very easy to configure. However, an awful lot functionality needs to be added before it starts to rival Csmith, not least of which is support for assignment to more than one integer variable!
Quality comparison of floating-point maths libraries
What is the best way to compare the quality of floating-point math libraries (e.g., sin, cos and log)? The traditional approach for evaluating the quality of an algorithm implementing a mathematical function is based on mathematics; methods have been developed to calculate the maximum error between the calculated and the actual value. The answer produced by this approach does not say anything about how frequently this maximum error will occur, only that it occurs at least once.
The log (natural logarithm) is probably the most frequently used mathematical function and I decided to compare a few implementations; R statistical package version 2.11.1 and glibc (libm version 2.11.2) both running under Suse 11.3 on an AMD Athlon 64 X2, and Cygwin version 1.7.1 under Windows XP SP 2 on another AMD Athlon 64 X2.
The algorithm often used to implement mathematical functions involves evaluating a polynomial expression (e.g., Chebyshev polynomials) within a small range of values (various methods are used to map the argument into this range and then scale the calculated result). I decided to initially treat the implementations under test as black boxes and did not know the ranges they used; a range of 0.1 to 1.0 seemed like a good idea and I generated all single precision floating-point values between these two bounds (all 28,521,267 of them, with each adjacent pair still having  double precision values between them).
double precision values between them).
#include <math.h> #include <stdio.h> int main(int argc, char *argv[]) { float val = 0.1, max_val = 1.0; while (val < max_val) { printf("%12.10f\n", val); val=nextafterf(val, 1.1); } } |
This list of 28 million values was fed as input to three programs:
- bc, which was used to generate the list of assumed to be correct logarithm of these 28 million values. R supports 64-bit IEEE compliant floating-point values, as do the C compilers/libraries used, and the number of decimal digits supported in this representation is 15. To provide greater accuracy to compare against the values generated by bc contained 17 digits, an extra two decimal digits over the IEEE values.
scale=17 while ((val=read() > 0)) l(val)
- A C program.
#include <math.h> #include <stdio.h> int main(int argc, char *argv[]) { double val; while (!feof(stdin)) { scanf("%lf", &val); printf("%17.15f\n", log(val)); } }
- A R program.
base_range=file("stdin", open="r") base_val=as.numeric(readLines(base_range, n=1)) while (length(base_val) != 0) { cat(format(log(base_val), nsmall=15), file=stdout()) cat("\n", file=stdout()) base_val=as.numeric(readLines(base_range, n=1)) }
The output of the C and R programs was then compared against the output from bc; which unfortunately creates a dependency on the accuracy of the C & R binary to decimal output routines (the subsequent comparison process gets around the decimal-to-binary input problem by reading the log values as strings and comparing the last few digits of each respective value). Accurate floating-point I/O needs something like hexadecimal floating constants.
Plotting the number of computed values of log that differ by a given amount from the value computed by bc, we get (values whose error is below -50 will be rounded down and those above 50 rounded up, ignoring the issue of round to even):
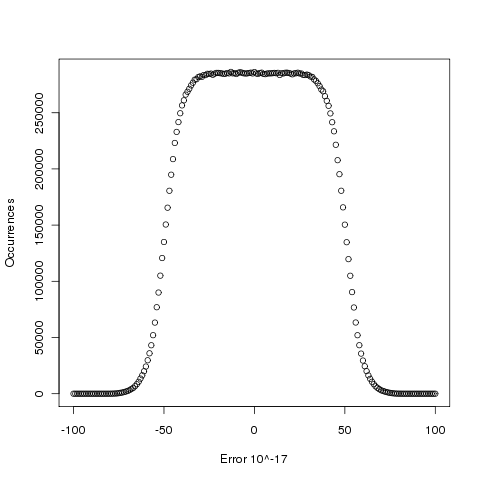
The results (raw data for R, Linux C and Cygwin C) show that around 5.6% of values are off by one in the last (15th) digit (Cygwin was slightly worse at 5.7%). The results for R/Linux C were almost identical and a quick check of the R source tree showed that R calls the C library function to evaluate log (it is a bit worrying that R is dependent on the host maths library, they should think about replacing this dependency by something like MPFR tout suite; even though the 64-bit glibc library is of very high quality it still has an environmental dependency).
Being off by one in the last decimal place is unlikely to keep many people awake at night. But if we want a measure of quality, is percentage of inaccurate values a useful measure of math library quality? Provided it is coupled with the amount of inaccuracy, I think this is a useful measure.
Recent Comments