Hexadecimal usage in Google’s scanned books
After investigating programming language name usage in Google’s ngram viewer, I decided to try something more specific. Hexadecimal literals are an interesting subproblem in optical character recognition; a little uncertainty in an image can result in a character sequence being equally viable as a word or a hexadecimal literal.
I downloaded all the Google books 1-grams and started to experiment. I eventually considered any character sequence matching the pattern ^[0oO][xX][0-9a-fA-FoOl] for further analysis; that is ohh, Ohh and ell were treated as the corresponding digits.
This prefix matching reduced 473 million possibilities down to 89 thousand.
Next any character sequence containing a non-hex character (again ohh, Ohh and ell were treated as special cases) was removed, bringing the possibilities down to 20 thousand.
When did the first hexadecimal literal appear in print? I settled on a generous view of history, 1945; also the sequence oxo seemed surprisingly common and looking at a few of the contexts in which it occurred I decided that most of the usage related to chemical formula and removed all matches. The post-1945 and oxo checks removed a third of remaining character sequences.
It seems to me that if any hexadecimal literal appears in a book, at least one more is likely to occur. Google does not provide a breakdown of each character sequence by book; for a given character sequence, the total count for each year is given, along with the number of pages it occurred on in that year and the number of different books it appeared within in the year. If the number of occurrences of a character sequence in a given year equalled the number of different books I excluded the usage count; this reduced the number of matches from 13,729 to 7,292; with 319 unique character sequences.
Are the remaining of character sequences a reasonably accurate list of hexadecimal literals appearing in the books that Google has scanned? Is 0.15 hexadecimal literals per million words a reasonable value?
A while back, I did some analysis of C source usage that included checking whether integer literals followed Benford’s law. Extracting the first non-zero digit from the character sequences extracted from Google books and comparing them with the C source hexadecimal data we get:
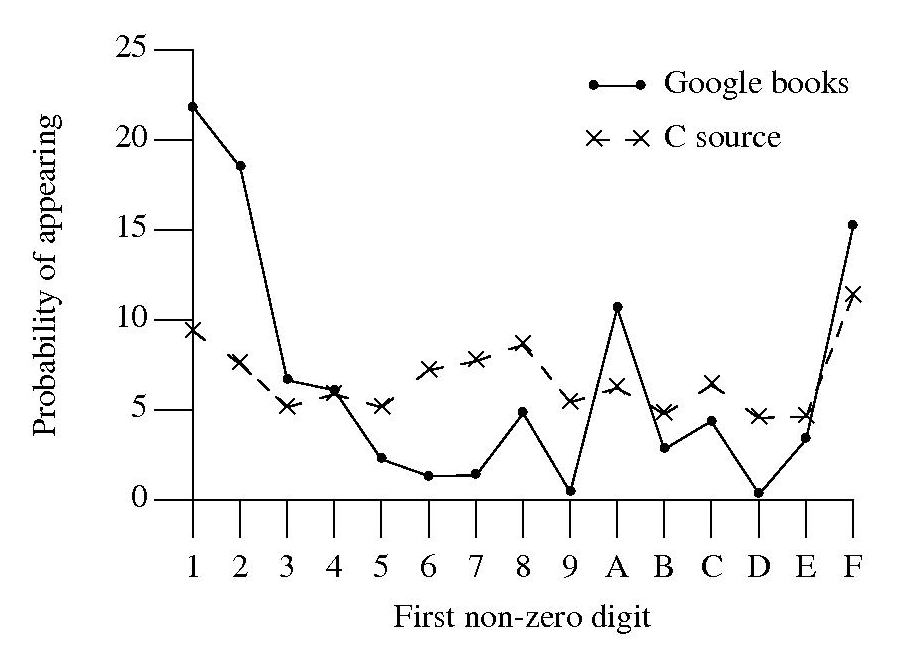
Both plots share ‘spikes’ at five values, but the pattern of relative sizes is different. Perhaps the pattern of hexadecimal literal usage in C source is slightly different from what occurs in other languages, or perhaps the relatively large percentage of 1 occurs because ell is accepted.
The context in which a character sequenced occurred would probably be a very good indicator of whether it was a hexadecimal literal or not. Google only provide a subset of their 2-grams and any analysis of these will have to wait for another time; however I did quickly check to see whether the OCR process had resulted in a single literal being split into two separate sequences, a manual check of the 95 possible sequences I found showed that most were not good candidates for a split literal.
The final list of ‘hexadecimal literal’s and their occurrence counts is available for download.
Recent Comments