Archive
Hexadecimal usage in Google’s scanned books
After investigating programming language name usage in Google’s ngram viewer, I decided to try something more specific. Hexadecimal literals are an interesting subproblem in optical character recognition; a little uncertainty in an image can result in a character sequence being equally viable as a word or a hexadecimal literal.
I downloaded all the Google books 1-grams and started to experiment. I eventually considered any character sequence matching the pattern ^[0oO][xX][0-9a-fA-FoOl] for further analysis; that is ohh, Ohh and ell were treated as the corresponding digits.
This prefix matching reduced 473 million possibilities down to 89 thousand.
Next any character sequence containing a non-hex character (again ohh, Ohh and ell were treated as special cases) was removed, bringing the possibilities down to 20 thousand.
When did the first hexadecimal literal appear in print? I settled on a generous view of history, 1945; also the sequence oxo seemed surprisingly common and looking at a few of the contexts in which it occurred I decided that most of the usage related to chemical formula and removed all matches. The post-1945 and oxo checks removed a third of remaining character sequences.
It seems to me that if any hexadecimal literal appears in a book, at least one more is likely to occur. Google does not provide a breakdown of each character sequence by book; for a given character sequence, the total count for each year is given, along with the number of pages it occurred on in that year and the number of different books it appeared within in the year. If the number of occurrences of a character sequence in a given year equalled the number of different books I excluded the usage count; this reduced the number of matches from 13,729 to 7,292; with 319 unique character sequences.
Are the remaining of character sequences a reasonably accurate list of hexadecimal literals appearing in the books that Google has scanned? Is 0.15 hexadecimal literals per million words a reasonable value?
A while back, I did some analysis of C source usage that included checking whether integer literals followed Benford’s law. Extracting the first non-zero digit from the character sequences extracted from Google books and comparing them with the C source hexadecimal data we get:
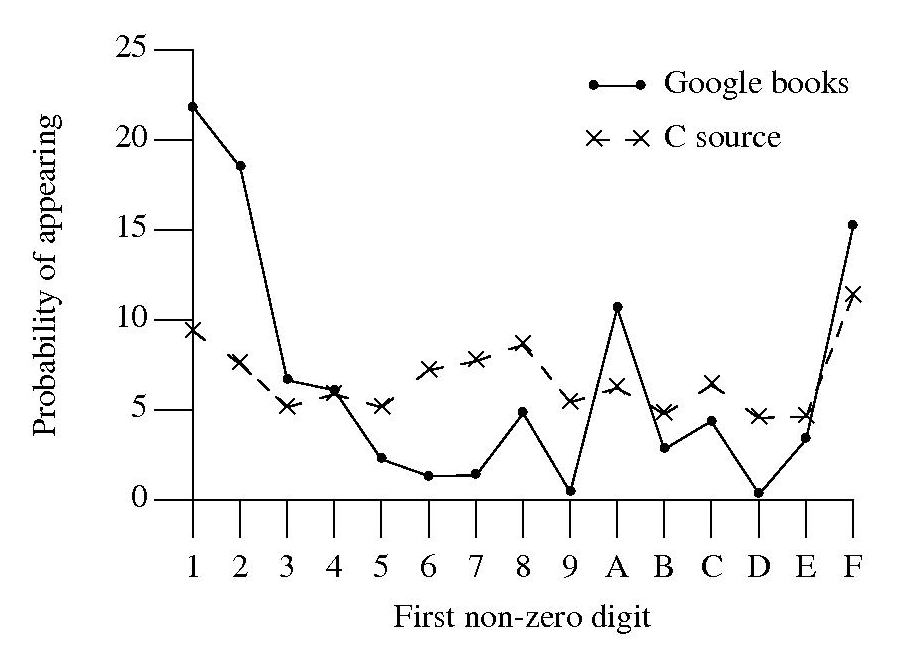
Both plots share ‘spikes’ at five values, but the pattern of relative sizes is different. Perhaps the pattern of hexadecimal literal usage in C source is slightly different from what occurs in other languages, or perhaps the relatively large percentage of 1 occurs because ell is accepted.
The context in which a character sequenced occurred would probably be a very good indicator of whether it was a hexadecimal literal or not. Google only provide a subset of their 2-grams and any analysis of these will have to wait for another time; however I did quickly check to see whether the OCR process had resulted in a single literal being split into two separate sequences, a manual check of the 95 possible sequences I found showed that most were not good candidates for a split literal.
The final list of ‘hexadecimal literal’s and their occurrence counts is available for download.
ISO Standards, the beauty and the beast
Standards is one area where a monopoly can provide a worthwhile benefit. After all the primary purpose of a standard for something is having just the one document for everybody to follow (having multiple standards because they are so useful is not a good idea). However, a common problem with monopolies is that charge a very inflated price for their product.
Many years ago the International Standard Organization settled on a pricing scheme for ISO Standards based on document page count. Most standards are very short and have a very small customer base, so there is commercial logic to having a high cost per page (especially since most are bought by large companies who need a copy if they do business in the corresponding application domain). Programming language standards do not fit this pattern, often being very long and potentially having a very large customer base.
With over 18,500 standards in their catalogue ISO might be forgiven for overlooking the dozen or so language standards, or perhaps they figured there is as much profit in charging a few hundred pounds on a few sales as charging less on more sales.
How does the move to electronic distribution effect prices? For a monopoly electronic distribution is an opportunity to make more profit, not to reduce prices. The recently published revision of the Fortran Standard is available for 338 Swiss francs (around £232) from ISO and £356 from BSI (at $351 the price from ANSI in the US is similar to ISO’s). Many years ago, at the dawn of the Internet, members of the US C Standard committee were able to convince ANSI to sell electronic copies at a reasonable rate ($30) and this practice has continued ever since (and now includes C++).
The market for the C and C++ Standards is sufficiently large that a commercial publisher (Wiley) was willing to take the risk of publishing them in book form (after some prodding and leg work by the likes of Francis Glassborow). It will be interesting to see if a publisher is willing to take a chance on a print run of the revised C Standard due out in a few years (I think the answer for the revised C++ Standard is more obvious).
Don’t Standards bodies care about computer languages? Unfortunately we are thorn in their side and they would be happy to be rid of us (but their charter’s do not allow them to do this). Our standards take much longer to produce than other standards, they are large and sales are almost non-existent (at ISO/BSI prices). What is more many of those involved in creating these standards actively subvert ISO/BSI sales by making draft documents, that are very close to the final copyrighted versions, freely available over the Internet.
In a sense ISO programming language standards exist because the organizational structure requires them to accept our work proposals and what we do does not have a large enough impact within the standards world for them to try and be rid of those tiresome people whose work is so far removed from what everybody else does.
Recent Comments