Archive
SQL usage: schema evolution
My first serious involvement with SQL, about 15 years ago, was writing a parser for the grammar specified in the ISO SQL-92 Standard. One of the things that surprised me about SQL was how little source code was generally available (for testing) and the almost complete lack of any published papers on SQL usage (its always better to find out about where the pot-holes are from other peoples’ experience).
The source code availability surprie is largely answered by the very close coupling between source and data that occurs with SQL; most SQL source is closely tied to a database schema and unless you have a need to process exactly the same kind of data you are unlikely to have any interest having access to the corresponding SQL source. The growth in usage of MySQL means that these days it is much easier to get hold of large amounts of SQL (large is a relative term here, I suspect that there are probably many orders of magnitude fewer lines of SQL in existence than there is of other popular languages).
In my case I was fortunate in that NIST released their SQL validation suite for beta testing just as I started to test my parser (it had taken me a month to get the grammar into a manageable shape).
Published research on SQL usage continues to be thin on the ground and I was pleased to recently discover a paper combining empirical work on SQL usage with another rarely researched topic, declaration usage e.g., variables and types or in this case schema evolution (for instance, changes in the table columns over time).
The researchers only analyzed one database, the 171 releases of the schema used by Wikipedia between April 2003 and November 2007, but they also made their scripts available for download and hopefully the results of applying them to lots of other databases will be published.
Not being an experienced database person I don’t know how representative the Wikipedia figures are; the number of tables increased from 17 to 34 (100% increase) and the number of columns from 100 to 242 (142%). A factor of two increase sounds like a lot but I suspect that all but one these columns occupy a tiny fraction of the 14GB that is the current English Wikipedia.
Program optimization given 1,000 datasets
A recent paper reminded me of a consequence of widespread availability of multi-processor systems I had failed to mention in a previous post on compiler writing in the next decade. The wide spread availability of systems containing large numbers of processors opens up opportunities for both end users of compilers and compiler writers.
Some compiler optimizations involve making decisions about what parts of a program will be executed more frequently than other parts; usually speeding up the frequently executed at the expense of slowing down the less frequently executed. The flow of control through a program is often effected by the input it has been given.
Traditionally optimization tuning has been done by feeding a small number of input datasets into a small number of programs, with the lazy using only the SPEC benchmarks and the more conscientious (or perhaps driven by one very important customer) using a few more acquired over time. A few years ago the iterative compiler tuning community started to address this lack of input benchmark datasets by creating 20 datasets for each of their benchmark programs.
Twenty datasets was certainly a step up from a few. Now one group (Evaluating Iterative Optimization Across 1000 Data Sets; written by a team of six people) has used 1,000 different input data sets to evaluate the runtime performance of a program; in fact they test 32 different programs each having their own 1,000 data sets. Oh, one fact they forgot to mention in the abstract was that each of these 32 programs was compiled with 300 different combinations of compiler options before being fed the 1,000 datasets (another post talks about the problem of selecting which optimizations to perform and the order in which to perform them); so each program is executed 300,000 times.
Standing back from this one could ask why optimizers have to be ‘pre-tuned’ using fixed datasets and programs. For any program the best optimization results are obtained by profiling it processing large amounts of real life data and then feeding this profile data back to a recompilation of the original source. The problem with this form of optimization is that most users are not willing to invest the time and effort needed to collect the profile data.
Some people might ask if 1,000 datasets is too many, I would ask if it is enough. Optimization often involves trade-offs and benchmark datasets need to provide enough information to compiler writers that they can reliably tune their products. The authors of the paper are still analyzing their data and I imagine that reducing redundancy in their dataset is one area they are looking at. One topic not covered in their first paper, which I hope they plan to address, is how program power consumption varies across the different datasets.
Where next with the large multi-processor systems compiler writers now have available to them? Well, 32 programs is not really enough to claim reasonable coverage of all program characteristics that compilers are likely to encounter. A benchmark containing 1,000 different programs is the obvious next step. One major hurdle, apart from the people time involved, is finding 1,000 programs that have usable datasets associated with them.
Language usage in Google’s ngram viewer
I thought I would join the fun that people are having with Google’s new ngram viewer. The raw data (only a subset for bigrams and longer ngrams) was also enticing, but at 35+ gigabytes for the compressed 1/2/3-grams of English-all I decided to forgo the longer n-grams.
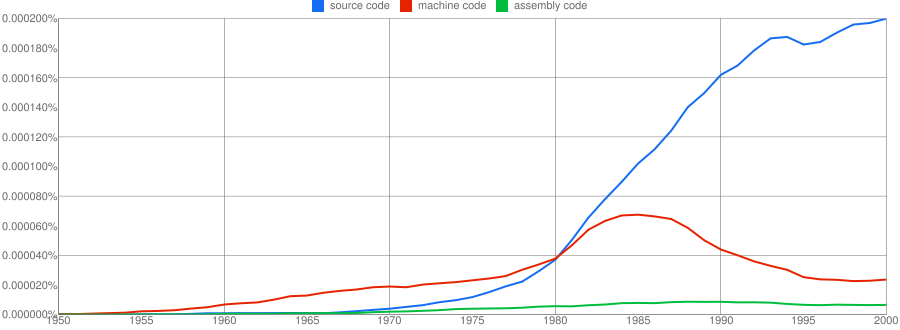
We all know that in the dim and distant past most programmers wrote in machine code, but it was not until 1980 that “source code” appeared more frequently in books that “machine code”.
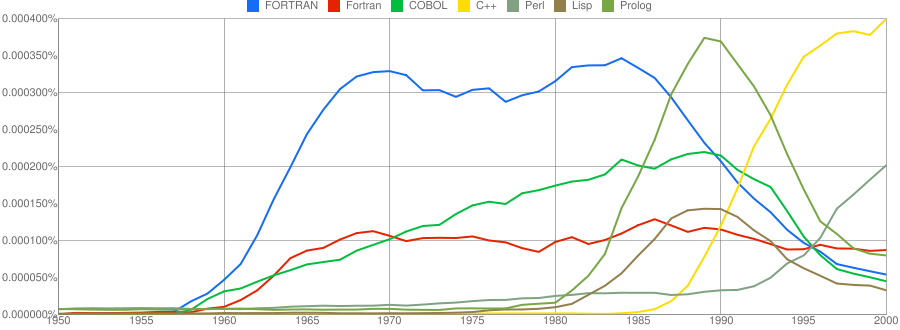
Computer language popularity is a perennial question. Fortran and Cobol address very different markets and I would have expected their usage to follow similar patterns, with “COBOL” having the obvious usage pattern for them both to follow. Instead, both “FORTRAN” and “Fortran” peaked within 10 years, with one staying there for another 20 years before declining and the other still going strong in 2000 (and still ahead of “PHP” and “Python” in 2000; neither shown to keep the clutter down). I am surprised to see “Prolog” usage being so much greater than “Lisp” and I would have expected “Lisp” to have a stronger presence in the 1970s.
I think the C++ crowd will be surprised to see that in 2000 usage was not much greater than what “FORTRAN” had enjoyed for 20 years.
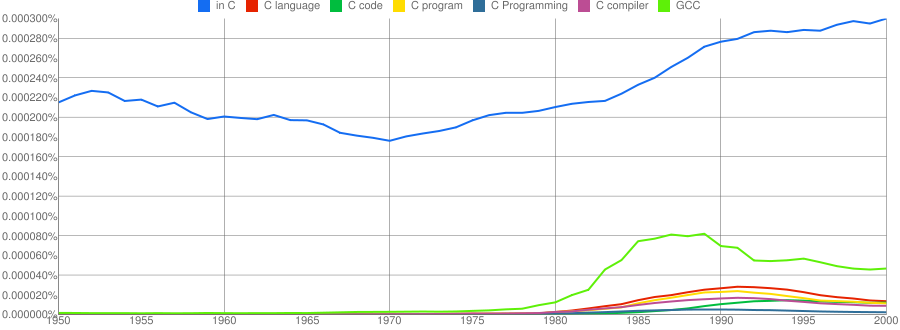
“C”, as in language, usage is obviously different to reliably measure. I have tried the obvious bigrams. Looking at some of the book matches for the phrase “in C” shows that the OCR process has sometimes inserted spaces that probably did not exist in the original, the effect being to split words and create incorrect bigrams. The phrase “in C” would also appear in books on music.
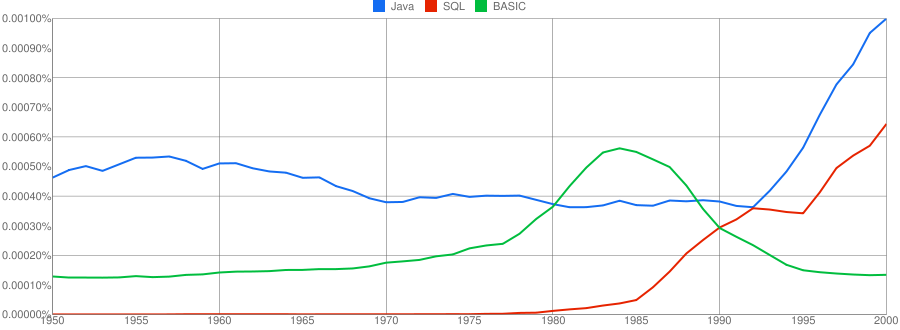
I have put the three words “Java”/”SQL”/”BASIC” in a separate plot because their usage swamps that of the other languages. Java obviously has multiple non-computer related uses and subtracting the estimated background usage suggests a language usage similar to that of “SQL”. There is too much noise for the usage of “Basic” to tell us much.
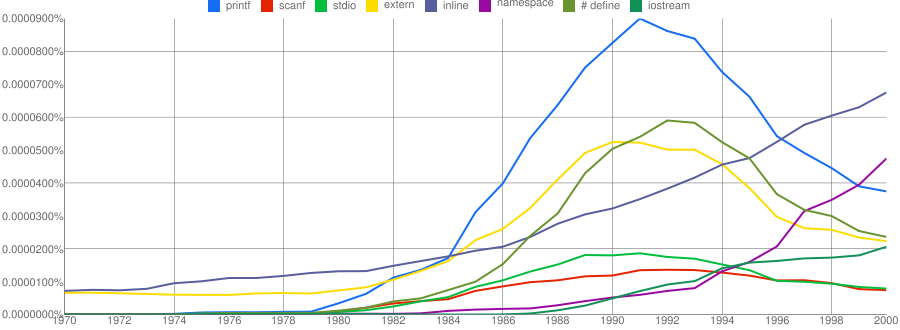
One way of comparing C/C++ language usage is to look source code usage where they are likely to differ. I/O, in the form of printf/scanf and stdio/iostream, is one obvious choice and while the expected C usage starts to declines in the 1990s the C++ usage just shows a stead growth (perhaps the <</>> usage, which does not appear in the Google viewer, has a dramatic growth during this time period).
Surprisingly #define also follows a similar pattern of decline. Even allowing for the rabid anti-macro rhetoric of the C++ in-crowd I would not have expected such a rapid decline. Perhaps this is some artifact of the book selection process used by Google; but then "namespace" shows a healthy growth around this time period.
The growth of "inline" over such a long period of time is a mystery. Perhaps some of this usage does not relate to a keyword appearing within source code examples but to text along the lines of "put this inline to make it faster".
What usage should we expect for the last decade? A greater usage of "PHP" and "Python" is an obvious call to make, along with the continuing growth of SQL, I think "UML" will also feature prominently. Will "C++" show a decline in favor or "Java" and what about "C#"? We will have to wait and see.
Recent Comments