Archive
Two models of developer response to false positive warnings
Static analysis tools sometimes fail to warn about a problem in the source and sometimes generate a warning for perfectly correct code (so called false positives). Experience shows that false positive warnings are very unpopular with developers (they are a source of wasted effort) and if too many false positive warnings are encountered a developer will often stop using the tool; developer’s are more likely to consider a lack of warnings as a positive indicator of the quality of their code than a failure of the tool to detect a problem, of course failure to detect problems may result in a poor evaluation and a lost sale.
What percentage of false positive warnings can a static analysis tool generate before a developer is likely to stop using it?
The following are two possible developer mental models that can be used to help answer this question (it is assumed that there is no correlation between warning occurrences and developers do not differentiate on the type of construct being warned about):
- a ‘rational’ developer who tracks the benefit of processing each warning (e.g., correct warning +1 benefit, false positive warning -1 benefit), starting in an initial state of zero benefit this rational developer stops processing warnings if the current sum of benefits ever goes negative.

The Ballot theorem can be used here. Let
Cbe the number of correct warnings andFbe the number of false positive warnings and assumeC > F. The probability that in a sequential count of warnings the number of correct warnings is always greater than the number of false positive warnings is:
rewriting in terms of probability of the two kinds of warning we get:

so, for instance, the probability of processing all the warning generated by a tool is 0.5 when the false positive rate is 0.25 and does not depend on the total number of warnings that have to be processed.
- a ‘short-termist’ developer who processes each warning and stops when a sequence of
Nconsecutive false positive warnings have been encountered. This kind of thinking is analogous to that of the hot hand in sports (what psychologists call the clustering illusion)
What is the probability that a sequence of
Nconsecutive false positive warnings is not encountered? Feller provides one solution (see equations 12 & 13 on Mathworld) but equation 2 on mathpages is easier to work with and was used to produce the following graph: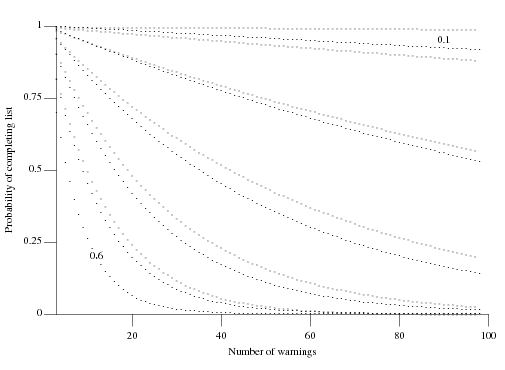
which plots the probability of not encountering a sequence of
Nconsecutive false positive warnings (dotsN=3, crossesN=4) after having processed a given number of warning messages for various underlying rates of false positive (ranging from 0.6 to 0.1 in increments of 0.1).
These models are both based on the false positive rate as judged by the developer, which need not reflect reality. For instance, when dealing with warnings involving complex constructs a developer may be unwilling to put the effort into understanding what is going on and either go along with the what the static analysis tool says, thus underestimating the actual false positive rate, or default to assuming the waring is a false positive, thus overestimating the actual false positive rate.
I have been meaning to write about this topic for a while and an email from Paul Anderson galvanized me into action. Paul’s email involved a slightly different issue “… if the human has seen lots of false positives, there is an increased probability that a true positive will be misjudged as a false positive.”
In some companies developers are required to process each message generated by a tool. Now if a developer looses confidence in a tool it would look suspicious if at some point they simply flagged all subsequent warnings as false positives. What algorithm might such developers use to ‘recalibrate’, e.g., skipping over the next M warnings? This sounds like a problem in foraging theory and a possible topic for a future post.
Network protocols also evolve into a tangle of dependencies
Four years ago I started work as an adviser to the Monitoring Trustee appointed by the European Commission in the EU/Microsoft competition court case. The work revolved around the protocol specification documents being written by Microsoft; at the time these documents were super secret but they are now publicly available for download.
The EU case involved the server protocols, known as WSPP, (the US/Microsoft case involved the client protocols) and with so many of them, over 100, attempts were made to divide them into distinct subsets for licensing to third parties who might only be interested in specific functionality.
On starting one of the first things I did was to create a graph like the one below (this one was created by extracting document cross reference information, using PowerGREP, from the public specifications and plotting it using Graphviz). Each line in the plot represents a dependency between the two protocols whose name’s appear in the ellipsoid nodes (actually a cross reference link in the normative sections of one protocol document to another protocol document).
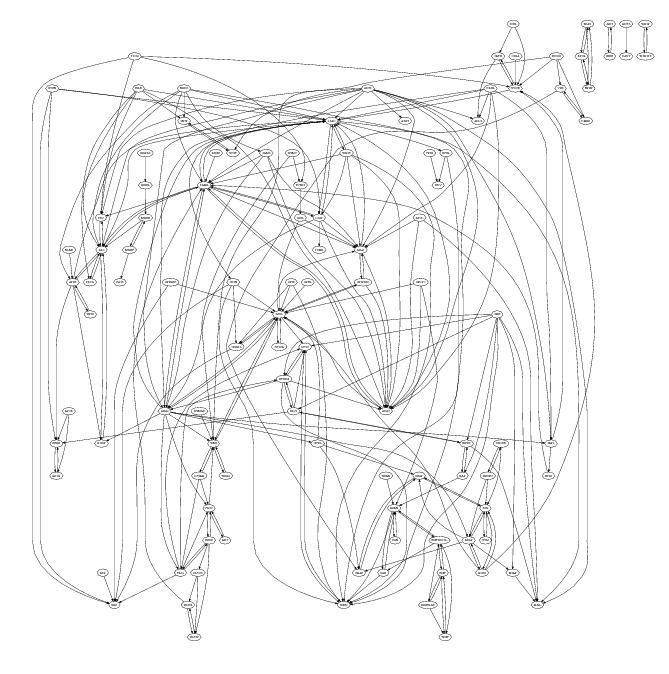
To simplify the diagram references to the ten most referenced protocol documents (i.e., MS-RPCE, MS-ADTS, MS-SMB, MS-KILE, MS-NLMP, MS-SPNG, MS-NRPC, MS-DRSR, MS-DCOM and MS-ADSC) have been excluded. The fact that these protocols are so pervasive is a good indicator of their core importance.
I was not surprised when I saw this graph. When new protocols were added to WSPP it would make sense for developers to make use of functionality provided by existing protocols, creating a dependency.
This extent of the dependencies between these protocol creates advantages and disadvantages for Microsoft. One advantage is that a potential competitor has to make a huge investment in implementing everything (so huge I don’t expect anybody will do it; Samba are nibbling away on a tiny corner); it does not look like its possible to focus on just the most profitable ones. One disadvantage is that these dependencies will make it very difficult for Microsoft to make substantive changes to their protocols.
Do other collections of networking protocols have similar amounts of dependencies between protocols? I don’t know of any analysis that attempts to answer this question. One problem with analyzing the so called ‘open’ protocols like the RFCs is that the quality of the documentation is not that good, with developers often relying on the source code of existing implementations to fill in any missing details.
Any technical benefits to C++ in a C project?
If you are running a large project written in C and it is decided that in future developers will be allowed to use C++, are there any C++ constructs whose use should be recommended against?
The short answer is that use of any C++ construct in existing C code should be recommended against.
The technical advantages of using C++ come about through use of its large scale code organizational features such as namespaces, classes and perhaps templates. Unless an existing C code base is restructured to use these constructs there is no real technical benefit for moving to C++; there may be non-technical reasons for allowing C++, as I wrote about recently.
My experience of projects where developers have been given permission to start using C++ within an existing C code base has not been positive. Adding namespaces/classes is a lot of work and rarely happens until a major rewrite; in the meantime C++ developers use new instead of malloc (which means the code now has to be compiled by a C++ compiler for a purely trivial reason). In days of old // style comments were sometimes touted as a worthwhile benefit of using C++ (I kid you not; now of course supported by most C compilers), as was the use of inline (even though back then few C++ compilers did much actual inlining), and what respectable programmer would use a C printf when C++’s iostreams provided << (oh, if only camera phones had been available back in the day, what a collection of videos of todays experts singing the praises of iostreams I would have ;-)
There are situations where use of C++ in an existing code base makes sense. For example, if the GCC project is offered a new optimization phase written in C++, then the code will presumably have been structured to make use of the high level C++ code structuring features. There is no reason to turn this code down or request that it be rewritten just because it happens to be in C++.
GCC moves to attract more developers
The GCC steering committee have just approved the use of C++ in GCC (I assume they are using GCC here to refer to gcc, not the Gnu Compiler Collection). On purely technical grounds it does not make much sense to allow developers to start adding C++ constructs to a large, established C code base, in fact I can think of some good reasons why this is a poor decision technically, but I don’t think this decision was based on technical issues.
Software is written by developers and developers have opinions (sometimes very strong ones) about which languages they are willing to use. Any project that relies on unpaid contributions (GCC does have a core of paid developers working on it) has to take developer language opinions into account. In fact even projects staffed purely by paid employees have to take language opinions into account; I was once heavily involved in the Pascal community and employers would tell me they had difficulty attracting staff because being seen as a Pascal developer would limit their future career prospects.
Over the years GCC has had a huge amount of input from various people’s PhD work. I suspect that today’s PhD graduate is much more likely to write in C++ than C and have little interest in a rewrite in C just to have it accepted into the gcc source tree.
What of up and coming developers interested in getting involved in a compiler project, are they willing to work in C? If they want to use C++ rather than C, then until Sunday the compiler project of choice for them would be LLVM.
The GCC steering committee have finally acknowledged that they need to allow the use of C++ in gcc if they are to attract a sufficient number of developers to work on it.
Recent Comments