Archive
CPUs also exhibit hardware faults
The cpu is the one element of a computing platform that people rarely treat as a source of error caused by physically malfunction, i.e., randomly flipping a bit in a register or instruction pipeline. I once worked on a compiler for the Mototola 88000 using a test platform that contained alpha silicon (i.e., not yet saleable components where some of the instructions were known not to work; the generated assembler code was piped through a sed script that mapped these instructions into an alternative instruction sequence that did work) and the cpus in a few of the hardware updates turned out to be temperature sensitive; some of the instructions changed their behavior when they got too hot. People who write compilers using alpha silicon learn to expect this sort of thing.
Quite a bit has been published on faults in other hardware components. Some of the best recent empirical hardware fault data and analysis I have seen is that published by Google engineers on hard disc and dram memory fault occurrences in their server farms. They might have a problem publishing such results for the cpus they use because these commodity items generally don’t have the ability to report any detailed fault data, they just die or one of the programs being executed crashes.
As device fabrication continues to shrink erroneous behavior caused by cosmic ray impact will become more and more common. Housing a computer farm at a high altitude might not be a good idea (at 7500 ft cosmic ray-induced neutrons that can lead to soft errors are 6.4 times more common than at sea level).
IBM’s Power4 chip (“Power4 System Design for High Reliability” by Bossen, Tendler and Reick) is one of the few that provides error checking of cache contents, while IBM’s System z9 is one of the very few that provide parity checking on the cpu registers (“Enhanced I/O subsystem recovery and availability on the IBM System z9” by Oakes et al).
One solution to the problem of unreliable cpu behavior is for the compiler to insert consistency checks into the generated code. Two such checking methods are:
- ‘Signature Analysis’ which performs consistency checks between signatures calculated at compile time and runtime. A signature is associated with every basic block with the current signature being derived from the execution history. This technique can detect spurious changes to the flow of control caused by a hardware glitch.
- ‘Error Detection by Duplicated Instructions’ generates code which duplicates the behavior of some instruction sequence and compares the result calculated by both sequences, i.e., a source language construct is executed twice and an error raised if the results are different. The parallel instruction sequences use different sets of registers on the same cpu and ideally the instructions are scheduled to exploit instruction level parallelism
At the moment cosmic-ray induced hardware faults are probably very small change compared to faults in the code. Will code quality increase to the point where cosmic-ray faults become an issue or will devices get so small that they have to be lead lined to prevent background radiation corrupting them? Let the race begin.
Estimating variance when measuring source
Yesterday I finally delivered a paper on if/switch usage measurements to the ACCU magazine editor and today I read about a switch statement usage that, if common, would invalidate a chunk of my results. Does anything jump out at you in the following snippet?
switch (x) { case 1: { z++; ... break; } ... |
Yes, those { } delimiting the case-labeled statement sequence. A quick check of my C source benchmarks showed this usage occurring in around 1% of case-labels. Panic over.
What is the statistical significance, i.e., variance, of that 1%? Have I simply measured an unrepresentative sample, what would be a representative sample and what would be the expected variance within a representative sample?
I am interested in commercial software development, and so I have selected half a dozen or so largish code bases as my source benchmark, preferably written in a commercial environment even if currently available as Open source. I would prefer this benchmark to be an order of magnitude larger, and perhaps I will get around to adding more programs soon.
My if/switch measurements were aimed at finding usage characteristics that varied between the two kinds of selection statements. One characteristic measured was the number of equality tests in the associated controlling expression. For instance, in:
if (x == 1 || x == 2) z--; else if (x == 3) z++; |
the first controlling expression contains two equality tests, and the second one equality test.
Plotting the percentage of equality tests that occur in the controlling expressions of if-if/if-else-if sequences and switch statements, we get the following:
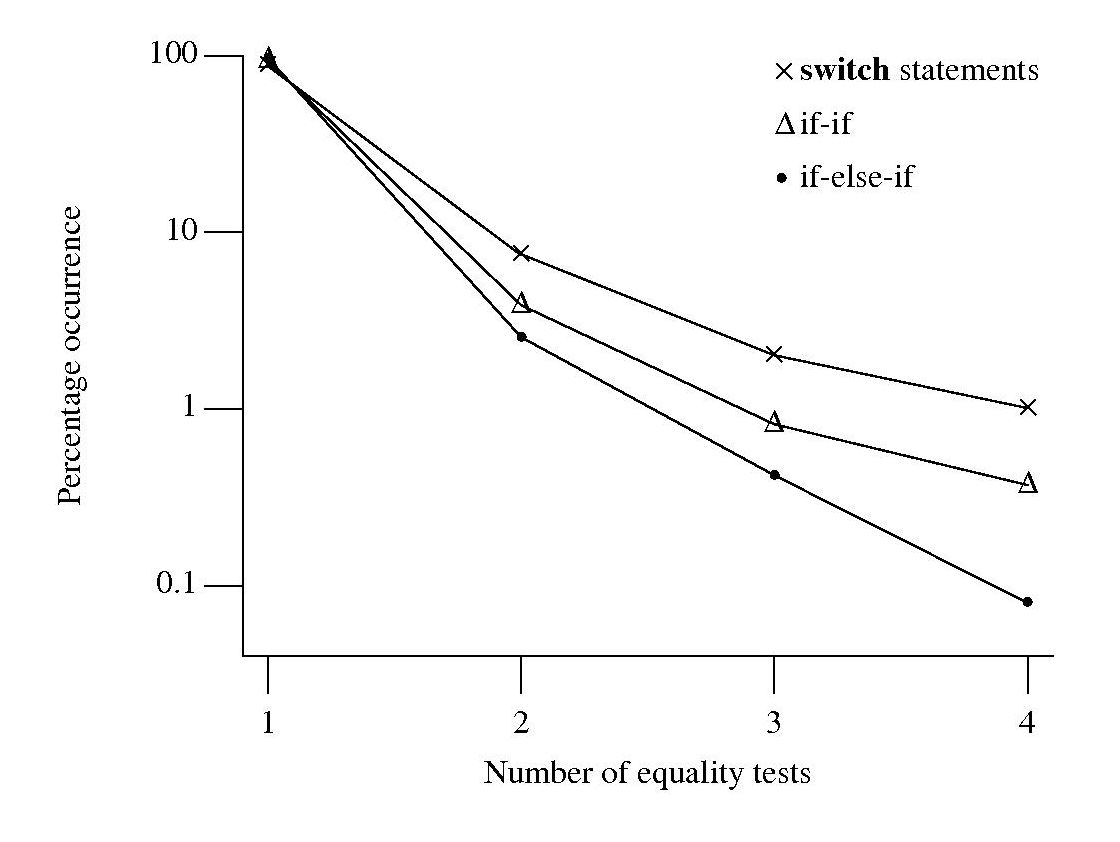
Do these results indicate that if-if/if-else-if sequences and switch statements differ in the number of equality tests contained in their controlling expressions? If I measured a completely different set of source code, would the results be very different?
To answer this question, a probability model is needed. Take as an example, the controlling expressions present in an if-if sequence. If each controlling expression is independent of the others, then the probability of two equality tests, for instance, occurring in any of these expressions is constant and thus given a large sample the distribution of two equality tests in the source has a binomial distribution. The same argument can be applied to other numbers of equality tests and other kinds of sequence.

For each measurement point in the above plot the associated error bars span the square-root of the variance of that point (assuming a binomial distribution, for a normal distribution the length of this span is known as the standard deviation). The error bars overlap, suggesting that the apparent difference in percentage of equality tests in each kind of sequence is not statistically significant.
The existence of some dependency between controlling expression equality tests would invalidate this simply analysis, or at least reduce its reliability. I did notice that in a sequence that containing two equality tests, the controlling expression that contained it tended to appear later in the sequence (the reverse of the example given above). Did I notice this because I tend to write this way? A question for another day.
Recent Comments