Archive
A fault in the C Standard or existing compilers?
Software is not the only entity that can contain faults. The requirements listed in a specification are usually considered to be correct, almost by definition. Of course the users of software implementing a specification may be unhappy with the behavior specified and wish that some alternative behavior occurred. A cut and dried fault occurs when two requirements conflict with each other.
The C Standard can be read as a specification for how C compilers should behave. Despite over 80 man years of effort and the continued scrutiny of developers over 20 years, faults continue to be uncovered. The latest potential fault (it is possible that the fault actually occurs in many existing compilers rather than the C Standard) was brought to my attention by Al Viro, one of the Sparse developers.
The issue involved the following code (which I believe the standard considers to be strictly conforming, but all the compilers I have tried disagree):
int (*f(int x))[sizeof x]; // A prototype declaration int (*g(int y))[sizeof y] // A function definition { return 0; } |
These function declarations are unusual in that their return type is a pointer to an array of integers, a type rarely encountered in this context (the original question involved a return type of pointer to function returning … and was more complicated).
The specific issue was the scope of the parameter (i.e., x and y), is the declaration still in scope at the point that the second occurrence of the identifier is encountered?
As a principle I think that the behavior, whatever it turns out to be, should be the same in both cases (neither the C standard or its rationale state such a principle).
Taking the function prototype case first:
The scope of the parameter x “… terminates at the end of the function declarator.” (sentence 409).
and does function prototype scope include the return type (the syntax calls the particular construct a declarator and there are at least two of them, one nested inside the other, in a function prototype declaration)?
Sentence 1592 says Yes, but sentence 279 and 1845 say No.
None of these references are normative references (standardize for definitive).
Moving on to the function definition case:
Where does the scope of the parameter x begin (sentence 418)?
“… scope that begins just after the completion of its declarator.”
and where does the scope end (sentence 408)?
“… which terminates at the end of the associated block.”
and what happens between the beginning and ending of the scope (sentence 412)?
“Within the inner scope, the identifier designates the entity declared in the inner scope;”
This looks very straight forward, there are no ‘gaps’ in the scope of the parameter definition appearing in a function definition. Consistency with the corresponding function prototype case requires that function declarator be interpreted to include the return type.
There is a related discussion involving a previous Defect Report 345 submitted a while ago.
The problem is that many existing compilers do not treat parameter scope in this way. They operate as-if there was a ‘gap’ in the parameter scope of function definition (probably because the code implementing this functionality is shared with that implementing function prototypes, which have been interpreted to not include the return type).
What happens next? Probably lots of discussion on the C Standard email reflector. Possible outcomes include somebody finding wording that requires a ‘gap’ in the scope of parameters in function definitions, it agreed that such a gap ought to be specified by the standard (because this is how existing code behaves because this is how compilers operate), or that the standard is correct as is and any compiler that behaves differently needs to be fixed.
Using local context to disambiguate source
Developers can often do a remarkably good job of figuring out what a snippet of code does without seeing (i.e., knowing anything about) most of the declarations of the identifiers involved. In a previous post I discussed how frequency of occurrence information could be used to help parse C without using a symbol table. Other information that could be used is the context in which particular identifiers occur. For instance, in:
f(x); y = (f)z; |
while the code f(x); is probably a function call, the use of f as the type in a cast means that f(x) is actually a definition an object x having type f.
A project investigating the analysis of partial Java programs uses this context information as its sole means of disambiguating Java source (while they do build a symbol table they do not analyze the source of any packages that might be imported). Compared to C Java parsers have it easy, but Java’s richer type system means that semantic analysis can be much more complicated.
On a set of benchmarks the researchers obtained a very reasonable 91.2% accuracy in deducing the type of identifiers.
There are other kinds of information that developers probably use to disambiguate source: the operation that the code is intended to perform and the identifier names. Figuring out the ‘high level’ operation that code performs is a very difficult problem, but the names of Java identifiers have been used to predict object lifetime and appear to be used to help deduce operator precedence. Parsing source by just looking at the identifiers (i.e., treating all punctuators and operators as whitespace) has been on my list of interesting project to do for some time, but projects that are likely to provide a more immediate interesting result keep getting in the way.
Measuring developer coding expertise
A common measure of developer experience is the number of years worked. The only good that can be said about this measure is that it is easy to calculate. Studies of experts in various fields have found that acquiring expertise requires a great deal of deliberate practice (10,000 hours is often quoted at the amount of practice put in by world class experts).
I think that coding expertise is acquired by reading and writing code, but I have little idea of the relative contributions made by reading and writing and whether reading the same code twice count twice or is there a law of diminishing returns on rereading code?
So how much code have developers read and written during their professional lives? Some projects have collected information on the number of ‘delivered’ lines of code written by developers over some time period. How many lines does a developer actually write for every line delivered (some functions may be rewritten several times while others may be deleted without every being making it into a final delivery)? Nobody knows. As for lines of code read, nobody has previously expressed an interest in collecting this kind of information.
Some experiments, involving professional developers, I have run take as their starting point that developer performance improves with practice. Needing some idea of the amount of practice my subjects have had reading and writing code I asked them to tell me how much code they think they have read and written, as well as the number of years they have worked professionally in software development.
The answers given by my subjects were not very convincing:
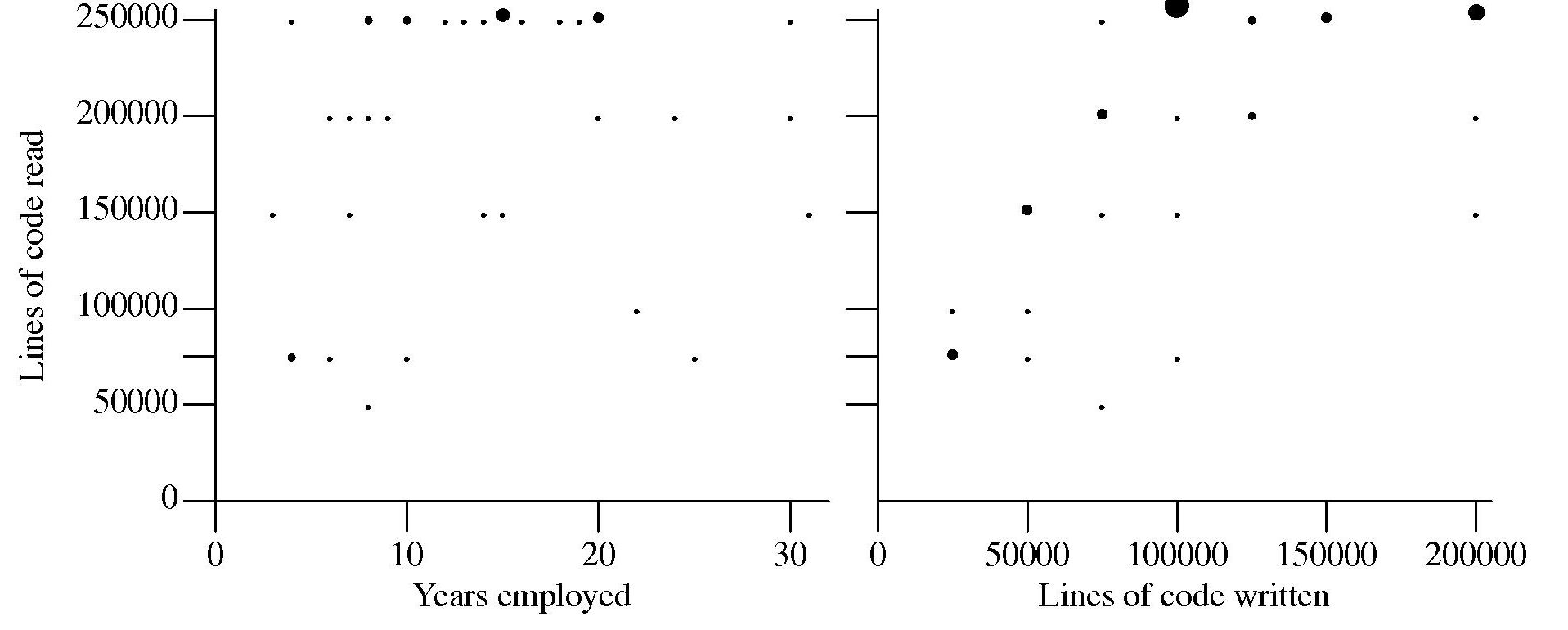
Estimates of the ratio code read/written varied by more than five to one (the above graph suffers from a saturation problem for lines of code read, I had not provided a tick box that was greater than 250,000). I cannot complain, my subjects volunteered part of their lunch time to take part in an experiment and were asked to answer these questions while being given instructions on what they were being asked to do during the experiment.
I have asked this read/written question a number of times and received answers that exhibit similar amounts of uncertainty and unlikeliness. Thinking about it I’m not sure that giving subjects more time to answer this question would improve the accuracy of the answers. Very few developers monitor their own performance. The only reliable way of answering this question is by monitoring developer’s eye movements as they interact with code for some significant duration of time (preferably weeks).
Unobtrusive eye trackers may not be sufficiently accurate to provide a line-of-code level of resolution and the more accurate head mounted trackers are a bit intrusive. But given their price more discussion on this topic is currently of little value 🙁
Using third party measurement data
Until today, to the best of my knowledge, all the source code analysis papers I have read were written by researchers who had control of the code analysis tools they used and had some form of localised access to the source. By control of the code analysis tools I mean that the researchers specified the tool options and had the ability to check the behavior of the tool, in many cases the source of the tool was available to them and often even written by them, and the localised access may have involved downloading lots of code from the web.
I have just been reading about a broad brush analysis of comment usage based on data provided by a commercial code repository that offers API access to some basic code metrics.
At first, I was very frustrated by the lack of depth to the analysis provided in the paper, but then I realised that the authors’ intent was to investigate a few broad ideas about comment usage in a large number of projects (around 10,000). The authors complained in their blog about some of the referees comments and having to submit a shorter paper. I can see where the referees are coming from, the papers are lacking in depth of analysis, but they do contain some interesting results.
I was very interested in Figure 2:
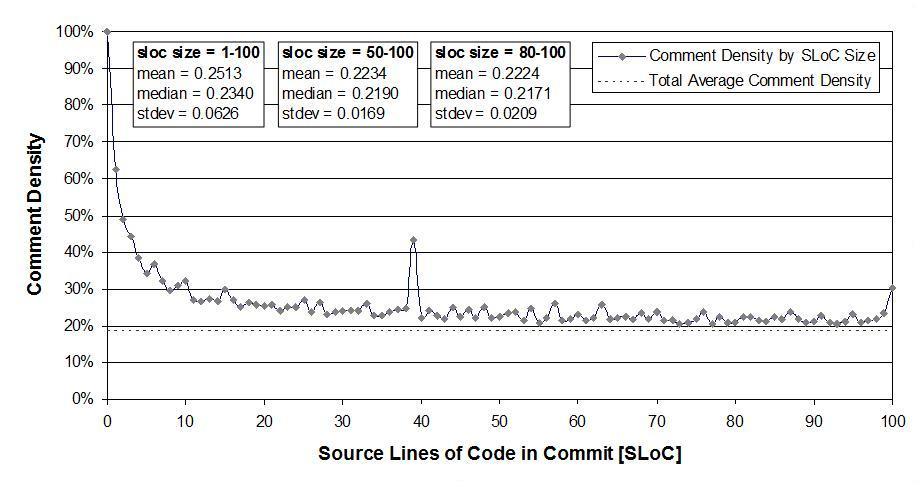
which plots the comment density of the lines in a source code commit. I would expect the ratio to be higher for small commits because a developer probably has a relatively fixed amount to say about updates involving a smallish number of lines (which probably fixes a problem). Larger commits are probably updated functionality and so would have a comment density similar to the ‘average’.
The problem with relying on third parties to supply the data is that obtaining the answers to follow up questions invariably involves lots of work, e.g., creating an environment to perform the measurements needed for the follow-up questions. However, the third party approach can significantly reduce the amount of work needed to get to a point where the interestingness of the results can be gauged.