Readability, an experimental view
Readability is an attribute that source code is often claimed to have, but what is it? While people are happy to use the term they have great difficulty in defining exactly what it is (I will eventually get around discussing my own own views in post). Ray Buse took a very simply approach to answering this question, he asked lots of people (to be exact 120 students) to rate short snippets of code and analysed the results. Like all good researchers he made his data available to others. This posting discusses my thoughts on the expected results and some analysis of the results.
The subjects were first, second, third year undergraduates and postgraduates. I would not expect first year students to know anything and for their results to be essentially random. Over the years, as they gain more experience, I would expect individual views on what constitutes readability to stabilize. The input from friends, teachers, books and web pages might be expected to create some degree of agreement between different students’ view of what constitutes readability. I’m not saying that this common view is correct or bears any relationship to views held by other groups of people, only that there might be some degree of convergence within a group of people studying together.
Readability is not something that students can be expected to have explicitly studied (I’m assuming that it plays an insignificant part in any course marks), so their knowledge of it is implicit. Some students will enjoy writing code and spends lots of time doing it while (many) others will not.
Separating out the data by year the results for first year students look like a normal distribution with a slight bulge on one side (created using plot(density(1_to_5_rating_data)) in R).
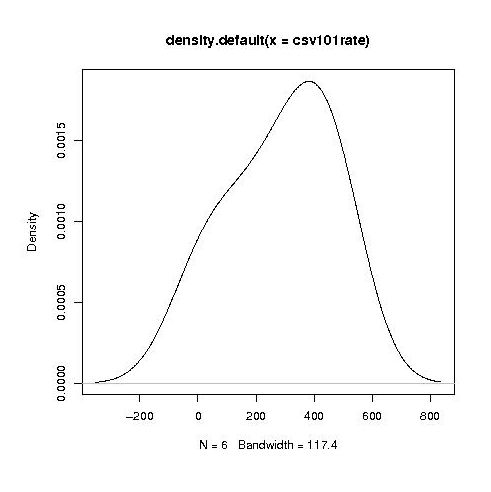
year by year this bulge turns (second year):
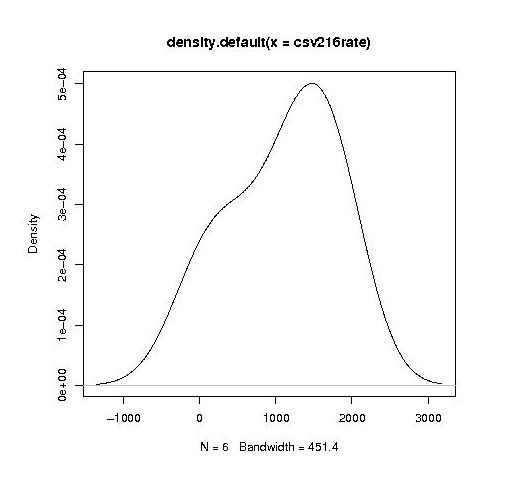
into a hillock (final year):
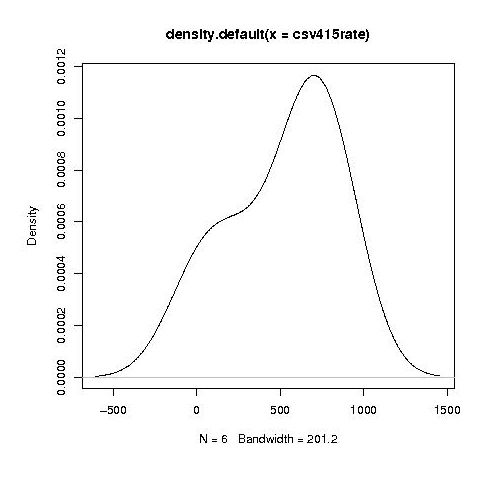
It is tempting to interpret these results as the majority of students assigning an essentially random rating, with a slight positive bias, for the readability of each snippet, with a growing number of more experienced students assigning less than average rating to some snippets.
Do the student’s view converge to a common opinion on readability? The answers appears to be No. An analysis of the final year data using Fleiss’s Kappa shows that there is virtually no agreement between students ratings. In fact every Interrater Reliability and Agreement function I tried said the same thing. Some cluster analysis might enable me to locate students holding similar views.
In an email exchange with Ray Buse I learned that the postgraduate students had a relatively wide range of computing expertise, so I did not analyse their results.
I wish I had thought of this approach to measuring readability. Its simplicity makes it amenable for use in a wide range of experimental situations. The one change I would make is that I would explicitly create the snippets to have certain properties, rather than randomly extracting them from existing source.
Recent Comments